


序言
当初在TX做Gerzi,给其他部门做测试,接触了Prometheus+grafana的监控系统。那可真是一段痛苦的服务日子啊。虽说难以解构实际的技术栈,但是这个监控系统给我留下了不少印象,现在就进行一下重现。
以下内容主要分为几个部分:
- prometheus安装部署
- Grafana安装应用
- Exporter指标数据收集
- PromQL
- Grafana中dashboard
- 告警和通知
简单来说,这套监控系统就是通过Exporter来进行对应后台系统或者微服务系统进行指标数据收集,然后汇集到Prometheus这个基于时序数据库的开源工具中,而后通过Grafana工具进行可视化展示。需要说一下的是Prometheus的原作者是Matt T.Proud,可以的话可以去观摩一下。
prometheus安装部署
Prometheus是SoundCloud这个在线音乐分享平台进行开发的,官方博客中针对这个监控系统Prometheus有文章Prometheus: Monitoring at SoundCloud,这篇文章里介绍了它们所需要的监控系统需要满足的特性(也就是Prometheus会满足的):
- 多维度数据模型
- 方便的部署和维护
- 灵活的数据采集
- 强大的语言查询
用户可以根据个人使用体验来判断这些条件是否满足,如果不满足可以考虑给他们提意见或者自己搞一个,或许你就是明日之星呢。Prometheus作为监控系统的一部分,它更是一个时序数据库。针对Prometheus的目标数据(目标service)采集,往往采取在目标service处开放一个Http接口来直接供给Prometheus,或者使用一个Exporter(数据采集组件)来进行目标service的数据采集,再对Prometheus提供一个Http接口来进行数据汇总(听说Prometheus使用Pull来进行数据采集,而不是Push)。
解压安装
回归正题,下面来进行Prometheus的安装部署,首先是在个人的ubuntu中进行直接安装,这种安装方式是下载压缩包到本地进行安装,比较传统:
# 在https://prometheus.io/download/官网中有着对应安装包,选择合适的进行wget到本地即可 $ wget https://github.com/prometheus/prometheus/releases/download/v3.5.0/prometheus-3.5.0.linux-amd64.tar.gz $ tar -xvfz prometheus-3.5.0.linux-amd64.tar.gz $ cd prometheus-3.5.0.linux-amd64 $ ./prometheus --version prometheus, version 3.5.0 prometheus的运行,编写其路径下prometheus.yml如下:
# 全局配置 global: scrape_interval: 15s # 抓取监控数据的时间间隔 # 单独的任务配置,可以设置多个 scrape_configs: - job_name: 'prometheus' # 任务名 # 隔5s进行一次目标数据的获取 scrape_interval: 5s # 具体抓取目标url,这是自己吃自己的意思 # 实际上是从http://localhost:9090/metrics获取指标数据,curl一下就知道了 static_configs: - targets: ['localhost:9090']
prometheus配置主要是global全局配置项、alerting通知配置项、rule_files报警规则配置项和最后的scrape_config指标数据收集任务配置项。
保存好以后运行即可:
$ ./prometheus --config.file=prometheus.yml 到了这一步,prometheus就算可用了,不过为了方便,还是需要进行一下调整,随个人喜欢移动prometheus路径到share或者local都可以,然后添加其prometheus的可执行文件路径到环境变量中即可。
docker部署
对于现在来说,其实更多还是应用prometheus到docker中,为了方便docker使用,在拉取prometheus的镜像前,需要先安装了docker:
$ apt install docker.io 这之后就可以进行正常的镜像获取和应用了:
$ docker run \ --name prometheus-service \ -p 9090:9090 \ -v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml \ -d prom/prometheus 特定路径编辑好配置yml以后如上进行挂载应用,docker run初次执行就会自动获取对应镜像了,-v参数是把本地/path/to/prometheus.yml挂载到运行起来的prometheus容器中的/etc/prometheus/prometheus.yml;-p参数则是端口挂载,比较简单。
除了上面参数,还有着其他的docker参数应用可以参考这篇:
docker命令参数
上面的运行结果就是,Prometheus通过自己暴露的metrics接口进行自我数据收集,当真是自己吃自己了,想要查看这些数据,如下:
$ $ curl http://localhost:9090/metrics # HELP go_gc_cycles_automatic_gc_cycles_total Count of completed GC cycles generated by the Go runtime. Sourced from /gc/cycles/automatic:gc-cycles. # TYPE go_gc_cycles_automatic_gc_cycles_total counter go_gc_cycles_automatic_gc_cycles_total 6 # HELP go_gc_cycles_forced_gc_cycles_total Count of completed GC cycles forced by the application. Sourced from /gc/cycles/forced:gc-cycles. # TYPE go_gc_cycles_forced_gc_cycles_total counter go_gc_cycles_forced_gc_cycles_total 0 # HELP go_gc_cycles_total_gc_cycles_total Count of all completed GC cycles. Sourced from /gc/cycles/total:gc-cycles. # TYPE go_gc_cycles_total_gc_cycles_total counter go_gc_cycles_total_gc_cycles_total 6 # HELP go_gc_duration_seconds A summary of the wall-time pause (stop-the-world) duration in garbage collection cycles. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 6.6802e-05 ... prometheus安装部署完毕后,就可以通过web进行简单访问了,直接访问http://localhost:9090/就可以得到如下页面,这里采取的是ubuntu进行部署,同一局域网下windows进行编辑访问,所以:
如上为默认跳转的查询页面,在这里可以通过提供的Status页面查看数据采集方(各种exporter或者直接后台)的状态的Target health,但是这里不关注这些,这里只关注Graph页面提供的强大查询功能,通过特殊表达式来对监控数据进行查询,这个表达式就是PromQL。目前还不算正式应用,姑且搁置一下。
Grafana安装部署
和prometheus一样,Grafana同样有着两种部署方式,第一种就是本地安装了:
# 安装基本工具,如果已经有了wget可以忽略 $ sudo apt-get install -y apt-transport-https software-properties-common wget # 添加gpg密钥 $ sudo mkdir -p /etc/apt/keyrings/ $ wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null # 添加respository $ echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list # 更新一下源然后安装 $ sudo apt update $ sudo apt install grafana 另外的部署方式就是docker部署了,如下:
$ docker run -d \ --name grafana-service \ -p 3000:3000 grafana/grafana 简单粗暴,如此运行起来后,直接访问http://localhost:3000/,上来就是Grafana登录页面:
默认登录为admin/admin,成功以后就会要求设置初始管理员密码,完了以后就可以进去了,到这里,grafana服务算是起来了,但却还不算用起来,因为它还么设置prometheus数据源,只是一个提供web页面的空的grafana服务。下面设置一下数据源,搜索[Data sources]进入[Data sources]页面,然后在这里可以进行[Add data source]操作,不过现在grafana并不止于Prometheus这一数据源,点击后会发现有很多可选项,不过这里还是采用的prometheus:
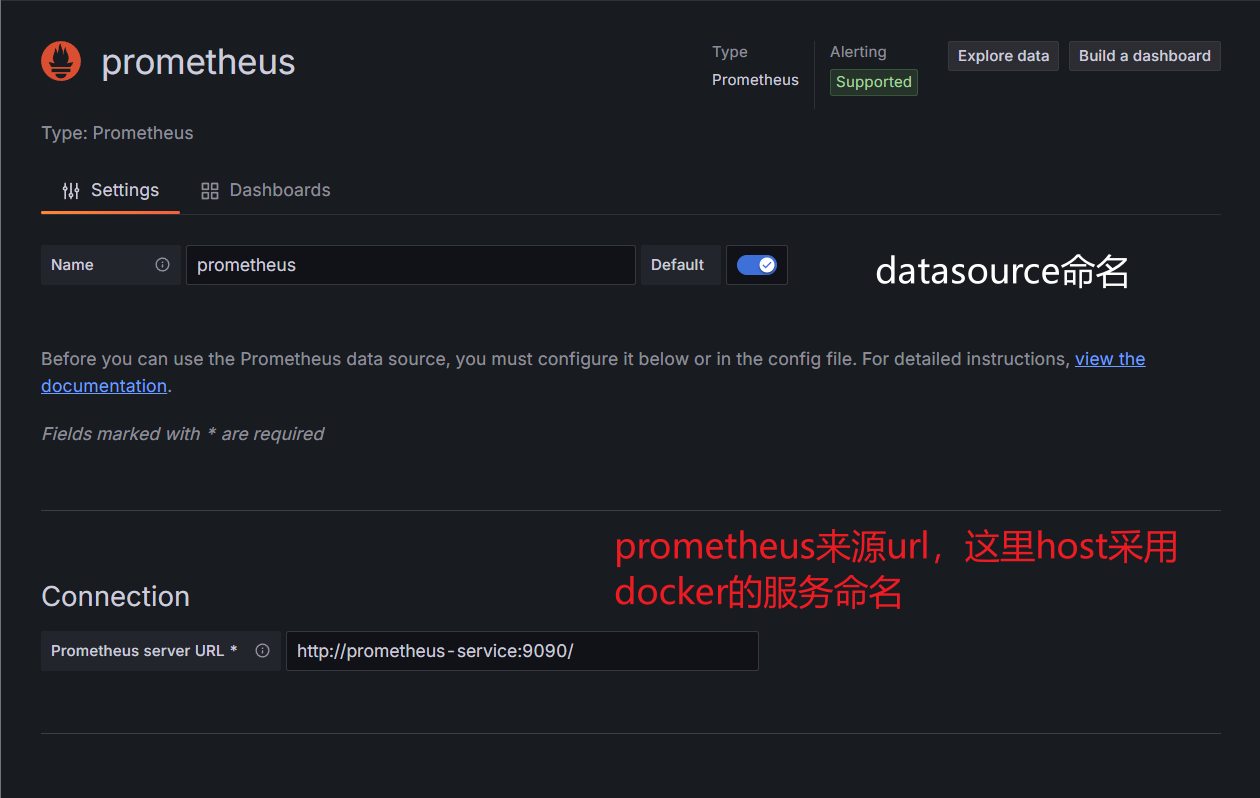
如上进行设置也是够了的,更多的就看个人对于prometheus是否有更多的私密设置之类的了,这时候才需要在上面配置上进行添加,比如添加了用户cookie的metrics接口。
添加完数据源以后,还需要定制一下dashboards,也就是数据格式json的引入,这个搁在后面数据Exporter一起谈。
实操碰到的小问题
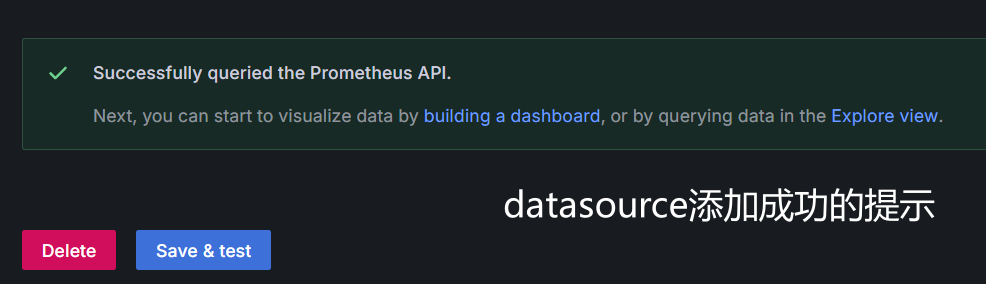
在实际应用中,本来因为本地测试prometheus采用curl本地localhost得以成功,象征性完成联通测试了,但在grafana数据源中采取localhost作为数据源host,则是会出现连通性问题。为了解决这个问题,需要将这两个service置于同一个docker网段中:
# 创建一个test-net的docker网段 $ docker network create test-net # 将这两个servcice添加到test-net网段中 $ docker network connect test-net prometheus-service $ docker network connect test-net grafana-service 这样一来,在grafana-service中就可以利用prometheus-service来对这service进行访问了,不然就只能通过其分配的docker ip进行访问了,到这之后,前面的grafana数据源的设置就能正常进行了,会有如下结果:
Exporter数据收集
到这里,只是确定了数据统一的prometheus和数据可视化grafana的简单应用,尚未投入实际的项目监控中,这里就针对项目中常用的CPU负载、内存占用、IO开销、流量统计等。这类向Prometheus提供监控样本数据的Exporter,Prometheus会定期向Exporter轮询监控数据,通过Exporter暴露的metrics接口。
针对这类指标收集,就需要特殊的Exporter来进行,关于Exporter的列表可以在prometheus官网中进行查看,根据自己需要进行选择:
Exporter列表
从这上面,可以找到各种官方提供的关于Database数据库、Hardware硬件、Storage存储、Messages System消息队列、HTTP服务、API服务、logging日志、另外的监控系统等等常用的一些个常见的也是比较常用的相关Exporter,另外还有着其他针对特定语言的支持,比如对于Golang、python等等,使其可以在对应代码项目中实现metrics接口,如此操作,项目也就无需另外的Exporter,但也给项目增添了额外的负担。
回归正题,下面使用基础的node-exporter来作为Exporter进行系统层面的数据收集,基本的本地部署当然是:
# node-exporter的github仓库中选择对应系统安装包进行wget # 会用到科学,不然真难搞 $ wget https://github.com/prometheus/node_exporter/releases/download/v1.9.1/node_exporter-1.9.1.linux-amd64.tar.gz # 解压 $ tar xvfz node_exporter-1.9.1.linux-amd64.tar.gz $ cd node_exporter-1.9.1.linux-amd64 # 运行 $ ./node_exporter 运行起来后就可以通过curl http://localhost:9100/metrics获取本地指标数据了,另外还有docker的部署方式:
$ docker run -d \ --net test-net \ -p 9100:9100 \ --name node-exporter \ prom/node-exporter 如上操作,运行node-exporter的时候添加进test-net的docker网段中,这样prometheus-service才能正常通过host来获取其信息,如上操作后,还需要修改一下prometheus-service的yml文件更改一下target信息,更改完成后还需要重启一下使其生效:
scrape_configs: - job_name: 'node' scrape_interval: 5s static_configs: - targets: ['node-exporter:9100'] 重启一下:
$ docker restart prometheus-service PromQL小解
上面Prometheus重启完成后就可以在其web中可以对其进行数据查询:
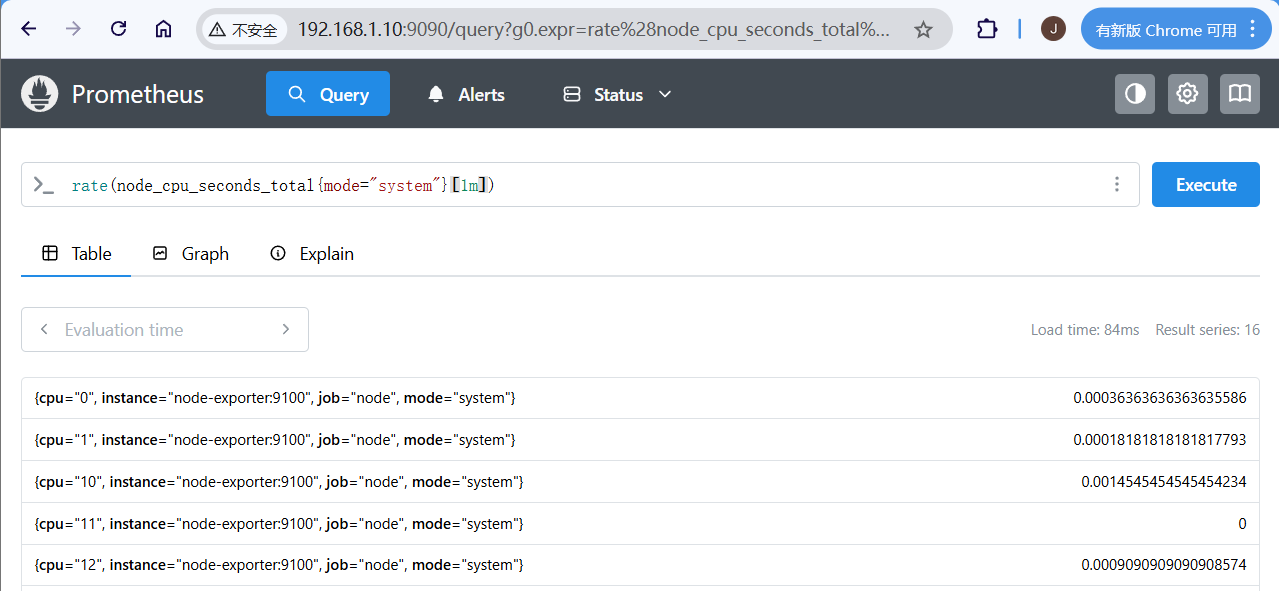
如上就是在Prometheus中进行PromQL查询的结果。作为Prometheus的核心功能,PromQL支持用户进行监控样本数据的统计分析,同时告警监控也是依赖于PromQL进行实现。
Prometheus支持四种数据类型:
- 瞬时向量(Instant vector)
- 区间向量(Range vector)
- 标量数据(Scalar),浮点数
- (String),字符串,待用
解析一下,重点关注Instant vector和Range vector,后者是多个时序序列,每个序列都是一个Instant vector,下面针对瞬时向量进行查询:
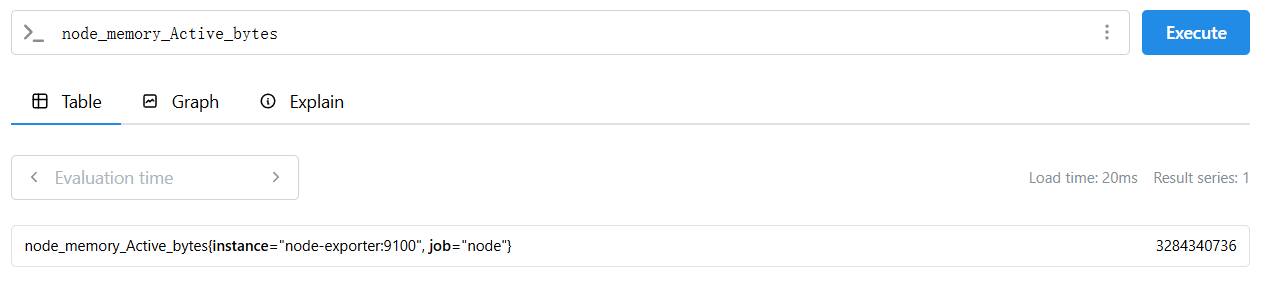
如上,输入指标名称,即可获取对应瞬时向量数据,这是node-exporter中定义的标签数据,那么范围内多时序呢?添加上一个时间范围即可:
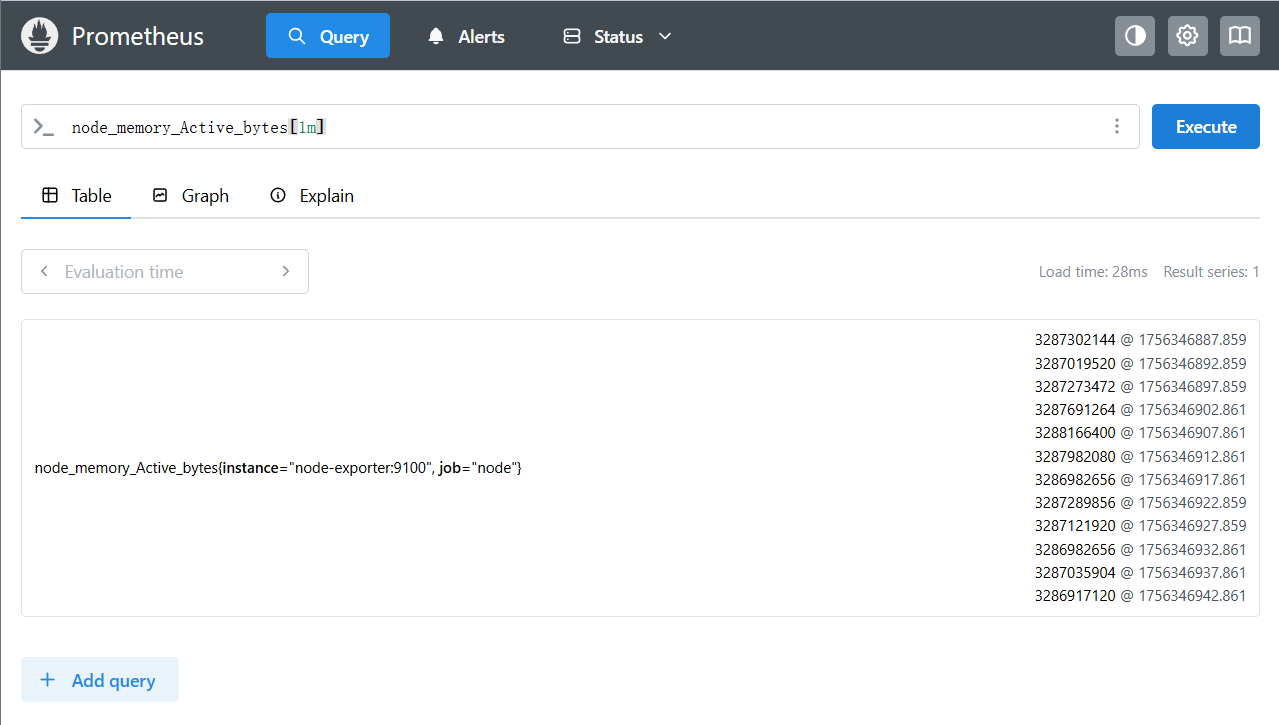
上面查询的数据为1m内也就是一分钟内的数据,因为Prometheus配置的scrape_interval为5s,所以共计12条数据,这就是区间数据了。类型数据是这样,除此以外,PromQL还有着各种函数支持,这里就不加赘言了,毕竟只是要最后在Grafana的可视乎。
打造自己的Exporter
因为是在项目中引入,所以下面重点关注如何打造项目需要的自定义Exporter。Exporter和Prometheus间前者暴露metrics接口,后者进行轮询从而收集监控数据,因此Exporter要实现数据的收集和转化。指标数据常见格式如下:
http_req_duration_sec_bucket{le="0.2"} 150 http_req_duration_sec_bucket{le="0.5"} 200 采用度量名称{标签名='标签值1',...} 值 时间戳的格式,如上为http_req_duration_sec_bucket的度量名的监控数据,le为标签名,0.2和0.5为标签值,150和200为确切的监控数据,这里数据忽略了时间戳。对于代码层面的调用,往往是定义四种prometheus-client库所提供的Counter计数器、Gauge变化度量、Histogram直方图、Summary摘要来进行指标数据项定义。Counter常用来记录递增指标,如请求数;Gauge记录可变化度量值,如CPU利用率;Histogram直方图记录样本分布,如请求延迟;Summary概要则是类似Histogram,也记录样本分布情况,但展示更多的统计信息,诸如数量、总和、平均值等。
项目代码实现对应的指标数据,并进行记录,最后通过metrics接口暴露给Prometheus进行数据收集,整体流程就完成了。
Grafana dashboard数据样式
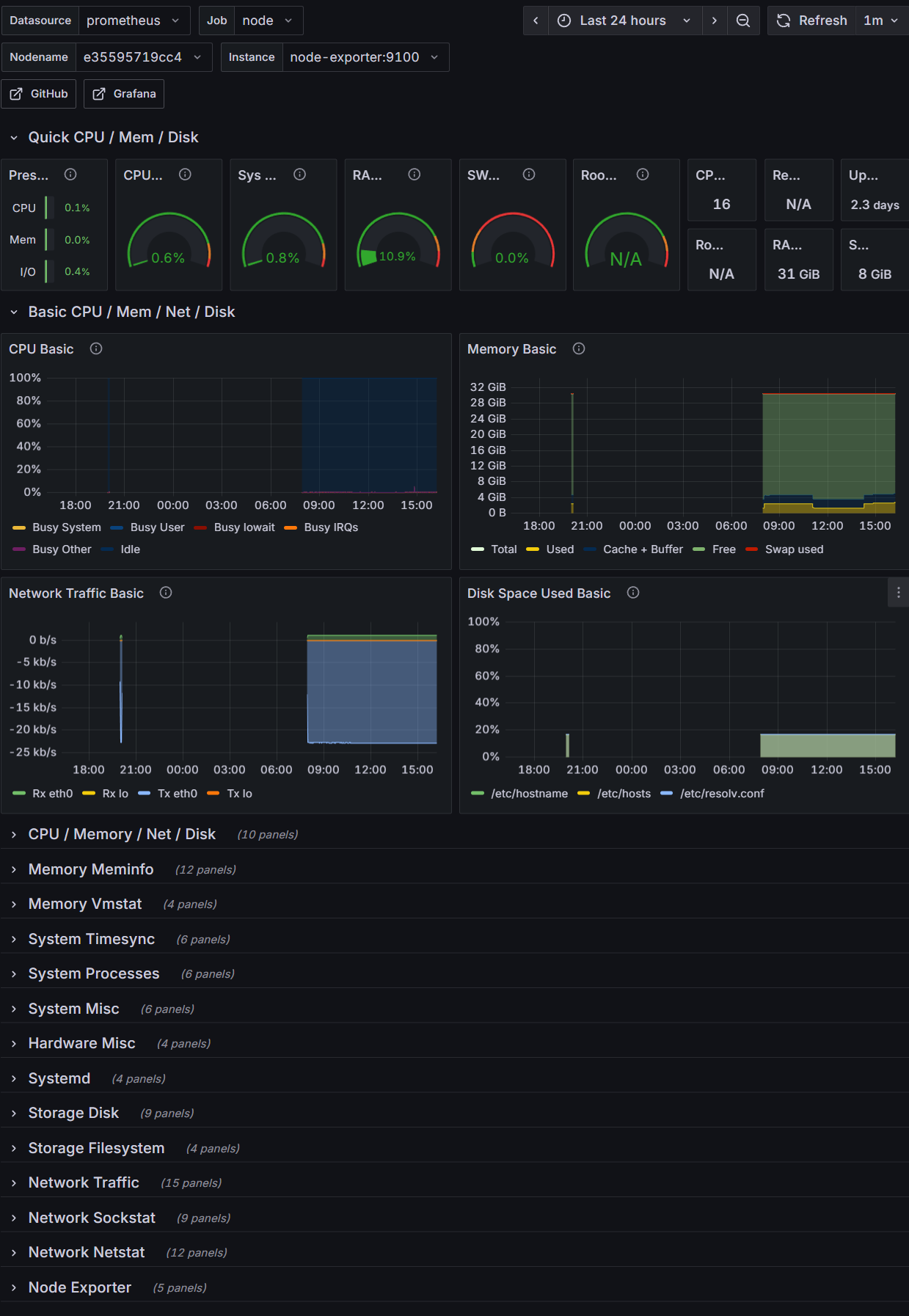
前面有进行数据收集和Prometheus中数据统计查询,但是还是没有实现最终需要的如图所示,没法向领导做汇报呢,所以需要在前面Grafana中继续进行数据展示样式的设置,也就是dashboard方面的设置。关于这个,grafana有着现成的展示板可以进行,只需要在grafana官网样板列表中进行特定选择,不过首先要配合对应的Exporter,比如前面的node-exporter,就可以选择这里的node-exporter-full的样板进行数据展示:
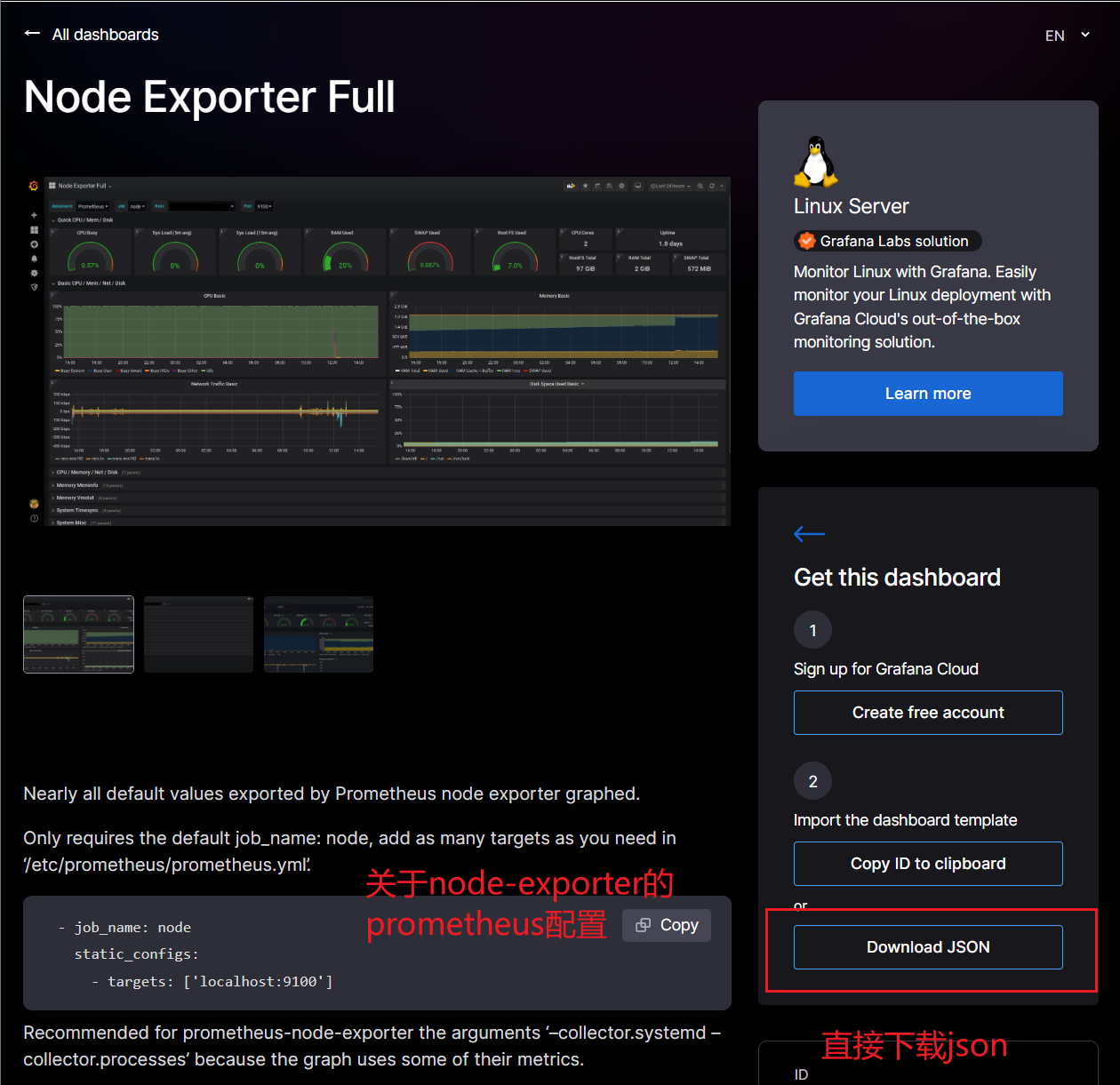
如上操作,然后在grafana-service的web页面进行上面下载的json导入即可:
操作完成后即可看到效果:
报警和通知
好的,进行到这里,监控系统就基本成型了,但是运维人员不可能随时盯着监控的,而且监控可视化在某种程度上,情况发生的时候前台看到已经晚了,所以还是需要后台进行直接告警和通知。
前面有过介绍,关于Prometheus配置中有着rule_files的配置可以进行告警方面的配置:
rule_files: - alerts.yml 而后直接整个alerts.yml:
# Prometheus报警规则配置 groups: # 系统资源报警规则 - name: system-alerts rules: # 系统CPU使用率过高 - alert: HighCPUUsage expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85 for: 5m labels: severity: warning annotations: summary: "系统CPU使用率过高" description: "系统CPU使用率为 {{ $value }}%,超过85%阈值" # 系统内存使用率过高 - alert: HighMemoryUsage expr: 100 * (1 - ((node_memory_MemAvailable_bytes) / (node_memory_MemTotal_bytes))) > 90 for: 3m labels: severity: critical annotations: summary: "系统内存使用率过高" description: "系统内存使用率为 {{ $value }}%,超过90%阈值" # 磁盘空间不足 - alert: DiskSpaceLow expr: 100 * (1 - ((node_filesystem_avail_bytes{mountpoint="/"}) / (node_filesystem_size_bytes{mountpoint="/"}))) > 85 for: 5m labels: severity: warning annotations: summary: "磁盘空间不足" description: "根分区磁盘使用率为 {{ $value }}%,超过85%阈值" 如上就是一个报警yml的配置了,如上针对node-exporter的监控数据进行设定的系统告警,设置了HighCPUUsage、HighMemoryUsage和DiskSpaceLow的三种情况和报警处理。
拿第一条alert来说,就是expr参数所设定的PromQL语句为临界条件,表示当5m内CPU使用率大于85%了,这条PromQL的思路是使用irate和avg函数结合查询到的5分钟内的一个node_cpu_seconds_total数据做一个平均得到CPU的空闲度(100为满),而后做差,就是现有CPU使用度了。
labels是自定义标签,在实际应用中,可以根据标签来进行报警情况级别分类,从而划分不同情况的处理,比如普通报警简单通知,宕机报警直接电话短信通知等;annotations就是报警的文本内容了,这个倒是很好理解。
综上来看,一份报警yml是很考究开发人员对系统的指标的了解程度和PromQL的应用熟悉程度的,都掌握的人才能应用自如。话不多说,搞定了yml配置后,因为引入了新的配置文件,所以重启没法解决问题:
# 删除原有 $ docker rm -f prometheus-service # 另起一份 $ docker run --name prometheus-service \ -p 9090:9090 \ -v ./prometheus.yml:/etc/prometheus/prometheus.yml \ -v ./alerts.yml:/etc/prometheus/alerts.yml \ -d prom/prometheus 执行完毕,查看prometheus-service的web页面上alerts部分,就可以看到:
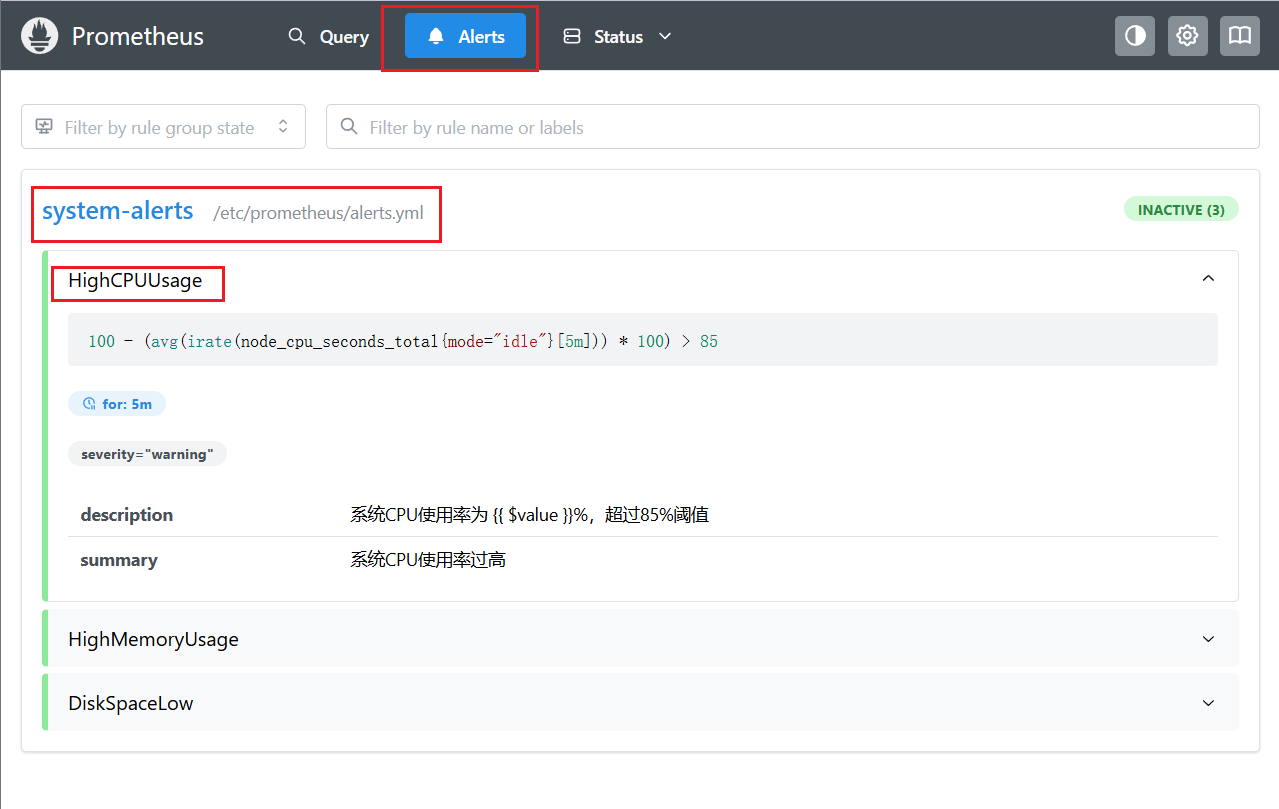
为了进行可行性检验,在上面rules中添加一条:
groups: - name: system-alerts rules: - alert: NodeExporterDown expr: up{job='node'} == 0 添加以后重启一下服务即可看到这条rule的生效了,另外手动停下node-exporter来检验它是否确切可行,这条PromQL语句主要是up函数查询job为node的状态,为0就表示挂了:
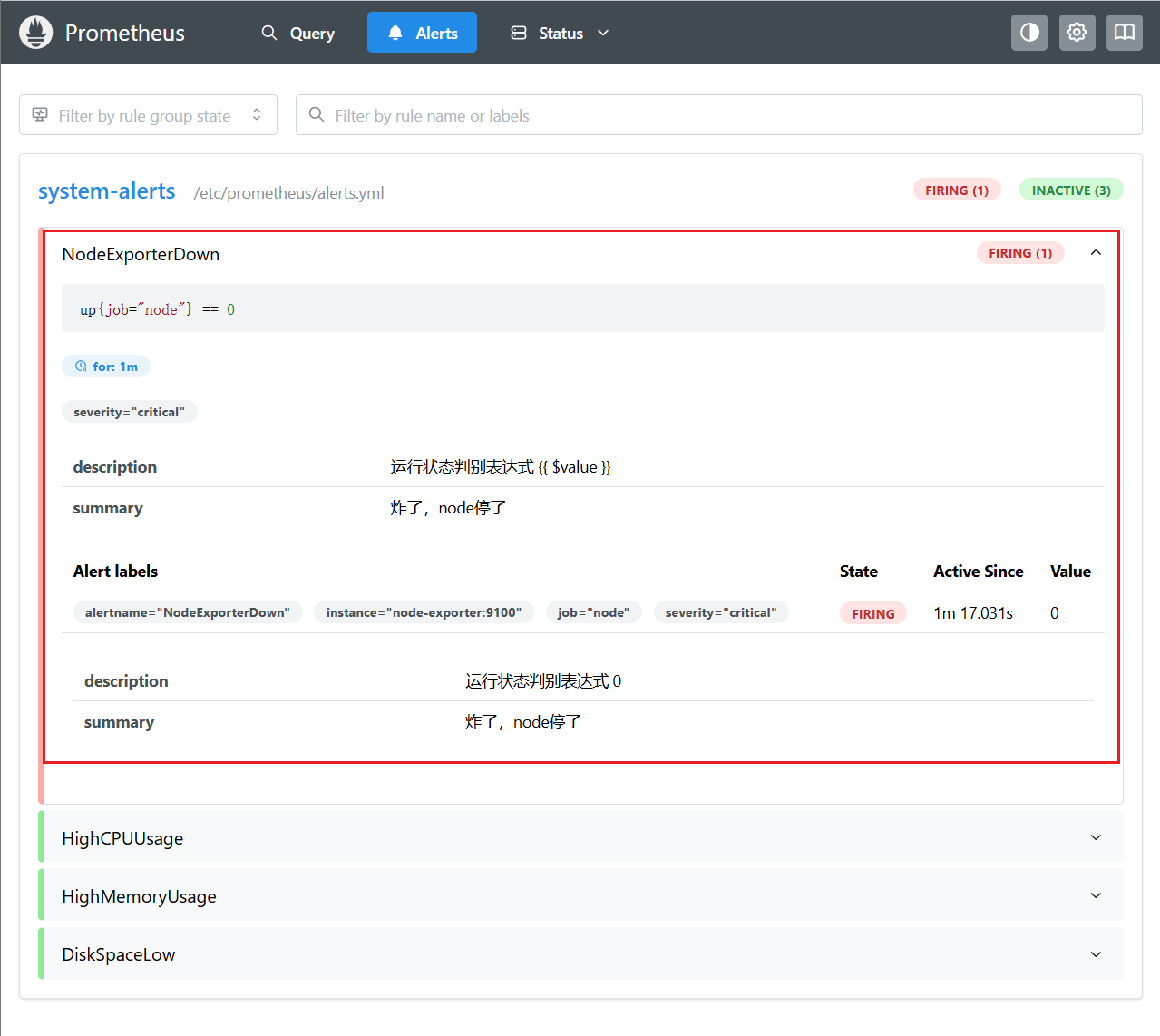
如上,根据条件语句检测得出node-exporter挂掉后立即更新状态为Firing,但有时候,这些个service是分布式部署在不同主机上的,如果因为网络波动,突然就报警,谁受得了?所以需要有持续时间的设定,当触发条件持续了一段时间后才发送报警信息,这也就是for参数的应用。
for参数表示从第一次alert情况被检测到后,Prometheus需要等待多久才进行实际报警,也就是大概多久才触发firing状态,否则会一直处于pending状态。
prometheus报警
上面说了,报警时为了不盯着监控系统,在有情况发生的时候马上收到通知是吧?好像上面还缺少了实际的通知功能的实现呢,这就需要用上alertmanager了,这是专门进行警报接收、聚合和用户通知用的。
先整下来镜像:
$ docker pull prom/alertmanager 而后配置一下prometheus-service,使其将报警推送到alertmanager上:
rule_files: - alerts.yml alerting: alertmanagers: - static_configs: - targets: - alert-manager:9093 如上,添加alerting为alert-manager服务,其对外端口为9093,针对alert-manager这一服务,也是需要配置的:
global: resolve_timeout: 5m smtp_smarthost: 'smtp.163.com:465' smtp_from: 'your_email.com' smtp_auth_username: 'your_email.com' smtp_auth_password: 'kdjslajlsdlfk' smtp_require_tls: false route: group_by: ['alertname', 'instance', 'severity'] group_wait: 10s group_interval: 1m repeat_interval: 15m receiver: 'mail' receivers: - name: 'mail' email_configs: - to: 'your_email.com' 这里采用的是网易163的smtp服务,使用比较简单,可以自行网上搜索网易163 开启smtp,获取其密钥存于上面smtp_auth_password参数即可,我上面是bullshit,不用在意,这里面是有不少坑的,要出慢活。
上面参数还是太简单的,就不一一说明了。搞定yml配置后,一键开启:
$ docker run -d \ --name alert-manager \ -p 9093:9093 \ -v ./alertmanager.yml:/etc/alertmanager/alertmanager.yml \ --network=test-net \ prom/alertmanager 拉起来以后,浏览器查看http://localhost:9093/如下:
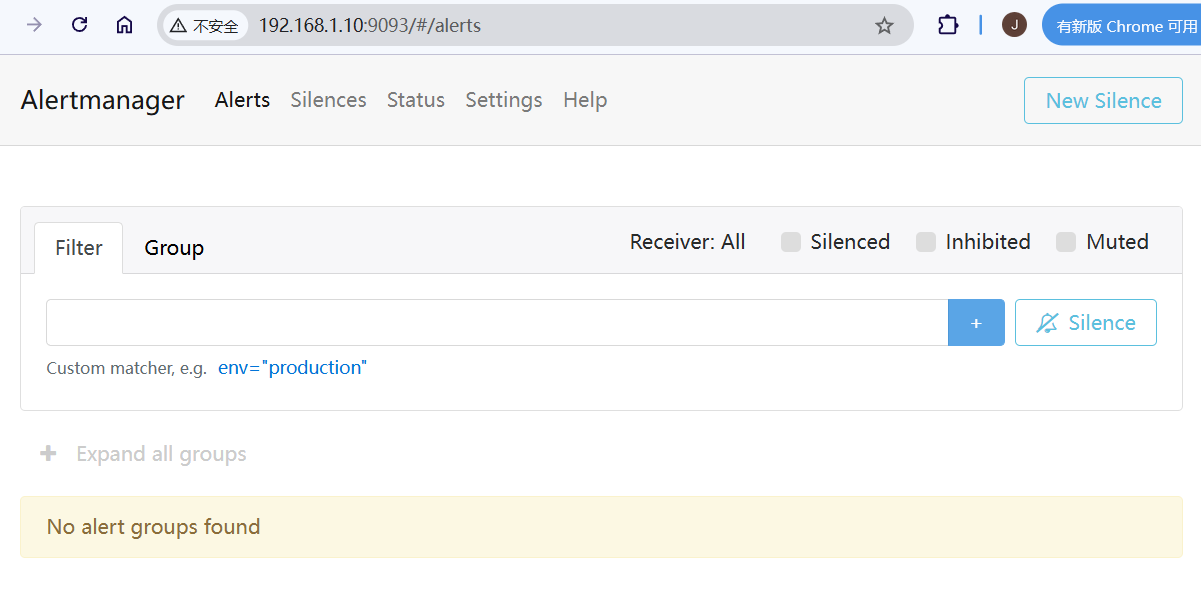
页面上Status可以查看到当前Config,通过这里可以查看对于alert-manager的配置文件是否挂载生效,而后可以进入到alert-manager和prometheus-service中使用nslookup来测试域名解析,连通性方面直接ping ip就好,完全莫问题的。
而后,不要忘记前面加了个NodeExporterDown的报警检测,所以拉起了alert-manager后,重走一遍流程,把node-exporter给挂掉,然后prometheus-service查看其alerts中对应NodeExporterDown是否已经进入pending,等待设定的1m到后,配置所设定的receivers所指邮箱是否收到对应报警邮件。
其实除了这样进行监控的报警,还可以利用Grafana进行报警的配置实现,简单来说,路子不止这一条。
总结
到这里了,可以总结一下了,到这为止,这套监控系统已经有prometheus、grafana、alertmanager和node-exporter四个service了,在实际中,并不需要一个一个地进行拉起和配置,毕竟现在都定型了,所以集成到一份docker-compose.yml:
networks: monitoring-net: name: monitoring-net driver: bridge attachable: true services: node-exporter: image: prom/node-exporter:latest container_name: node-exporter networks: - monitoring-net ports: - "9100:9100" prometheus: image: prom/prometheus:latest container_name: prometheus-service networks: - monitoring-net ports: - "9090:9090" volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml - ./alerts.yml:/etc/prometheus/alerts.yml grafana: image: grafana/grafana:latest container_name: grafana-service networks: - monitoring-net ports: - "3000:3000" environment: GF_PATHS_PROVISIONING: /etc/grafana/provisioning GF_SECURITY_ADMIN_USER: admin GF_SECURITY_ADMIN_PASSWORD: Admin123@ GF_SECURITY_DISABLE_INITIAL_ADMIN_PASSWORD_HINT: "true" volumes: - ${PWD}/grafana/grafana.ini:/etc/grafana/grafana.ini - ${PWD}/grafana/provisioning:/etc/grafana/provisioning depends_on: - prometheus alertmanager: image: prom/alertmanager:latest container_name: alert-manager networks: - monitoring-net ports: - "9093:9093" volumes: - ./alertmanager.yml:/etc/alertmanager/alertmanager.yml 而后是关键的几个配置文件,首先是prometheus方面的prometheus.yml:
# 全局配置 global: scrape_interval: 15s # 抓取监控数据的时间间隔 rule_files: - alerts.yml alerting: alertmanagers: - static_configs: - targets: - alert-manager:9093 # 单独的任务配置,可以设置多个 scrape_configs: - job_name: 'node' scrape_interval: 5s static_configs: - targets: ['node-exporter:9100'] prometheus的报警配置rule文件和alert-manager的实际报警配置就直接用上面的就好,关键是较为复杂的grafana部分,这里面因为要在配置挂载完成datasource的添加和对应dashboard的样板json添加,所以另外准备grafana文件夹,用来存放内部配置grafana.ini和datasource以及dashboard的对应json,最后得到这样文件结构:
$ tree grafana grafana ├── grafana.ini └── provisioning ├── dashboards │ └── node_exporter_dashboard.json └── datasources └── prometheus.yml 上面node_exporter_dashboard.json直接用的前面从grafana的dashboard列表下载的json,太长太完备了,不放在这浪费篇幅了,关注grafana.ini如下:
[paths] provisioning = /etc/grafana/provisioning [dashboards] default_home_dashboard_path = /etc/grafana/provisioning/dashboards/node_exporter_dashboard.json [security] admin_user = ${GF_SECURITY_ADMIN_USER} admin_password = ${GF_SECURITY_ADMIN_PASSWORD} disable_initial_admin_password_hint = true 如上grafana内部配置,设定了其provisioning路径并设定其dashboards的json路径,security部分是为了强制使得设定的管理员账户密码生效,最后就是另外的datasource配置了:
apiVersion: 1 datasources: - name: Prometheus type: prometheus access: proxy url: http://prometheus-service:9090 isDefault: true version: 1 editable: false jsonData: timeInterval: "15s" httpMethod: "GET" 非常简单,而后一波拉起:
# 拉起docker-compose.yml所指定service并后台运行 $ docker compose up -d # 关掉docker-compose.yml指示service $ docker compose down ok,搞定。

















这一切,似未曾拥有