



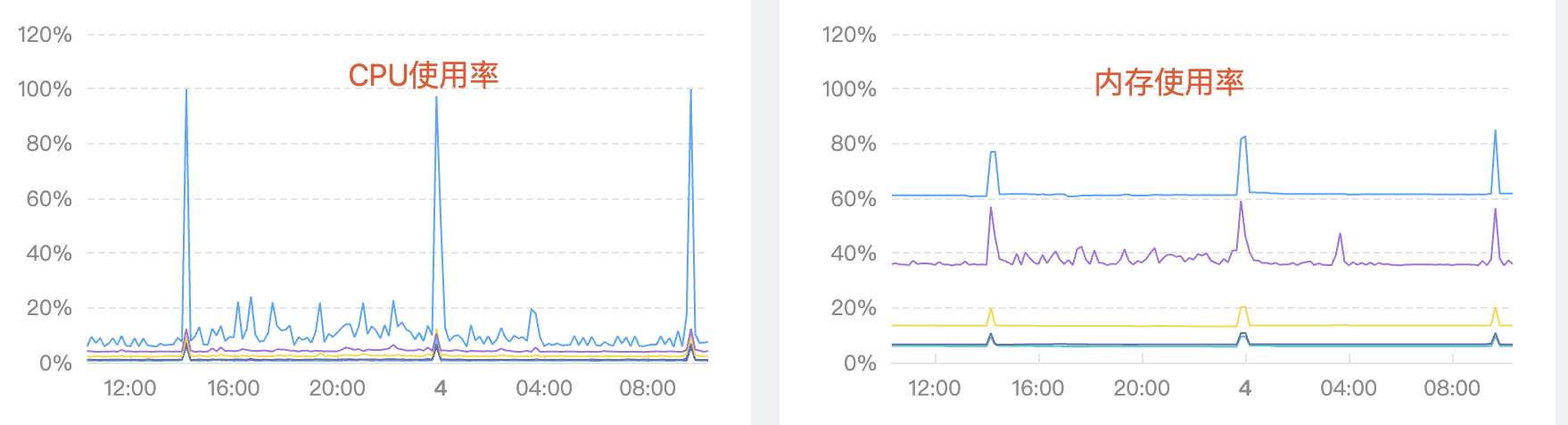
近期发现,k8s apiserver的内存和cpu定时(每隔10h)被客户一个控制器打的很高,有个小突刺。排查发现,用户的控制器开启了resyncPeriod,默认值就是10h。
一般来说controller runtime框架、knative框架,都会默认这个值为10h。不同的是,controller runtime框架会打算到10h附近,而knative框架是严格10h。当然真实时间会受到上次执行的影响,略有偏差。
定位到问题后,解决起来也很简单,构建informer时,将resyncPeriod设置为0就行。
但是,客户有担心,偶发k8s里面缓存不够新的问现象,担心关闭resyncPeriod会影响到informer机制中缓存的更新。第一反应,客户是不是对ResyncPeriod这个参数有什么误解?这个参数不会重新到APIServer拉取全量数据,而只是把indexer里面的缓存的所有key list一遍,重新推进DeltaFIFO,触发controller将所有事件重新调协一遍。
顺带把整个informer机制相关的debug一遍,确认无误。此处粘贴一些图做些记录。
1. Informer机制各种类详细介绍
https://blog.imoe.tech/2023/02/15/kubernetes-informer-mechanism/
这篇写得非常好。
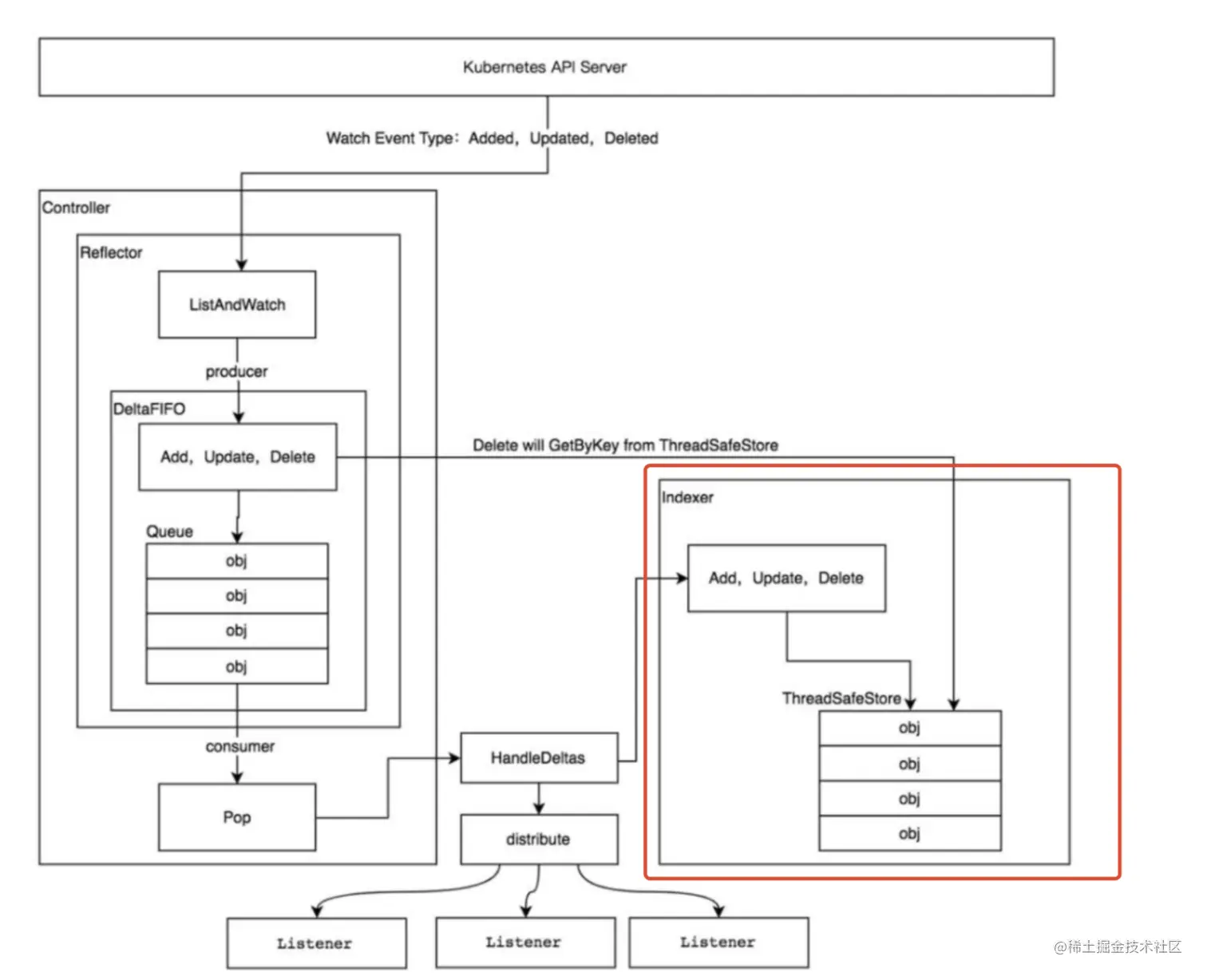
网上有大量文章,写的并不准确。包括ResyncPeriod参数,竟然把它说成可以重新从K8S APIServer全量拉取informer数据,更新informer缓存,避免watch机制错误导致缓存数据的不一致。这些文章给我带来了很大的干扰。所以我不断调整ResyncPeriod,debug测试。发现控制器并没有根据ResyncPeriod参数,去LIST K8SAPISERVER更新整个缓存;而只是从indexer的ThreadSafeMap里,list所有的key,重新推入DeltaFIFO,触发事件,让控制器重新handler。
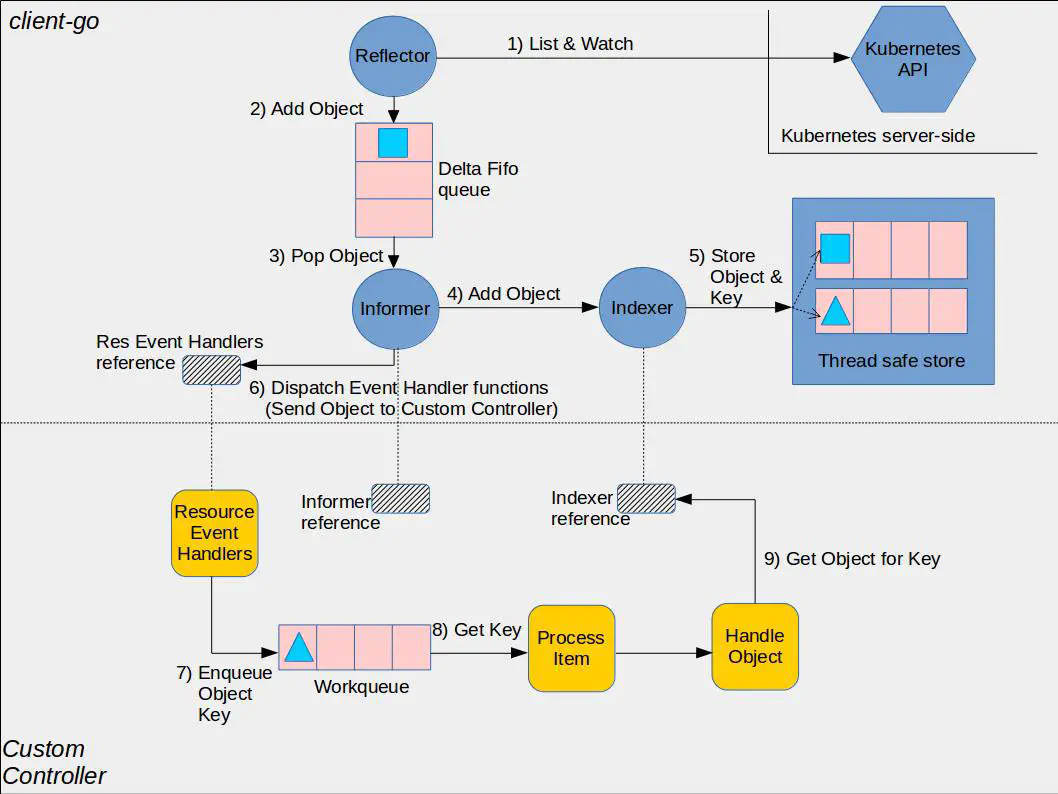
client-go 组件
- Reflector:指的是
cache包中定义的 Reflector 类,用于监控 Kubernetes 资源变化,其功能由ListAndWatch函数实现。当 Reflector 接收到资源变更的事件,会获取到变更的对象并在函数watchHandler中放到Delta Fifo队列。 - Delta FIFO:是一个 FIFO 的队列,用来缓存
Reflector拉取到的变更事件和资源对象; - Informor:是流程中最重要的节点,是整个流程的桥梁,
Informer也是在cache包中定义的,其功能在processLoop函数中实现,负责:- 从 Delta FIFO 中 pop 出对象并更新到 Indexer 的 cache 中;
- 调用自定义 Controller,传递该对象。
- Indexer:指在
cache包中定义的 Indexer 类,主要是在资源对象上提供了索引和本地缓存的功能。经典的使用场景是基于对象的 Labels 创建索引,Indexer 可以支持使用索引函数来维护索引,同时 Indexer 使用线程安全的 Data Store 来存储资源对象和对应的 Key。默认使用的是cache包里的 MetaNamespaceKeyFunc 函数来生成对象的 Key,格式如:<namespace>/<name>。
自定义组件
上图中 Informer reference 和 Indexer reference 是指在自定义 Controller 中需要自己创建的 Informer 和 Indexer 的实例,用来与整个流程进行交互,需要根据需要的资源创建对应的实例。client-go 提供了 NewIndexerInformer 函数来创建 Informer 和 Indexer 实例,也可以使用 SharedInformerFactory 的工厂方法来创建实例。
每个资源都会对应一个 Informer,每个 Informer 都通过 Watch 创建一个长连接。如果一个资源创建了多个 Informer 无疑是非常浪费的,所以通常都使用 SharedInformerFactory 工厂方法来创建,这样每种资源都复用一个 Informer,从而降低开销。
不过,各位可能有个小小的疑问,客户每10h全量调协处理一遍数据,正常应该客户的pod cpu和内存打得很高,为什么会K8S APIServer也被打得高?
这里面客户有个错误用法,他没有进行事件过滤,正常来说,重新全量调协,是要处理那些需要处理的数据,不需要的应该用EventHandler过滤掉。客户没有做,导致每个事件,他都会调协处理,处理逻辑里面有大量list资源的操作(list加了labelSelector条件), 导致K8S APIServer缓存打得很高。
不过,在协助处理客户这个问题时,我也有点小小的疑惑:
前期客户的处理逻辑里面有大量list资源操作,甚至部分没有加resourceVersion=0(直查etcd)。这种情况下,把K8S APIServer内存打得很高,可以理解。
但是后面用户把全部list操作加上resourceVersion=0后,仍然会把K8S APIServer打得很高,这个就很奇怪。K8S APIServer在接受list请求时,直接从内存里面拿数据,为何会内存瞬间打得很高?难道针对大量list请求操作,它瞬间产生大量的局部变量?看来得看看k8s相关代码,才能解答。













这一切,似未曾拥有