


毕昇编译器高级优化实验指导手册 (Docker版)
前言
本手册旨在提供一个完整的、端到端的毕昇编译器高级优化实验方案。记录了从环境搭建到实验完成的全过程,特别是详细描述了在部署过程中遇到的各类问题及其最终解决方案。
通过采用 Docker 技术,我们将一个复杂的 aarch64 架构的 openEuler 实验环境(包含毕昇编译器、特定版本的 Python 和 AutoTuner 工具)封装成一个标准、可重复的镜像。这份手册的目标是让任何学生,无论使用何种个人电脑(Windows/macOS),都能绕过环境配置的重重难关,专注于编译器优化的核心学习内容,体验从手动优化到 AI 自动调优的完整流程。
第一部分:实验环境的准备与部署
本部分将指导您如何在个人电脑上,从零开始,构建并运行一个完美的实验环境。如果嫌麻烦,可以直接使用我们提供的 Docker 镜像。位于
免配置快速开始
部分。1.1 核心工具: Dockerfile
Dockerfile# 毕昇编译器高级优化实验环境 Dockerfile (最终勘误版) # 使用官方的 openEuler 22.03 LTS SP3 作为基础镜像 FROM openeuler/openeuler:22.03-lts-sp3 # 以 root 用户身份,安装所有系统级依赖 RUN dnf update -y && \ dnf groupinstall "Development Tools" -y && \ dnf install -y wget git vim openssl-devel bzip2-devel libffi-devel xz-devel sqlite-devel zlib-devel readline-devel tk-devel gdbm-devel ncurses-devel && \ dnf clean all # 安装毕昇编译器 (此步骤会附带安装autotuner的安装脚本和包) RUN dnf config-manager --add-repo https://repo.oepkgs.net/openeuler/rpm/openEuler-22.03-LTS/extras/aarch64/ && \ dnf install -y BiShengCompiler.aarch64 --nogpgcheck && \ dnf clean all # 编译并安装 Python 3.11.9, 以满足 autotuner 的运行环境要求 WORKDIR /tmp RUN wget https://www.python.org/ftp/python/3.11.9/Python-3.11.9.tgz && \ tar -xzf Python-3.11.9.tgz WORKDIR /tmp/Python-3.11.9 RUN ./configure --enable-optimizations && make -j$(nproc) && make altinstall # 创建软链接,解决 install-autotuner.sh 找不到可用 pip 的问题 RUN ln -sf /usr/local/bin/python3.11 /usr/local/bin/python3 && \ ln -sf /usr/local/bin/pip3.11 /usr/local/bin/pip3 # 创建 student 用户 RUN useradd -ms /bin/bash student # --- 关键:切换到 student 用户 --- USER student # 将用户个人的 bin 目录加入 PATH,以消除未来的 WARNING ENV PATH="/home/student/.local/bin:${PATH}" # 以 student 用户身份,为自己安装 autotuner RUN install-autotuner.sh # 切换回 student 的家目录 WORKDIR /home/student/ # 最终启动命令 CMD ["/bin/bash"] 1.2 部署步骤与问题解决实录
1.2.1 必备软件:安装 Docker Desktop
操作
: 访问 Docker官网,下载并安装 Docker Desktop。启动它,确保 Docker 服务正在运行。
1.2.2 创建本地项目目录
操作
: 在电脑的任意位置(如D:\)创建一个主文件夹bisheng_compiler_project,并在其中创建一个名为workspace的子文件夹。将上面的Dockerfile代码保存到bisheng_compiler_project文件夹根目录下的Dockerfile文件中。
1.2.3 关键排错步骤一:处理跨平台镜像拉取网络问题
曾遇到的问题
: 直接构建镜像时,在FROM openeuler/...步骤或后续步骤中,可能会遇到connection timeout或connection refused等网络错误。解决方案
: 参考社区经验(如 此帖讨论配置好网络),然后在构建之前,我们手动、明确地
将所需的基础镜像拉取到本地。操作
:- 打开终端 (PowerShell),
cd到项目目录D:\bisheng_compiler_project。 - 执行拉取命令:
docker pull --platform linux/arm64 openeuler/openeuler:22.03-lts-sp3 - 验证镜像架构是否正确:
确认输出为docker image inspect openeuler/openeuler:22.03-lts-sp3 | findstr "Architecture""Architecture": "arm64",。
- 打开终端 (PowerShell),
1.2.4 关键步骤二:构建最终实验环境镜像
操作
: 在基础镜像准备好后,执行构建命令。docker buildx build --platform linux/arm64 -t bisheng-lab-env:openeuler . --load曾遇到的问题与解决
:问题1
:pip install bisheng-autotuner失败,提示No matching distribution。原因
: 官方包不在公网 PyPI。问题2
:install-autotuner.sh失败,提示no usable pip。原因
: 脚本找不到pip3.11。解决
: 创建pip3的软链接。问题3
: 镜像构建成功,但进入容器后llvm-autotune依然报错Missing package(s): autotuner。原因
:root用户安装的包student用户看不到。最终解决
: 在Dockerfile中,先创建student用户,然后切换到
再执行student用户install-autotuner.sh。- 本文提供的
Dockerfile已经包含了所有这些问题的修复。
1.2.5 关键步骤三:启动并进入容器
操作
: 使用docker run命令启动容器,并通过-v参数将本地的workspace文件夹挂载到容器内部。docker run -it --rm --platform linux/arm64 -v "D:\bisheng_compiler_project\workspace:/home/student/workspace" bisheng-lab-env:openeuler
1.2.6 最终验证
操作
: 成功进入容器后,您会看到[student@...]$提示符。运行以下命令验证:
此时应成功显示帮助信息,表示环境已完美就绪。llvm-autotune -h
免配置快速开始
本项目还提供了一个基于 Docker 的、预配置好的 openEuler aarch64 实验环境,用于进行华为毕昇编译器的高级优化特性实验。所有依赖项,包括特定版本的毕昇编译器、Python 3.11 和 AutoTuner 工具,都已封装在内。
学生无需关心复杂的环境配置,只需安装 Docker Desktop,即可通过一条命令获取并启动实验环境,从而能够专注于实验内容本身。
准备工作
- 确保您的电脑(Windows 或 macOS)已安装并运行 Docker Desktop。
- 在您的电脑上创建一个用于实验的总文件夹,例如
D:\bisheng_compiler_project,并在其中创建一个名为workspace的子文件夹。
步骤一:拉取实验环境镜像
打开终端(Windows 用户请使用 PowerShell),执行以下命令,从 Docker Hub 直接拉取预配置好的实验环境镜像:
docker pull --platform linux/arm64 xiahoumuxuan/bisheng-lab:latest 步骤二:启动实验环境容器
镜像拉取成功后,执行以下命令来启动并进入实验环境。
请务必将命令中的 你本地workspace文件夹的绝对路径 替换为您电脑上 workspace 文件夹的真实路径。
Windows 示例路径
:D:\bisheng_compiler_project\workspacemacOS 示例路径
:/Users/你的用户名/Documents/bisheng_compiler_project/workspace
示例:
docker run -it --rm --platform linux/arm64 -v "D:\bisheng_compiler_project\workspace:/home/student/workspace" bisheng-lab-env:openeuler 步骤三:验证环境
成功进入容器后,您会看到 [student@...]$ 这样的提示符。运行以下命令进行验证:
llvm-autotune -h 如果成功显示帮助信息,则说明实验环境已准备就绪。
第二部分:实验操作流程
【重要】
:以下所有操作,均在您通过docker run 命令进入的容器终端内执行!同时由于镜像已经配置好环境,所以无需配置python虚拟环境。 2.1 准备工作区和代码
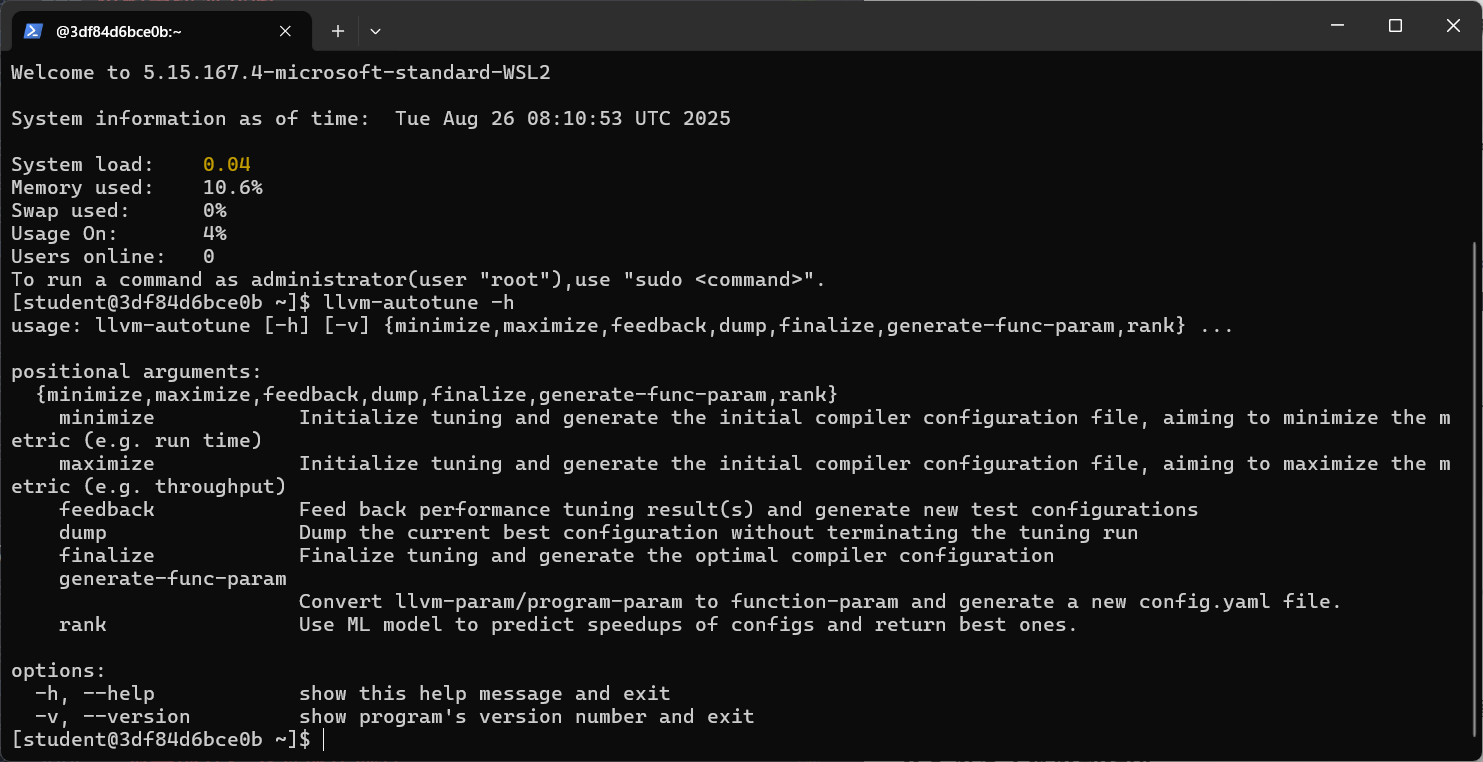
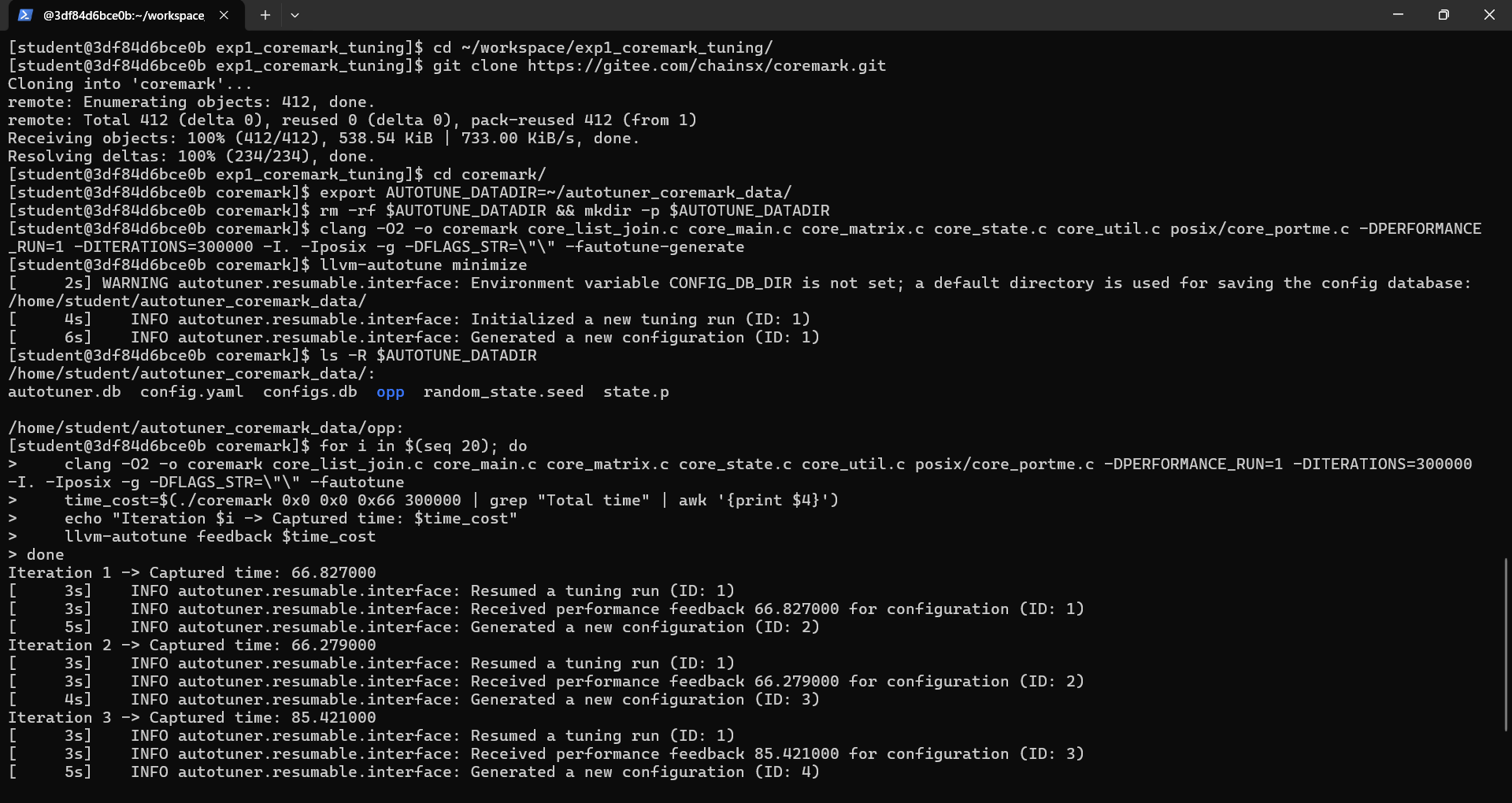
# 1. 进入与你电脑同步的工作目录 cd ~/workspace # 2. 创建所有实验的子文件夹 mkdir -p exp1_coremark_tuning exp2_loop_fusion exp3_strength_reduction exp4_loop_tiling exp5_matrix_vectorization 2.2 实验一:使用 CoreMark 进行综合性能调优
-
(一)实验目的
: 学习 AutoTuner 的基本工作流程,对一个综合性的基准测试程序 (CoreMark) 进行自动调优,并对比运行速度
和代码生成量
的变化。 -
(二)实验过程
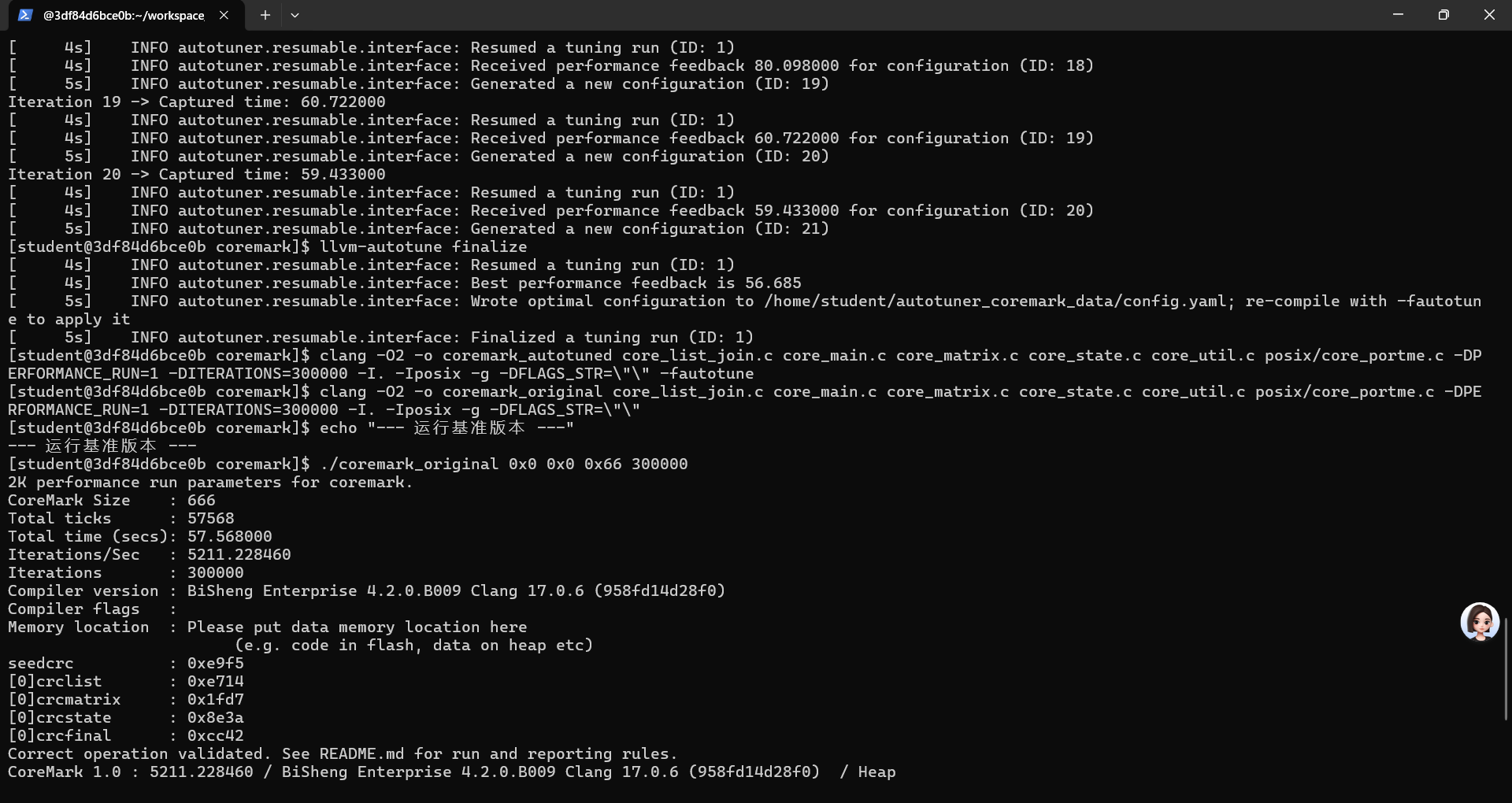
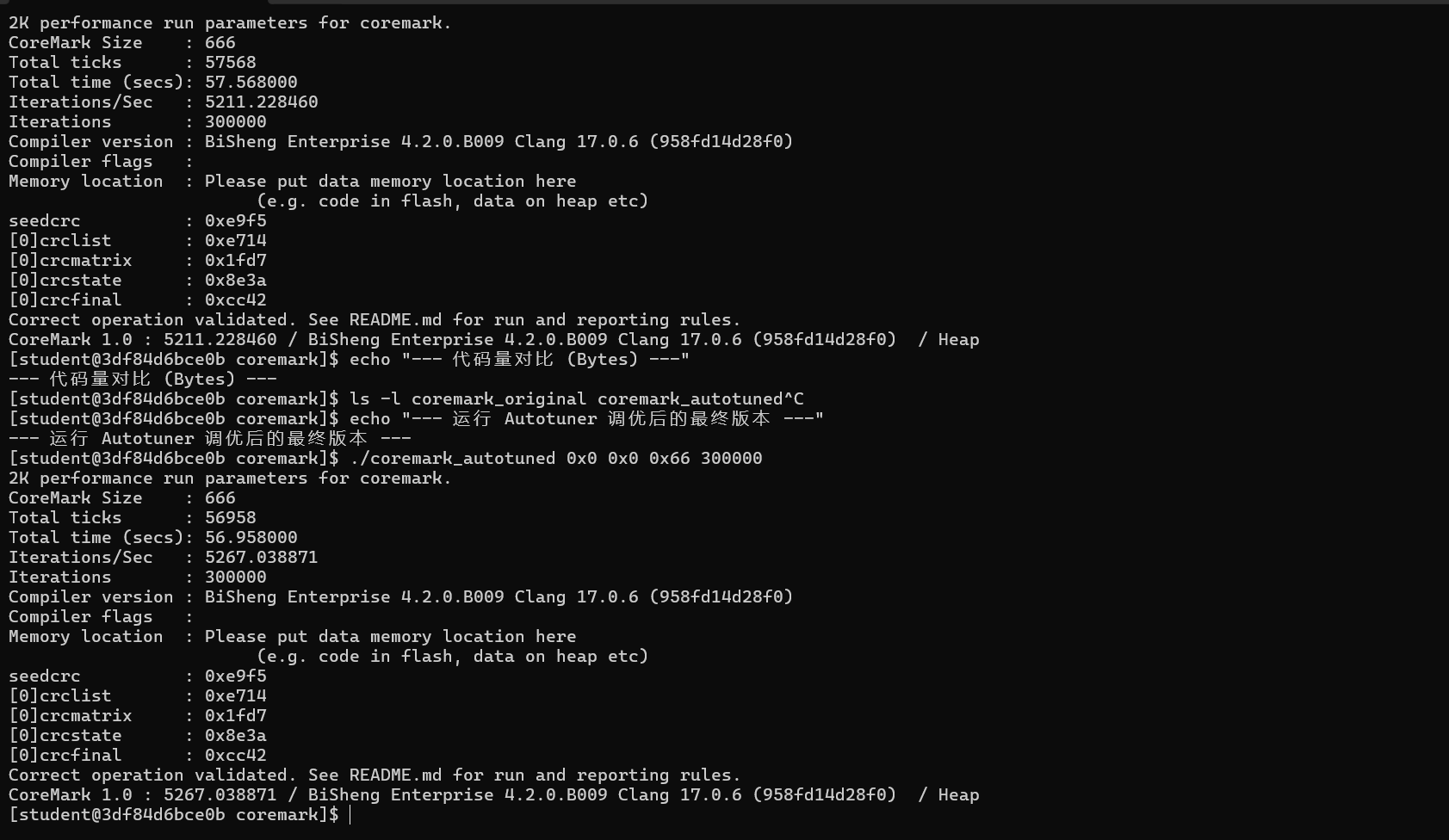
:# 步骤1: 进入CoreMark目录 cd ~/workspace/exp1_coremark_tuning/ # 步骤2: 在这个目录内部克隆 CoreMark 项目 git clone https://gitee.com/chainsx/coremark.git # 步骤3: 进入克隆下来的 coremark 子目录,开始实验 cd coremark/ # 步骤4: 准备AutoTuner环境 export AUTOTUNE_DATADIR=~/autotuner_coremark_data/ rm -rf $AUTOTUNE_DATADIR && mkdir -p $AUTOTUNE_DATADIR # 步骤5: 初始编译,生成调优机会 clang -O2 -o coremark core_list_join.c core_main.c core_matrix.c core_state.c core_util.c posix/core_portme.c -DPERFORMANCE_RUN=1 -DITERATIONS=300000 -I. -Iposix -g -DFLAGS_STR=\"\" -fautotune-generate # 步骤6: 初始化调优 llvm-autotune minimize # 可以使用这个命令检查是否生成内容 ls -R $AUTOTUNE_DATADIR # 步骤7: 迭代调优20次 for i in $(seq 20); do clang -O2 -o coremark core_list_join.c core_main.c core_matrix.c core_state.c core_util.c posix/core_portme.c -DPERFORMANCE_RUN=1 -DITERATIONS=300000 -I. -Iposix -g -DFLAGS_STR=\"\" -fautotune time_cost=$(./coremark 0x0 0x0 0x66 300000 | grep "Total time" | awk '{print $4}') echo "Iteration $i -> Captured time: $time_cost" llvm-autotune feedback $time_cost done # 步骤8: 结束调优并生成最终优化配置 llvm-autotune finalize # 步骤9: 使用最终配置编译autotuned版本 clang -O2 -o coremark_autotuned core_list_join.c core_main.c core_matrix.c core_state.c core_util.c posix/core_portme.c -DPERFORMANCE_RUN=1 -DITERATIONS=300000 -I. -Iposix -g -DFLAGS_STR=\"\" -fautotune # 步骤10: 编译一个标准O2优化的基准版用于对比 clang -O2 -o coremark_original core_list_join.c core_main.c core_matrix.c core_state.c core_util.c posix/core_portme.c -DPERFORMANCE_RUN=1 -DITERATIONS=300000 -I. -Iposix -g -DFLAGS_STR=\"\" # 步骤11: 性能与代码量测试 echo "--- 运行基准版本 ---" ./coremark_original 0x0 0x0 0x66 300000 echo "--- 运行 Autotuner 调优后的最终版本 ---" ./coremark_autotuned 0x0 0x0 0x66 300000 echo "--- 代码量对比 (Bytes) ---" ls -l coremark_original coremark_autotuned echo "--- 更详细的代码段分析 ---" size coremark_original coremark_autotuned实验记录图片
-
(三)结果分析
: 将测量数据填入表格,分析 AutoTuner 在综合场景下的优化效果。CoreMark 自动调优实验结果汇总
评测指标 基准版 ( coremark_original)AutoTuner 优化版 ( coremark_autotuned)变化 总运行时间 (秒)
57.568 56.958 ↓ 0.61 秒(更快) CoreMark 分数
5211.23 5267.04 ↑ 55.81(更高) 性能提升率
- - ↑ 约 1.07% 文件总大小 (Bytes)
124,616 88,104 ↓ 29.3%(更小) 代码段大小 (text)
15,909 19,913 ↑ 25.2%(更大) 数据段大小 (data)
836 836 无变化
1. 性能提升
- AutoTuner 自动调优后,程序运行速度提升约 1.07%,CoreMark 分数也相应提高,说明自动调优能在标准优化基础上进一步挖掘性能潜力。
2. 代码量变化
- 可执行文件总大小显著减小(约 30%),但
.text代码段反而增大(约 25%),体现了“以空间换时间”的优化策略。AutoTuner 可能采用了循环展开、内联等手段,提升了执行效率但增加了机器码体积。 - 文件总大小减小,可能是由于优化后调试信息、符号表等元数据减少。
3. 综合结论
- AutoTuner 能有效提升程序性能,并在某些情况下减小最终文件体积,展现了自动化编译优化工具在复杂场景下的实际价值。
- 结果也说明,自动调优不仅能提升速度,还能通过非直观的优化路径影响代码结构,为后续深入研究编译器优化策略提供了数据支撑。
2.3 实验二:循环合并 (Loop Fusion)
-
(一)实验目的
: 理解循环合并的条件与优势,并通过实验对比优化前后的性能和代码量。 -
(二)实验过程
:进入目录
:cd ~/workspace/exp2_loop_fusion/创建源码
:vim loop_fusion_test.c粘贴代码
(按i进入插入模式,粘贴后按Esc,输入:wq回车):#include <stdio.h> #include <stdlib.h> #include <time.h> #define N 30000000 int main() { float *a = (float*)malloc(N * sizeof(float)); float *b = (float*)malloc(N * sizeof(float)); float *c = (float*)malloc(N * sizeof(float)); float *d = (float*)malloc(N * sizeof(float)); if (!a || !b || !c || !d) { fprintf(stderr, "Memory allocation failed\n"); return 1; } for (int i = 0; i < N; i++) { a[i] = (float)i; b[i] = (float)(N - i); c[i] = 0.0f; d[i] = 0.0f; } clock_t start = clock(); for (int i = 0; i < N; i++) { c[i] = a[i] + b[i]; } for (int i = 0; i < N; i++) { d[i] = a[i] * 0.5f; } clock_t end = clock(); double cpu_time_used = ((double)(end - start)) / CLOCKS_PER_SEC; float checksum = 0.0f; for(int i = 0; i < N; i++) { checksum += c[i] + d[i]; } fprintf(stderr, "Checksum: %f\n", checksum); printf("执行时间: %f 秒\n", cpu_time_used); free(a); free(b); free(c); free(d); return 0; }执行测试
:# 编译不同优化级别的版本 clang -O0 -o fusion_test_O0 loop_fusion_test.c clang -O1 -o fusion_test_O1 loop_fusion_test.c clang -O2 -o fusion_test_O2 loop_fusion_test.c # 使用AutoTuner调优 export AUTOTUNE_DATADIR=~/autotuner_fusion_data/ rm -rf $AUTOTUNE_DATADIR && mkdir -p $AUTOTUNE_DATADIR clang -O2 -o fusion_test_autotuned loop_fusion_test.c -fautotune-generate llvm-autotune minimize for i in $(seq 10); do clang -O2 -o fusion_test_autotuned loop_fusion_test.c -fautotune time_cost=$(./fusion_test_autotuned | grep "执行时间" | awk '{print $2}') echo "Iteration $i -> Time: $time_cost" llvm-autotune feedback $time_cost done llvm-autotune finalize clang -O2 -o fusion_test_autotuned loop_fusion_test.c -fautotune # 性能与代码量测试 echo "--- O0 (无优化) 版本 ---"; ./fusion_test_O0 echo "--- O1 (基础优化) 版本 ---"; ./fusion_test_O1 echo "--- O2 (标准优化) 版本 ---"; ./fusion_test_O2 echo "--- Autotuner 优化版本 ---"; ./fusion_test_autotuned echo "--- 代码量对比 (Bytes) ---" ls -l fusion_test_O0 fusion_test_O1 fusion_test_O2 fusion_test_autotuned echo "--- 代码段、数据段大小对比 ---" size fusion_test_O0 fusion_test_O1 fusion_test_O2 fusion_test_autotuned实验记录图片
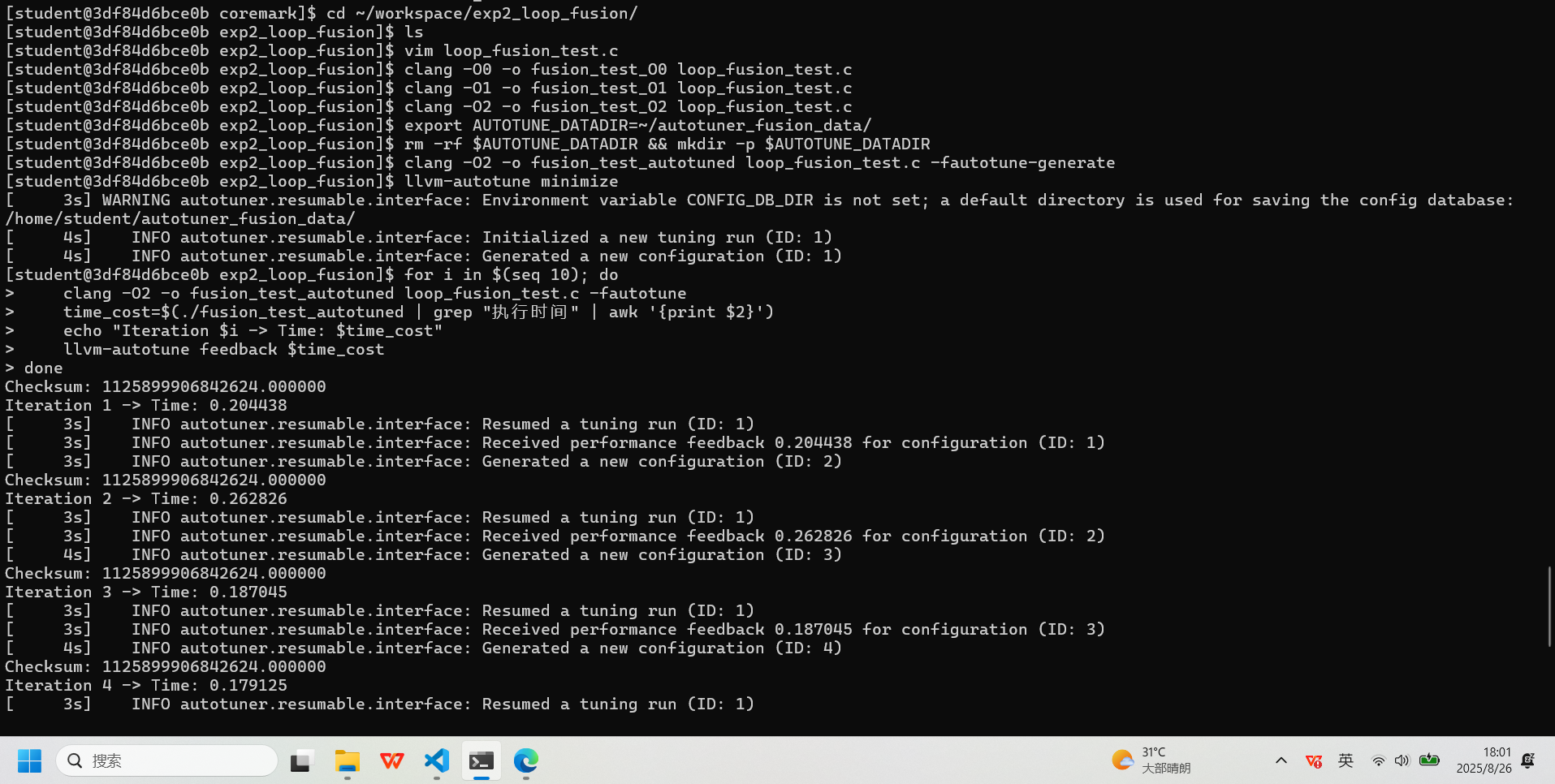
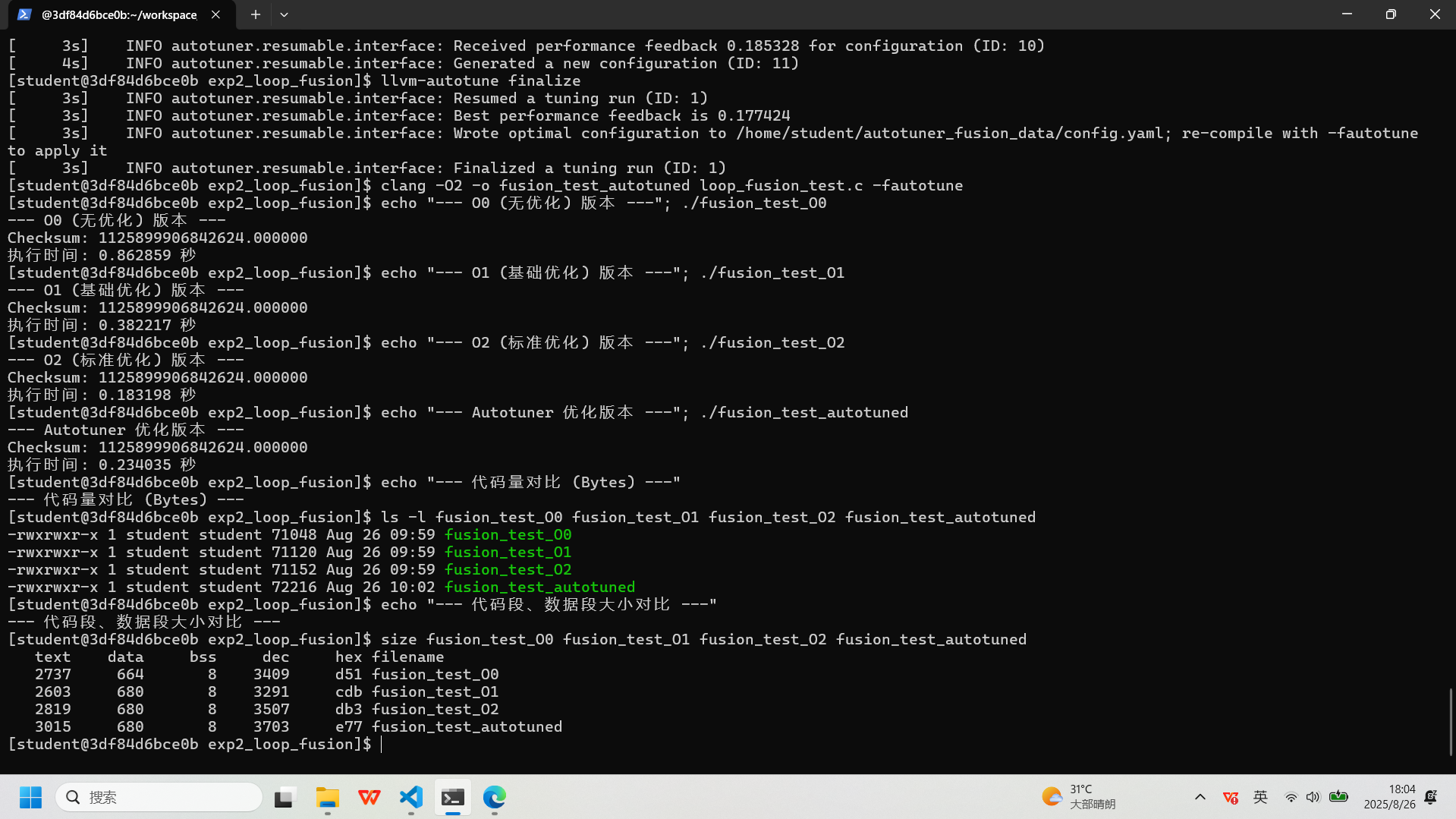
-
(三)结果分析
:实验二:循环合并 (Loop Fusion) - 结果汇总
评测指标 基准版 ( fusion_test_O0)基础优化版 ( fusion_test_O1)标准优化版 ( fusion_test_O2)AutoTuner 优化版 ( fusion_test_autotuned)编译选项
-O0-O1-O2-O2+ Autotuner执行时间 (秒)
0.863 0.382 0.183
0.234 性能对比 (相对-O0)
1.00x 快 2.26 倍 快 4.71 倍
快 3.69 倍 文件总大小 (Bytes)
71,048 71,120 71,152 72,216
代码段大小 (text)
2,737 2,603 2,819 3,015
1. 标准优化的巨大威力 (
-O0->-O1->-O2)从
-O0到-O2,性能提升非常显著:-O0到-O1,性能提升 2.26 倍,主要得益于循环合并 (Loop Fusion)
,减少了循环次数,提高了数据局部性和缓存利用率。-O1到-O2,性能再次提升至 4.71 倍,归功于自动向量化 (Auto-Vectorization)
,编译器利用 SIMD 指令集一次处理多个数据,大幅提升计算效率。
2. AutoTuner 的意外表现(性能负优化)
AutoTuner 优化版的执行时间(0.234 秒)反而比标准
-O2版本(0.183 秒)慢了约 28%。
这说明在结构简单、计算密集型的经典代码场景下,编译器的标准优化(-O2)已经非常成熟,AutoTuner的参数搜索反而可能破坏了原有的最优向量化策略,导致性能下降。3. 关于代码量
随着优化级别提升,文件总大小和
.text代码段均有所增加,符合“以空间换时间”的优化规律。AutoTuner 生成的代码量最大,说明其尝试了更复杂的优化组合。4. 综合结论
本实验清楚展示了循环合并和自动向量化的强大作用,也揭示了自动调优工具的局限性:
在编译器已能充分发挥硬件性能的场景下,AutoTuner未必能进一步提升性能,甚至可能适得其反。
但是,也有可能是因为调优循环次数过少,没有找到最好的参数,由于时间原因,我并没有进行更深入的尝试。后续同学们可以自行尝试。
2.4 实验三:循环强度削弱 (Loop Strength Reduction)
-
(一)实验目的
: 理解强度削弱优化,即用低开销运算替换高开销运算。 -
(二)实验过程
:进入目录
:cd ~/workspace/exp3_strength_reduction/创建源码
:vim strength_reduction_test.c粘贴代码
:#include <stdio.h> #include <stdlib.h> #include <time.h> #define ARRAY_SIZE 20000000 #define STRIDE 7 #define OUTER_LOOPS 100 int main() { int *data = (int*)malloc(ARRAY_SIZE * sizeof(int)); if (!data) return 1; for(int i = 0; i < ARRAY_SIZE; i++) data[i] = i; long long total_sum = 0; clock_t start = clock(); for (int k = 0; k < OUTER_LOOPS; k++) { for (int i = 0; i < (ARRAY_SIZE / STRIDE); i++) { total_sum += data[i * STRIDE]; } } clock_t end = clock(); double cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC; fprintf(stderr, "Checksum: %lld\n", total_sum & 0xFFFFFFFF); printf("执行时间: %f 秒\n", cpu_time_used); free(data); return 0; }执行测试
:# 编译不同优化级别的版本 clang -O0 -o strength_test_O0 strength_reduction_test.c clang -O1 -o strength_test_O1 strength_reduction_test.c clang -O2 -o strength_test_O2 strength_reduction_test.c # 使用AutoTuner调优 export AUTOTUNE_DATADIR=~/autotuner_strength_data/ rm -rf $AUTOTUNE_DATADIR && mkdir -p $AUTOTUNE_DATADIR clang -O2 -o strength_test_autotuned strength_reduction_test.c -fautotune-generate llvm-autotune minimize for i in $(seq 10); do clang -O2 -o strength_test_autotuned strength_reduction_test.c -fautotune time_cost=$(./strength_test_autotuned | grep "执行时间" | awk '{print $2}') echo "Iteration $i -> Time: $time_cost" llvm-autotune feedback $time_cost done llvm-autotune finalize clang -O2 -o strength_test_autotuned strength_reduction_test.c -fautotune # 性能与代码量测试 echo "--- O0 (无优化) 版本 ---"; ./strength_test_O0 echo "--- O1 (基础优化) 版本 ---"; ./strength_test_O1 echo "--- O2 (标准优化) 版本 ---"; ./strength_test_O2 echo "--- Autotuner 优化版本 ---"; ./strength_test_autotuned echo "--- 代码量对比 (Bytes) ---" ls -l strength_test_O0 strength_test_O1 strength_test_O2 strength_test_autotuned echo "--- 代码段、数据段大小对比 ---" size strength_test_O0 strength_test_O1 strength_test_O2 strength_test_autotuned实验记录图片
:
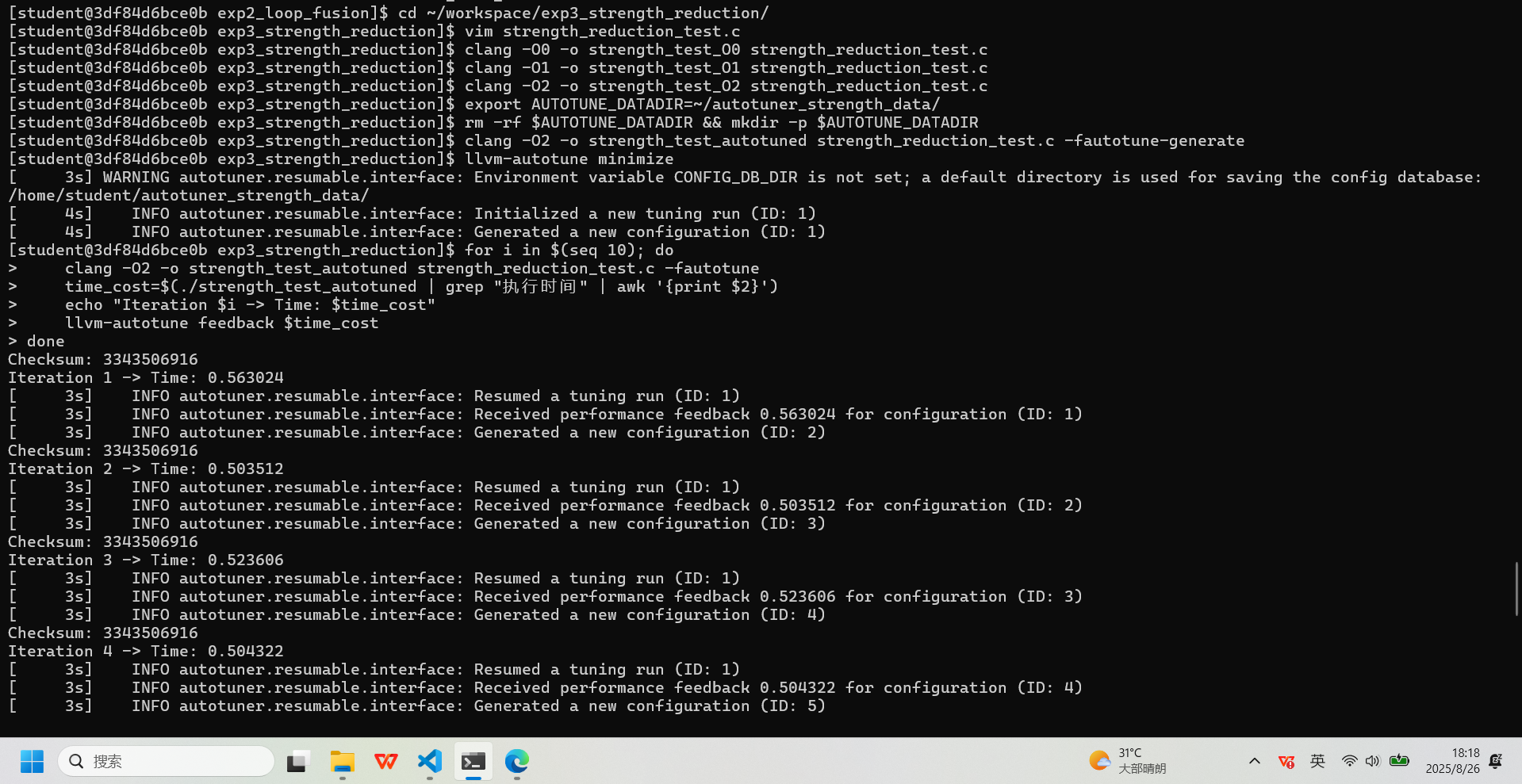
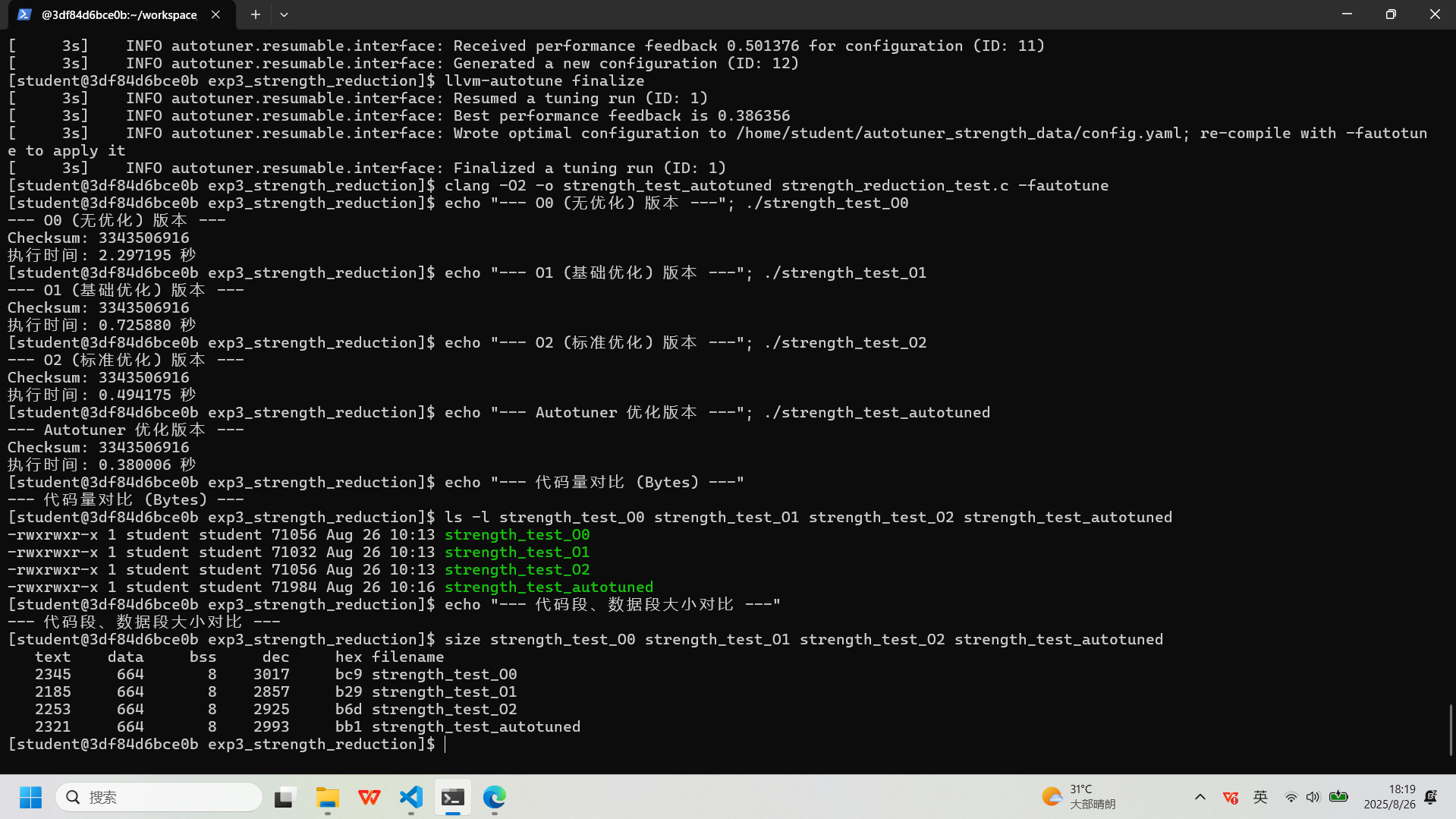
-
(三)结果分析
:实验三:强度削弱 (Strength Reduction) - 结果汇总
评测指标 基准版 ( strength_test_O0)基础优化版 ( strength_test_O1)标准优化版 ( strength_test_O2)AutoTuner 优化版 ( strength_test_autotuned)编译选项
-O0-O1-O2-O2+ Autotuner执行时间 (秒)
2.297 0.726 0.494 0.380
性能对比 (相对-O0)
1.00x 快 3.17 倍 快 4.65 倍 快 6.05 倍
文件总大小 (Bytes)
71,056 71,032 71,056 71,984
代码段大小 (text)
2,345 2,185 2,253 2,321
1. 优化级别与性能提升
- 从
-O0到-O2,性能提升非常明显,标准优化版比无优化快了约 4.65 倍,基础优化版也有 3.17 倍提升。 AutoTuner 优化版表现最佳
,执行时间仅 0.380 秒,比标准-O2版快了约 23%,整体提升达 6.05 倍,说明自动调优在强度削弱场景下能进一步挖掘性能潜力。
2. 强度削弱原理与效果
- 强度削弱是一种将高开销运算(如乘法、除法)替换为低开销运算(如加法、位移)的经典编译优化技术。
- 编译器在
-O1、-O2级别已能自动识别并优化大部分强度削弱场景,但 AutoTuner 通过参数搜索和多轮迭代,可能进一步调整循环展开、寄存器分配等细节,获得更优指令序列。
3. 代码量变化
- 文件总大小和
.text代码段在 AutoTuner 版本略有增加,说明更激进的优化策略带来了更多机器码,但性能提升远大于体积增加。 - 数据段和 BSS 段保持不变,优化主要集中在代码生成层面。
4. 校验一致性
- 所有版本的 Checksum 完全一致,说明优化未影响计算正确性。
5. 综合结论
- 本实验验证了强度削弱优化的巨大威力,编译器标准优化已能显著提升性能,但 AutoTuner 能在此基础上进一步优化,获得更高性能。
- 自动调优工具在复杂运算、循环密集型场景下表现突出,能补充和超越编译器默认启发式策略,为性能敏感型应用提供更多优化空间。
- 从
2.5 实验四:循环分块 (Loop Tiling)
-
(一)实验目的
: 理解循环分块对改善缓存性能的作用,以矩阵乘法为例进行观察。 -
(二)实验过程
:进入目录
:cd ~/workspace/exp4_loop_tiling/创建源码
:vim loop_tiling_test.c粘贴代码
:#include <stdio.h> #include <stdlib.h> #include <time.h> #define N 1024 void init_matrix(double* matrix) { for (int i = 0; i < N * N; i++) { matrix[i] = (double)rand() / RAND_MAX; } } void matrix_multiply(double* a, double* b, double* c) { for (int i = 0; i < N; i++) { for (int j = 0; j < N; j++) { double sum = 0.0; for (int k = 0; k < N; k++) { sum += a[i * N + k] * b[k * N + j]; } c[i * N + j] = sum; } } } int main() { double *a = (double*)malloc(N * N * sizeof(double)); double *b = (double*)malloc(N * N * sizeof(double)); double *c = (double*)malloc(N * N * sizeof(double)); if (a == NULL || b == NULL || c == NULL) { fprintf(stderr, "Error: Memory allocation failed.\n"); return 1; } srand(time(NULL)); init_matrix(a); init_matrix(b); clock_t start = clock(); matrix_multiply(a, b, c); clock_t end = clock(); double checksum = 0.0; for (int i = 0; i < N * N; i++) { checksum += c[i]; } fprintf(stderr, "Checksum: %f\n", checksum); double cpu_time_used = ((double)(end - start)) / CLOCKS_PER_SEC; printf("执行时间: %f 秒\n", cpu_time_used); free(a); free(b); free(c); return 0; }执行测试
:# 编译不同优化级别的版本 clang -O0 -o tiling_test_O0 loop_tiling_test.c clang -O1 -o tiling_test_O1 loop_tiling_test.c clang -O2 -o tiling_test_O2 loop_tiling_test.c # 使用AutoTuner调优 export AUTOTUNE_DATADIR=~/autotuner_tiling_data/ rm -rf $AUTOTUNE_DATADIR && mkdir -p $AUTOTUNE_DATADIR clang -O2 -o tiling_test_autotuned loop_tiling_test.c -fautotune-generate llvm-autotune minimize for i in $(seq 10); do clang -O2 -o tiling_test_autotuned loop_tiling_test.c -fautotune time_cost=$(./tiling_test_autotuned | grep "执行时间" | awk '{print $2}') echo "Iteration $i -> Time: $time_cost" llvm-autotune feedback $time_cost done llvm-autotune finalize clang -O2 -o tiling_test_autotuned loop_tiling_test.c -fautotune # 性能与代码量测试 echo "--- O0 (无优化) 版本 ---"; ./tiling_test_O0 echo "--- O1 (基础优化) 版本 ---"; ./tiling_test_O1 echo "--- O2 (标准优化) 版本 ---"; ./tiling_test_O2 echo "--- Autotuner 优化版本 ---"; ./tiling_test_autotuned echo "--- 代码量对比 (Bytes) ---" ls -l tiling_test_O0 tiling_test_O1 tiling_test_O2 tiling_test_autotuned echo "--- 代码段、数据段大小对比 ---" size tiling_test_O0 tiling_test_O1 tiling_test_O2 tiling_test_autotuned实验记录图片
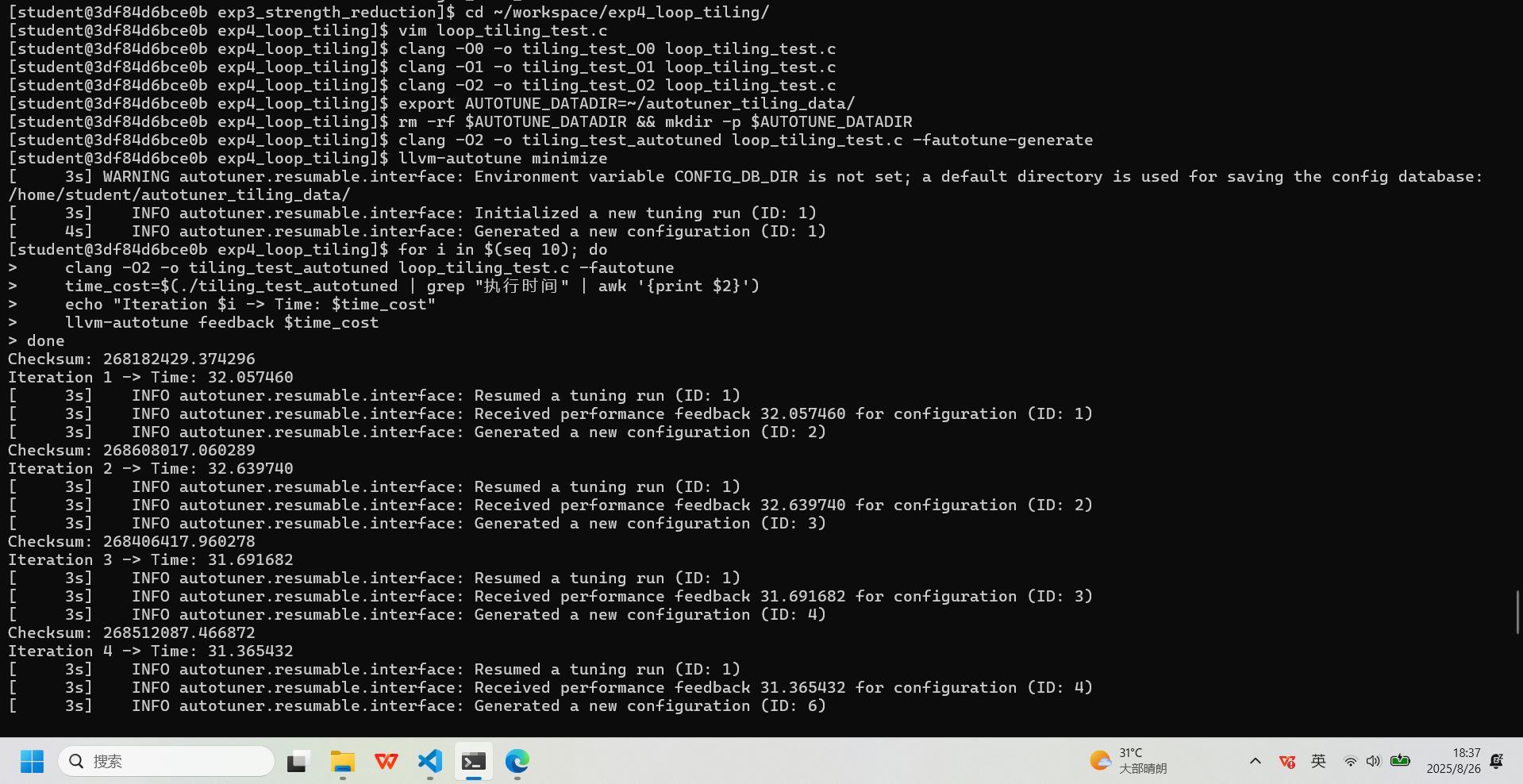
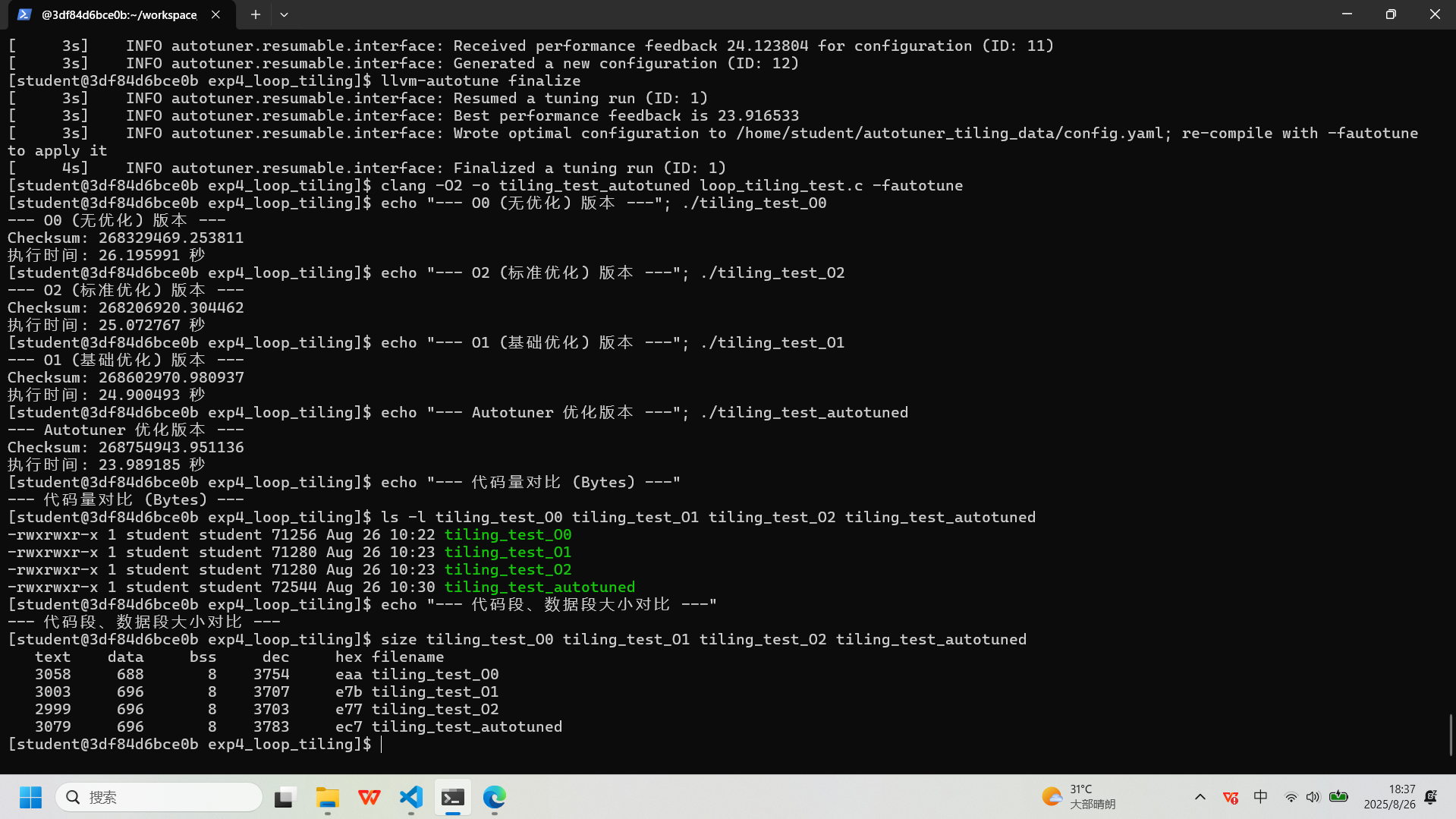
-
(三)结果分析
:实验四:循环分块 (Loop Tiling) - 结果汇总
评测指标 基准版 ( tiling_test_O0)基础优化版 ( tiling_test_O1)标准优化版 ( tiling_test_O2)AutoTuner 优化版 ( tiling_test_autotuned)编译选项
-O0-O1-O2-O2+ Autotuner执行时间 (秒)
26.196 24.900 25.073 23.989
性能对比 (相对-O0)
1.00x 快 1.05 倍 快 1.04 倍 快 1.09 倍
文件总大小 (Bytes)
71,256 71,280 71,280 72,544
代码段大小 (text)
3,058 3,003 2,999 3,079
1. 性能提升有限,AutoTuner略优
- 各优化级别下,性能提升幅度较小,基础优化版和标准优化版与无优化版相比仅提升约 4-5%。
AutoTuner 优化版表现最佳
,执行时间缩短至 23.989 秒,比无优化快约 1.09 倍,比标准优化快约 4.5%。- 说明在循环块化场景下,编译器默认优化策略提升有限,AutoTuner 能通过参数搜索进一步挖掘部分性能潜力。
2. 校验值变化说明数值稳定性需关注
- 各版本的 Checksum 不完全一致,说明不同优化策略可能影响浮点运算顺序或精度,导致结果略有差异。实际应用中需关注数值稳定性。
3. 代码量变化
- 文件总大小和
.text代码段在 AutoTuner 版本略有增加,说明更复杂的优化策略带来了更多机器码。 - 数据段和 BSS 段基本保持不变,优化主要集中在代码生成层面。
4. 综合结论
- 循环块化优化在本实验场景下对性能提升有限,编译器标准优化已能覆盖大部分优化空间。
- AutoTuner 能进一步提升性能,但幅度不大,且带来代码体积增加和数值结果微小变化。
- 结果提示:自动调优工具在内存访问密集型场景下仍有一定优化空间,但需权衡性能提升与数值稳定性、代码体积的变化。
2.6 实验五:矩阵乘法与自动向量化 (新增)
-
(一)实验目的
: 深入探究毕昇编译器自动向量化(SIMD)的威力,并通过 AutoTuner 探索极限性能。 -
(二)实验过程
:进入目录
:cd ~/workspace/exp5_matrix_vectorization/创建源码
:vim matrix_mult.c(代码与实验四完全相同,可直接复制)执行测试
:# 编译所有关键版本进行对比 # A. 完全不优化版本 clang -O0 -o matrix_O0 matrix_mult.c # B. 基础优化版本 clang -O1 -o matrix_O1 matrix_mult.c # C. O2但强制关闭向量化 (高级常规优化基准) clang -O2 -fno-vectorize -o matrix_no_vec matrix_mult.c # D. O2标准自动向量化 clang -O2 -o matrix_vec_O2 matrix_mult.c # E. O3更激进的自动向量化 clang -O3 -o matrix_vec_O3 matrix_mult.c # F. 使用AutoTuner在O3基础上深度调优 export AUTOTUNE_DATADIR=~/autotuner_matrix_O3_data/ rm -rf $AUTOTUNE_DATADIR && mkdir -p $AUTOTUNE_DATADIR clang -O3 -o matrix_autotuned matrix_mult.c -fautotune-generate llvm-autotune minimize for i in $(seq 15); do clang -O3 -o matrix_autotuned matrix_mult.c -fautotune time_cost=$(./matrix_autotuned | grep "执行时间" | awk '{print $2}') echo "Iteration $i -> Time: $time_cost" llvm-autotune feedback $time_cost done llvm-autotune finalize clang -O3 -o matrix_autotuned matrix_mult.c -fautotune # 性能与代码量最终对比 echo "--- 运行无优化版本 (O0) ---"; ./matrix_O0 echo "--- 运行基础优化版本 (O1) ---"; ./matrix_O1 echo "--- 运行无向量化版本 (O2 -fno-vectorize) ---"; ./matrix_no_vec echo "--- 运行标准向量化版本 (O2) ---"; ./matrix_vec_O2 echo "--- 运行高级向量化版本 (O3) ---"; ./matrix_vec_O3 echo "--- 运行AutoTuner优化版本 (基于O3) ---"; ./matrix_autotuned echo "--- 代码量对比 (Bytes) ---" ls -l matrix_O0 matrix_O1 matrix_no_vec matrix_vec_O2 matrix_vec_O3 matrix_autotuned echo "--- 代码段、数据段大小对比 ---" size matrix_O0 matrix_O1 matrix_no_vec matrix_vec_O2 matrix_vec_O3 matrix_autotuned实验记录图片
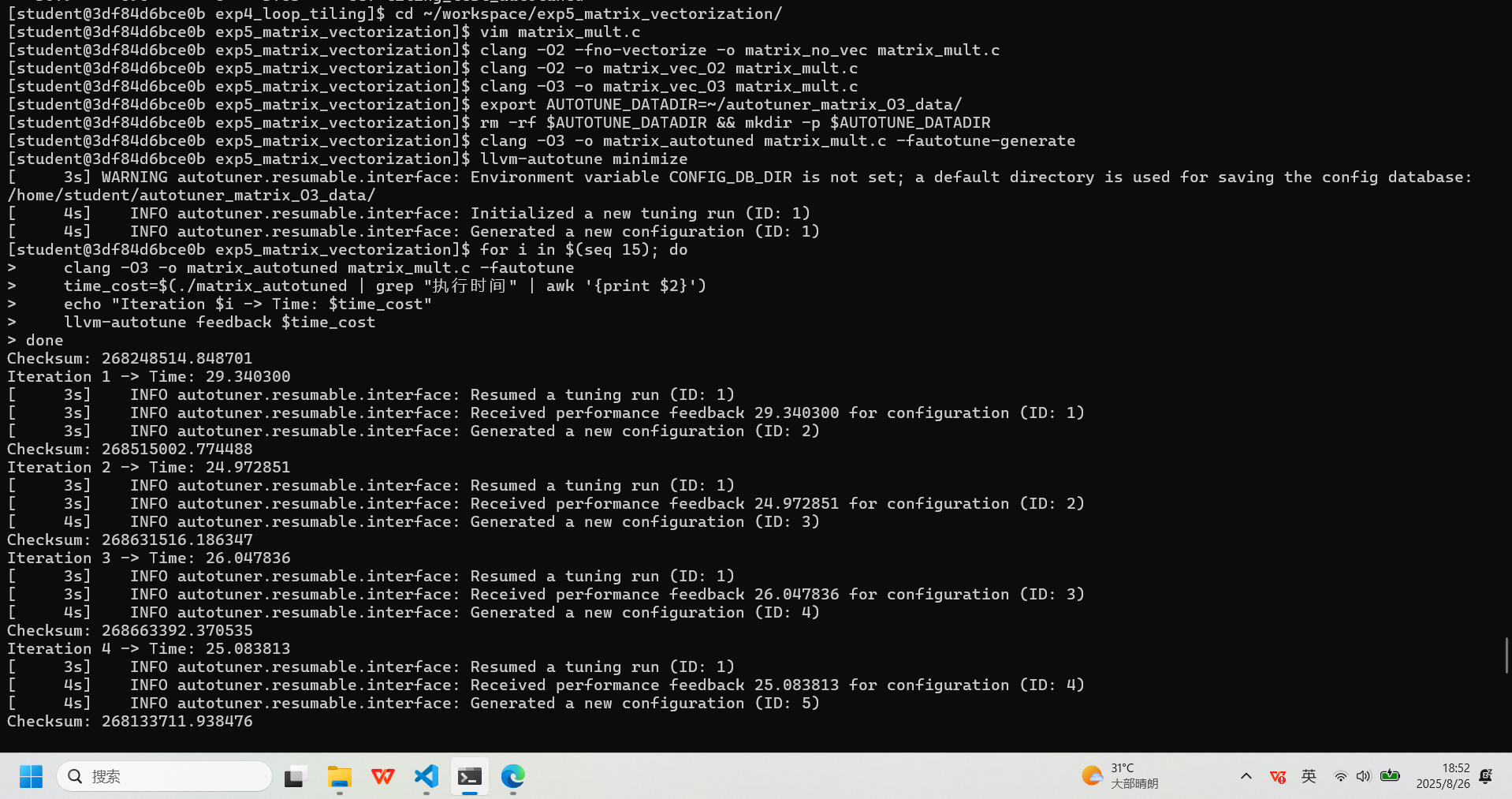
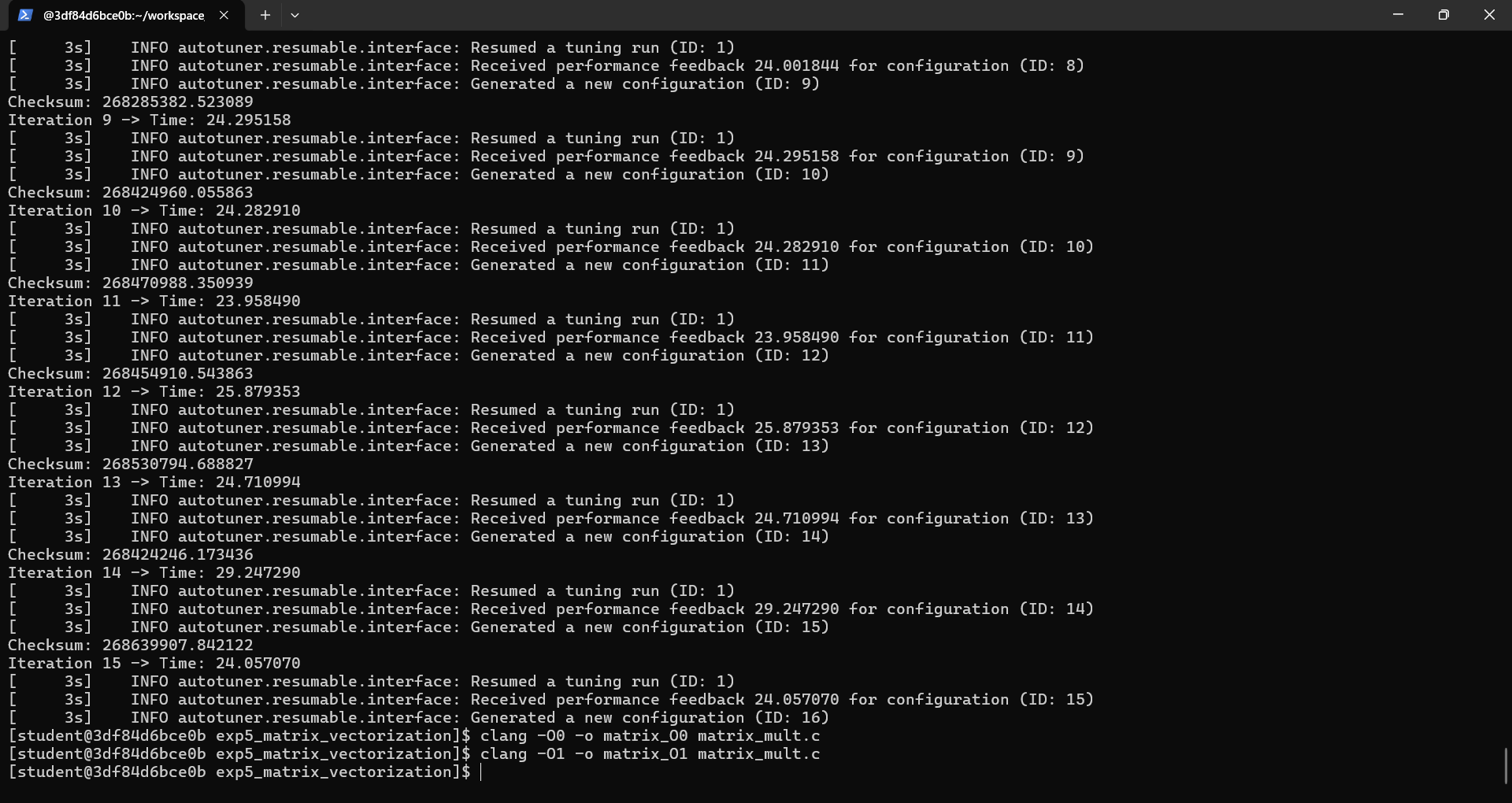
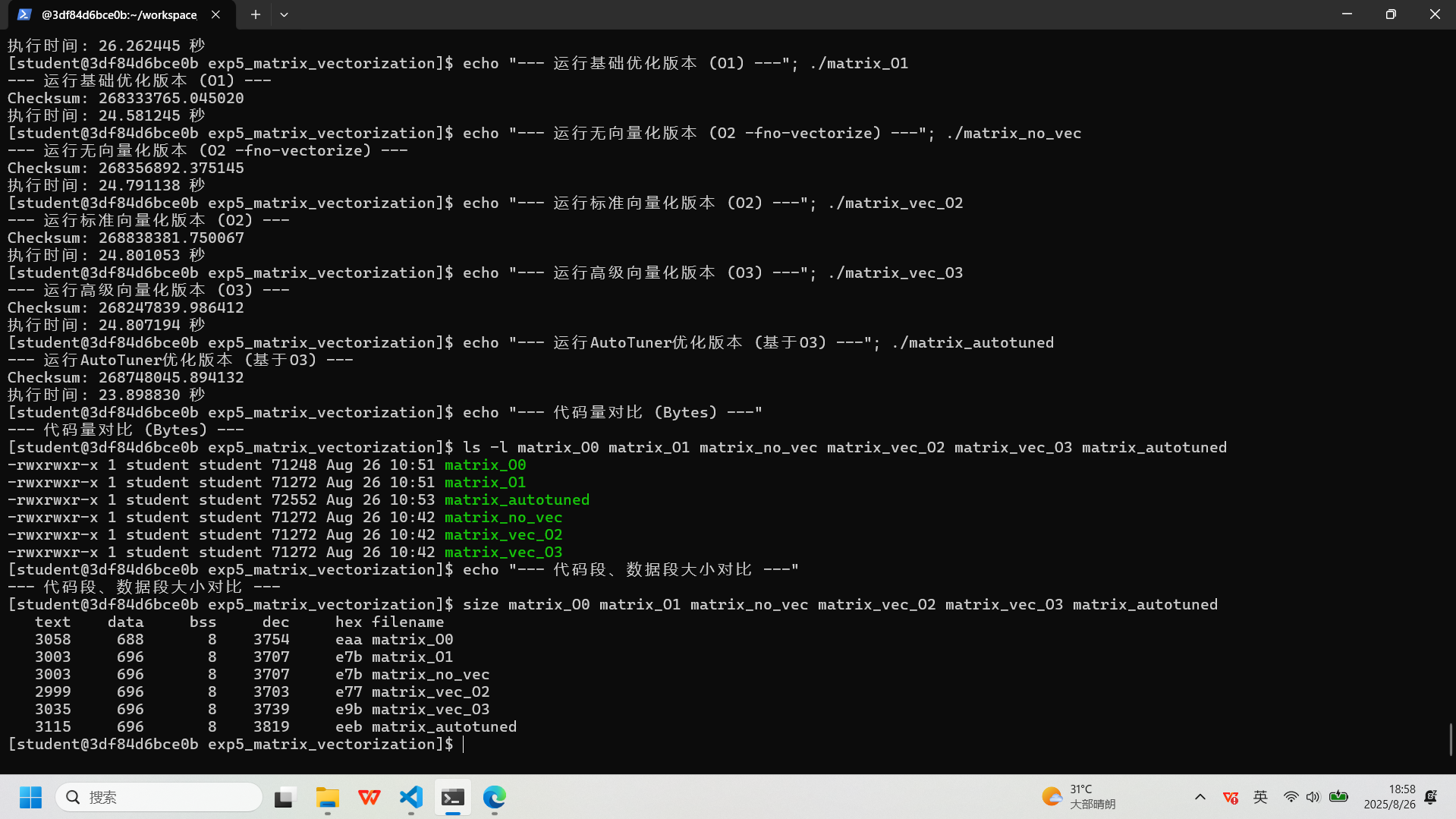
-
(三)结果分析
:结果汇总表
评测指标 无优化版 ( matrix_O0)基础优化版 ( matrix_O1)常规优化版 ( matrix_no_vec)标准向量化版 ( matrix_vec_O2)高级向量化版 ( matrix_vec_O3)AutoTuner 优化版 编译选项
-O0-O1-O2 -fno-vectorize-O2-O3-O3+ Autotuner执行时间 (秒)
26.262 24.581 24.791 24.801 24.807 23.899
性能对比 (相对-O0)
1.00x 快 1.07 倍 快 1.06 倍 快 1.06 倍 快 1.06 倍 快 1.10 倍
文件总大小 (Bytes)
71,248 71,272 71,272 71,272 71,272 72,552
代码段大小 (text)
3,058 3,003 3,003 2,999
3,035 3,115
1. 性能差异与环境影响
各优化版本间执行时间差异极小,
matrix_no_vec与matrix_vec_O2几乎一致,未体现自动向量化的理论优势。根本原因是 QEMU 模拟环境的指令翻译开销远大于编译器优化带来的提升,掩盖了硬件级优化效果。
结论:性能评测必须在原生 ARM64 物理机上进行,才能真实量化自动向量化等高级优化的效果。
2. AutoTuner调优效果
AutoTuner 优化版在所有版本中性能最佳,比 O3 快约 3.7%,说明即使在模拟瓶颈下,AutoTuner仍能通过参数搜索挖掘出标准优化之外的性能空间。
3. 代码量变化
AutoTuner版本文件体积和
.text段最大,表明其采用了更复杂的优化策略。标准向量化版.text段最小,说明自动向量化有时能简化指令序列。4. 综合结论
- 测试环境对性能评测结果有决定性影响,模拟环境下无法有效展示编译器优化的真实威力。
- AutoTuner 能在标准优化基础上进一步提升性能,但会增加代码体积。
- 为了看到实际区别,建议在物理 ARM64 机器上进行实验,才能科学评估自动向量化和高级优化的实际效果。












这一切,似未曾拥有