



01 说明
1.1 逻辑和流程
简要流程:
- 获取指定区域指定时间范围的Sentinel-2影像并进行预处理
- 绘制并构建训练样本
- 训练随机森林分类器并分类
- 计算总体分类精度和混淆矩阵
ps: 提供JS版本和Python版本,但注意,无论是JS还是Python版本除了JS提供了GEE的Script 链接,直接给定的代码都是无法直接运行的,因为存在自定义创建的训练样本(需要自己手动在GEE的MAP上创建).同时geemap有创建训练样本的工具但是可能存在异常无法正常创建所有的训练样本或者零星地创建单一类样本(具体见: https://github.com/gee-community/geemap/issues/467)
1.2 数据集说明
使用的数据集为: Harmonized Sentinel-2 MSl:MultiSpectral Instrument, Level-2A (SR)(SR表示表面反射率即地表反射率, TOA版本为大气层顶反射率<包含大气层的影响>).
主要使用到的相关波段信息如下:
| 波段名称 | 描述 | 分辨率 | 比例系数 |
|---|---|---|---|
| B2 | Blue | 10 meters | 0.0001 |
| B3 | Green | 10 meters | 0.0001 |
| B4 | Red | 10 meters | 0.0001 |
其中,比例系数0.0001与像元DN值相乘即可得到真正的Sentinel-2表面反射率(原始值通过整数存储节省存储,通过0.0001缩放回来)
Sentinel-2中存在属性CLOUDY_PIXEL_PERCENTAGE表示影像的云覆盖率(单位为%)。
02 步骤和代码说明
2.1 创建训练样本
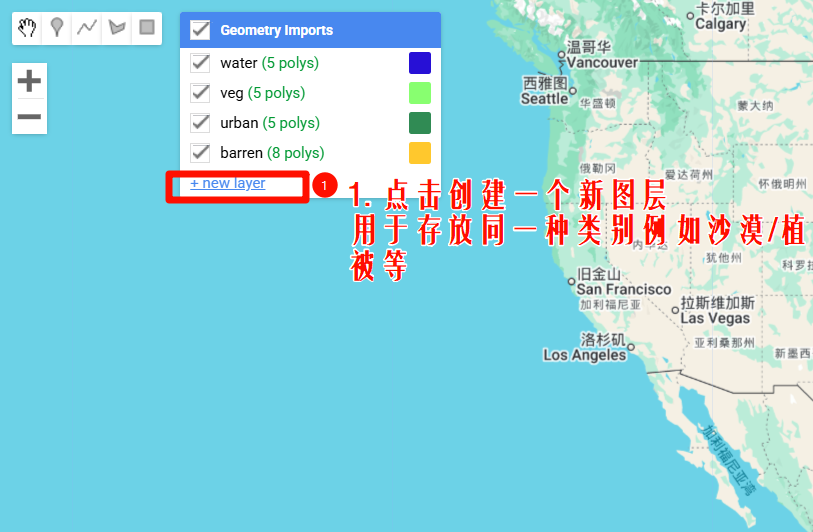
我们需要修改创建图层的数据类型,可创建的数据类型包括:
- Geometry
- Feature
- FeatureCollection
这里我们需要使用Feature和FeatureCollection数据类型存储你的训练样本.因为只有这两种数据类型才可以存储属性信息,而Geometry只能存储地理位置信息而没有办法存储属性信息(但是我们进行随机森林分类时是需要区分不同的类型,因此需要属性信息)。
对于大批量样本的创建,更推荐使用FeatureCollection数据类型.
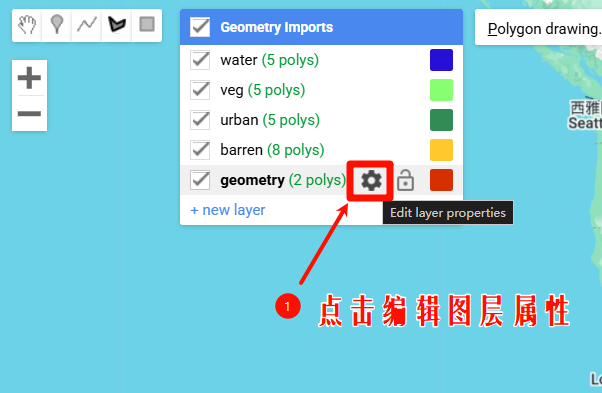
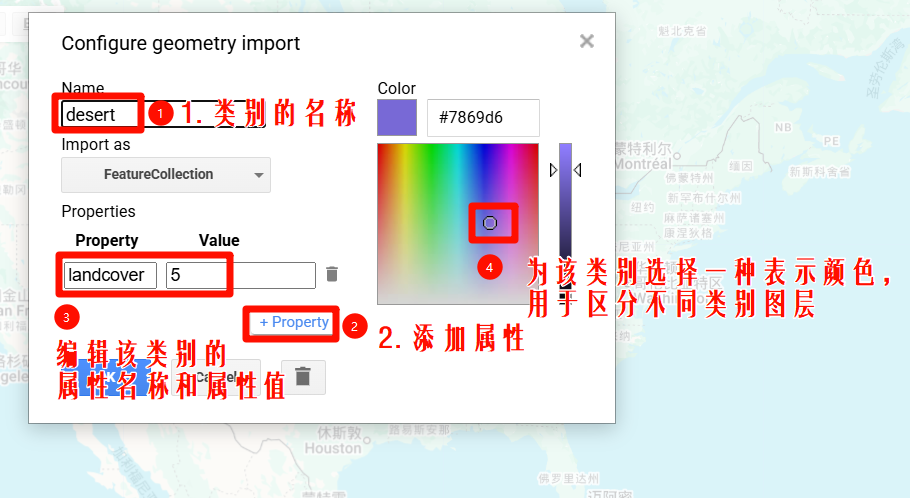
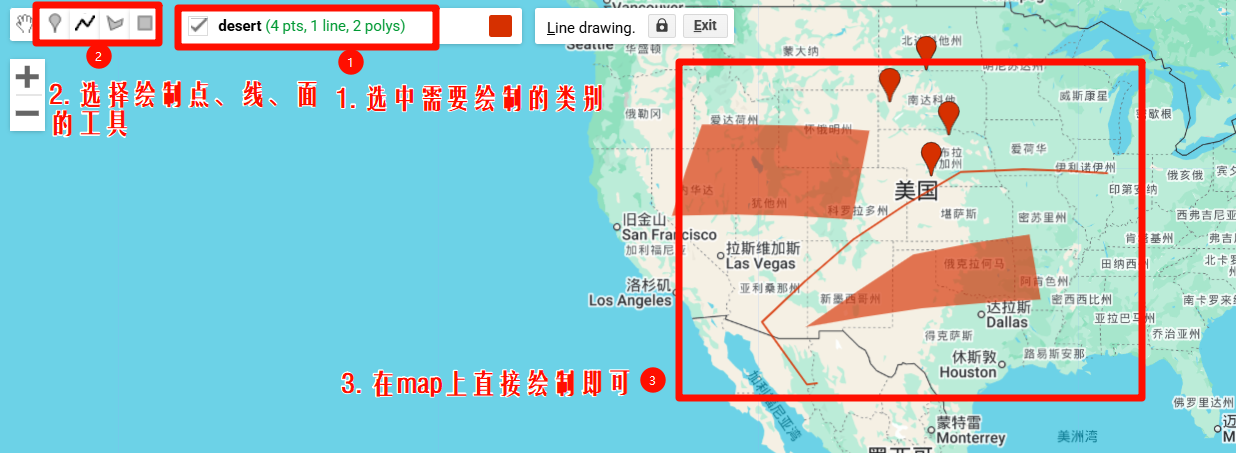
2.2 JS代码
JS链接: https://code.earthengine.google.com/06958df4e6a89f3c78d2e3af18133e14
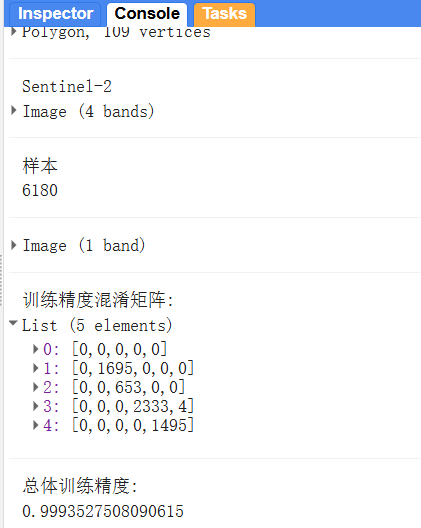
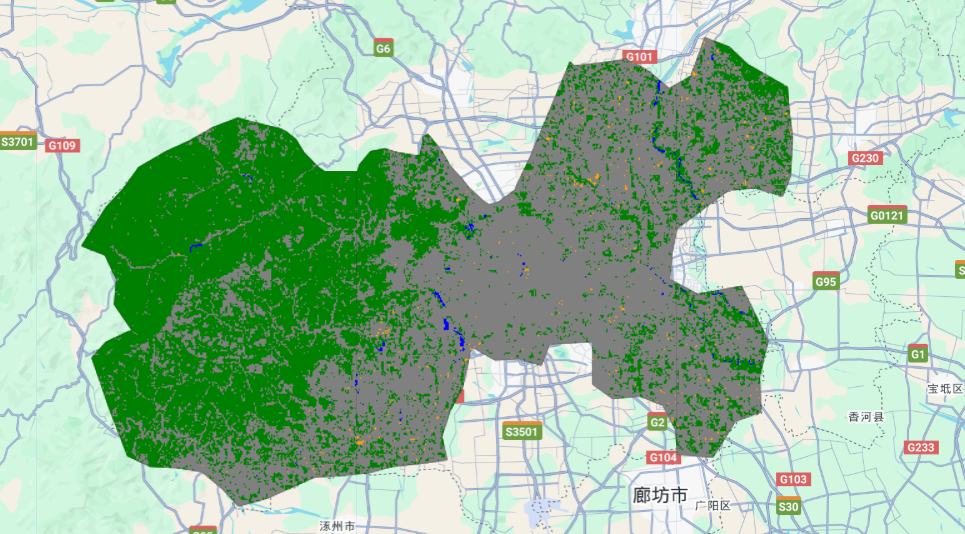
// // 用于检索(Inspector工具)北京市所在要素的属性 // var dataset = ee.FeatureCollection('FAO/GAUL_SIMPLIFIED_500m/2015/level2'); // Map.setCenter(116.5, 39.9, 8); // Map.addLayer(dataset, {}, 'boundary'); // 准备 var start_date = '2024-06-01' var end_date = '2024-08-31' var bands = ['B2', 'B3', 'B4', 'B8'] var roi = ee.FeatureCollection('FAO/GAUL_SIMPLIFIED_500m/2015/level2') // 获取北京边界 .filter(ee.Filter.eq('ADM1_NAME', 'Beijing Shi')) .first().geometry(); print('北京: ', roi); var vis_param_s2 = { 'bands': ['B4', 'B3', 'B2'], 'min': 0, 'max': 1, 'gamma': 1.4 }; var vis_param_class = { 'min': 1, 'max': 4, 'palette': ['blue', 'green', 'gray', 'orange'] }; // 获取Sentinel-2 2024年夏季的影像 var img = ee.ImageCollection("COPERNICUS/S2_SR_HARMONIZED") .filterBounds(roi) .filterDate(start_date, end_date) .filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 10)) .median() // 中值合成 .select(bands) // 红绿蓝+近红外波段 .clip(roi) // 裁剪 .multiply(0.0001); // 比例缩放 --> SR print('Sentinel-2', img); // 显示预处理好的影像 Map.addLayer(img, vis_param_s2, 'Sentinel-2 true color'); // 构建训练样本 var samples = water.merge(veg).merge(urban).merge(barren); Export.table.toAsset( samples, 'classification_samples', 'projects/ee-chaoqiezione1/assets/MyTemp/classification_samples' ); samples = img.sampleRegions({ collection: samples, properties: ['landcover'], // samples种保留的属性(默认所有非系统属性) scale: 10 // Sentinel-2的空间分辨率是10m }) print('样本', samples.size()); // 不要尝试打印样本, 样本量巨大会超出限制 // 基于随机森林训练 var classifier = ee.Classifier.smileRandomForest(50).train({ features: samples, classProperty: 'landcover', inputProperties: bands }); // 训练好分类器 // 分类 var class_img = img.classify(classifier); print(class_img) // 显示分类结果 Map.addLayer(class_img, vis_param_class, 'Classification') Map.centerObject(roi, 8) // 精度评估 var train_accuracy = classifier.confusionMatrix() // 混淆矩阵 print('训练精度混淆矩阵: ', train_accuracy) print('总体训练精度: ', train_accuracy.accuracy()) 对于输出的混淆矩阵, 输出见:
Computes a 2D confusion matrix for a classifier based on its training data (e.g., resubstitution error). Axis 0 of the matrix corresponds to the input classes and axis 1 corresponds to the output classes. The rows and columns start at class 0 and increase sequentially up to the maximum class value, so some rows or columns might be empty if the input classes aren't 0-based or sequential.
说明行表示实际的类别(真实的),列表示预测的类别。
输出结果:
2.3 Python代码
#%% md # 基于Sentinel-2影像的北京市监督分类与土地覆盖制图 #%% import ee import geemap ee.Initialize() Map = geemap.Map() Map #%% # 准备 start_date = '2024-06-01' end_date = '2024-08-31' bands = ['B8', 'B4', 'B3', 'B2'] roi = (ee.FeatureCollection('FAO/GAUL_SIMPLIFIED_500m/2015/level2') # 获取北京市边界 .filter(ee.Filter.eq('ADM1_NAME', 'Beijing Shi')) .first().geometry()) vis_param_s2 = { 'bands': ['B4', 'B3', 'B2'], 'min': 0, 'max': 1, 'gamma': 1.4 } vis_param_class = { 'min': 1, 'max': 4, 'palette': ['blue', 'green', 'gray', 'orange'] } #%% # 预处理sentinel-2影像 img = (ee.ImageCollection("COPERNICUS/S2_SR_HARMONIZED") .filterBounds(roi) # 只提取过境Sentinel-2的影像 .filterDate(start_date, end_date) # 只提取2024年夏季的Sentinel-2影像 .filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 10)) # 只提取云覆盖率小于10%的影像 .select(['B8', 'B5', 'B4', 'B3', 'B2']) .median() # 中位数合成 .clip(roi) # 裁剪掩膜 .multiply(0.0001)) # 比例缩放回地表反射率 Map.addLayer(img, vis_param_s2, 'Sentinel-2') Map #%% # 构建训练样本(由于geemap创建训练样本存在问题: 创建的样本可能存在不全,因此这里直接调用gee上创建好的训练样本<存在放在Asset上>) samples = ee.FeatureCollection('projects/ee-chaoqiezione1/assets/MyTemp/classification_samples') samples = img.sampleRegions(collection=samples, properties=['landcover'], scale=10) #%% # 创建随机森立训练器 classifier = ee.Classifier.smileRandomForest(50).train( features=samples, # 训练样本 classProperty='landcover', # 分类的属性 inputProperties=bands # 输入给分类器训练的特征属性 ) #%% # 分类 img_class = img.classify(classifier) Map.addLayer(img_class, vis_param_class, 'Classification') Map.centerObject(roi, 9) Map #%% # 分类精度 print('训练精度混淆矩阵: ') from pprint import pprint pprint(classifier.confusionMatrix().getInfo()) print('总体训练精度: {:.2%}'.format(classifier.confusionMatrix().accuracy().getInfo())) 输出结果:
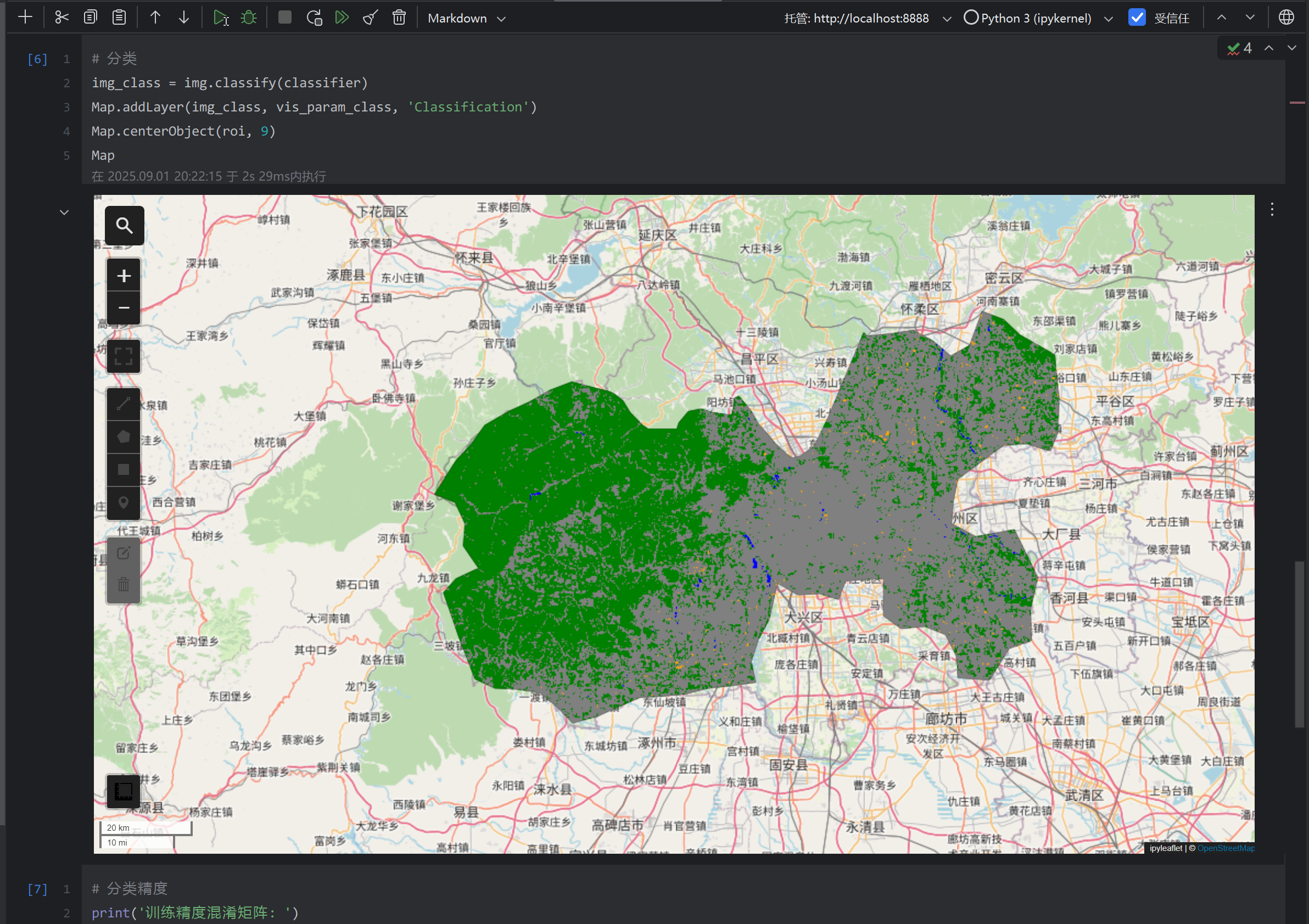
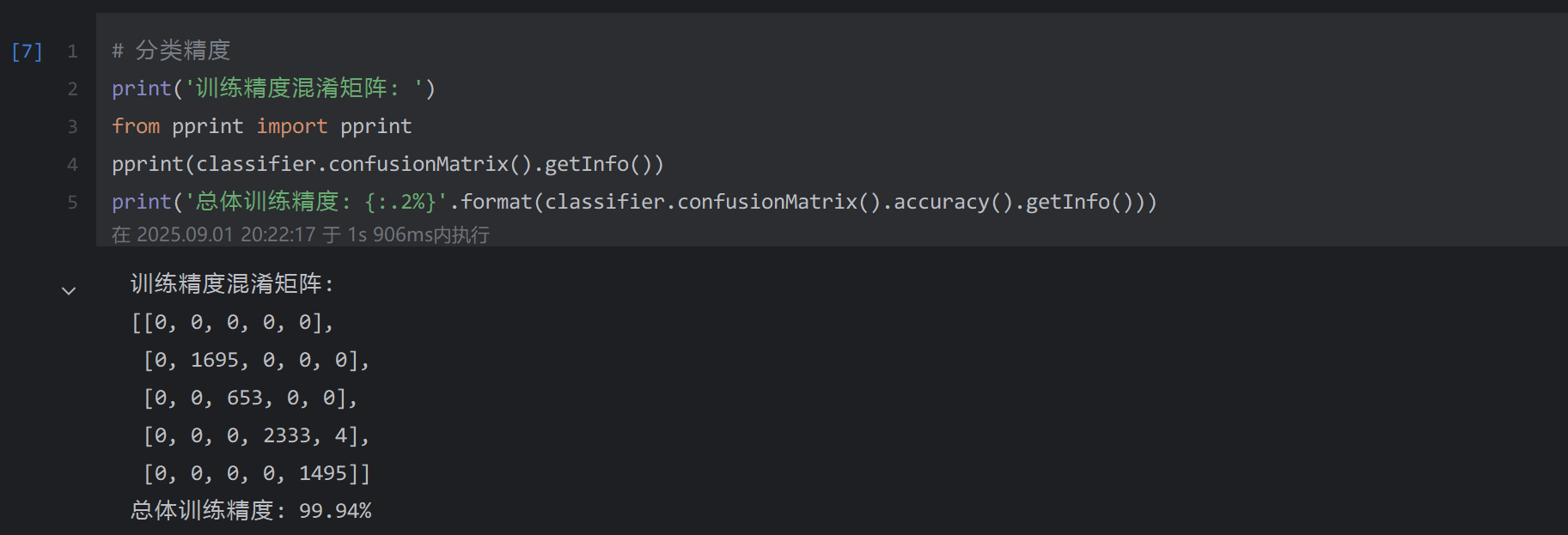

















这一切,似未曾拥有