



作者: vivo 互联网大前端团队- You Chen
本文介绍可以在微信小程序上应用的端智能技术方案,聚焦 TensorFlow.js 推理和微信原生推理,详细讲解这两种方案在项目中的应用过程,为小程序开发者提供可复用的端智能技术选型策略与工程化解决方案。
1分钟看图掌握核心观点👇
本文提供配套演示代码,可下载体验:
Github | weixin-mini-ai
一、背景
随着AI浪潮的到来,各行各业都在利用AI赋能自身的业务,我们在vivo+云店项目上也进行了端智能探索,并成功应用到个性化商品推荐业务上,小程序端直接本地调用AI模型进行商品推荐,上线后商品点击率提升了30%,取得了不错的业务效果,接下来介绍如何让微信小程序具备端智能能力。

二、技术选型
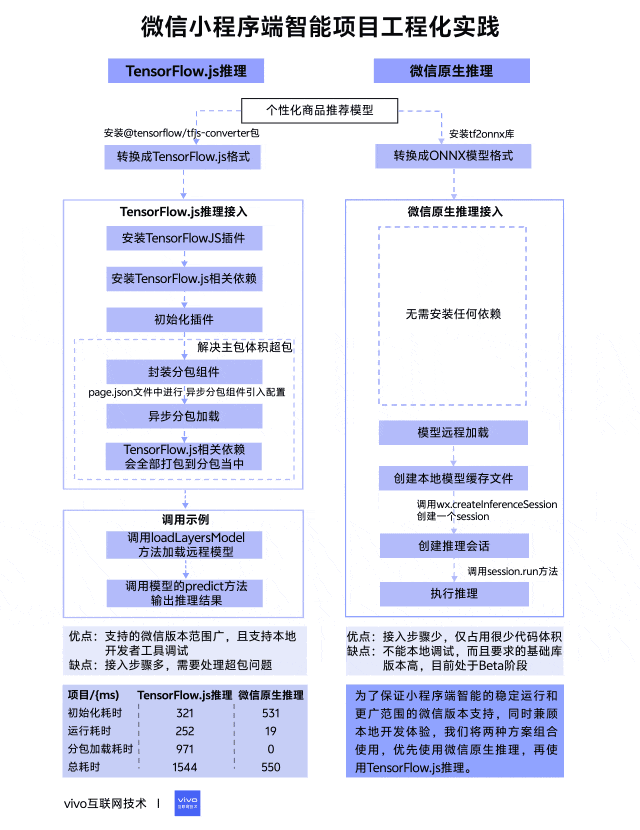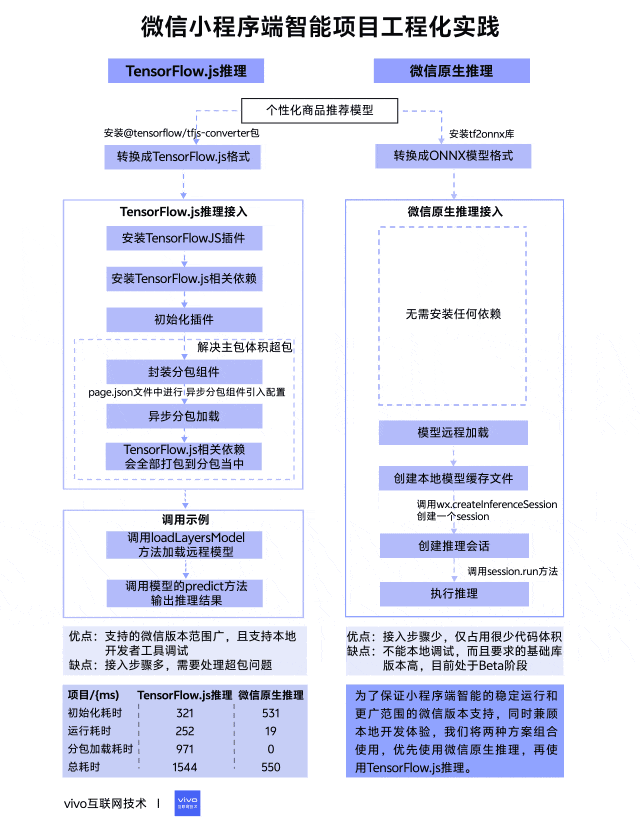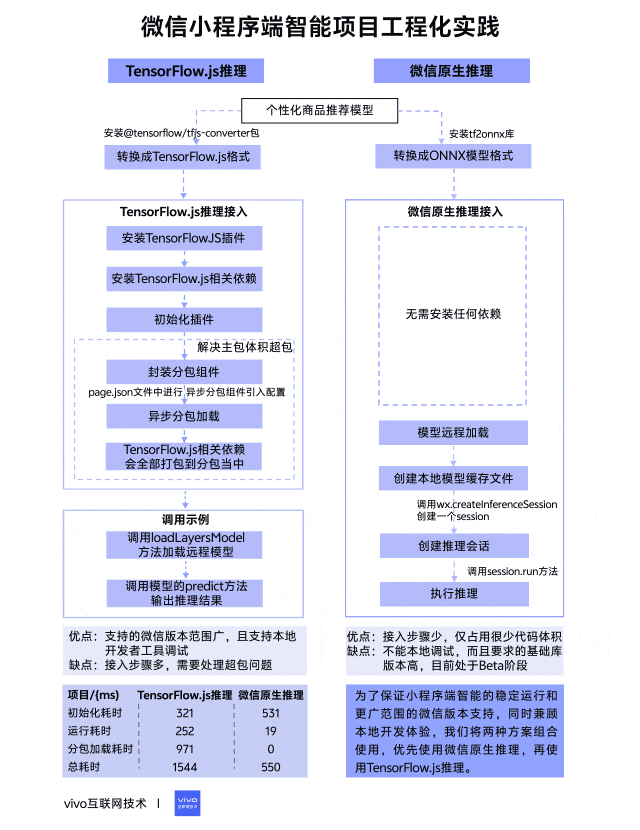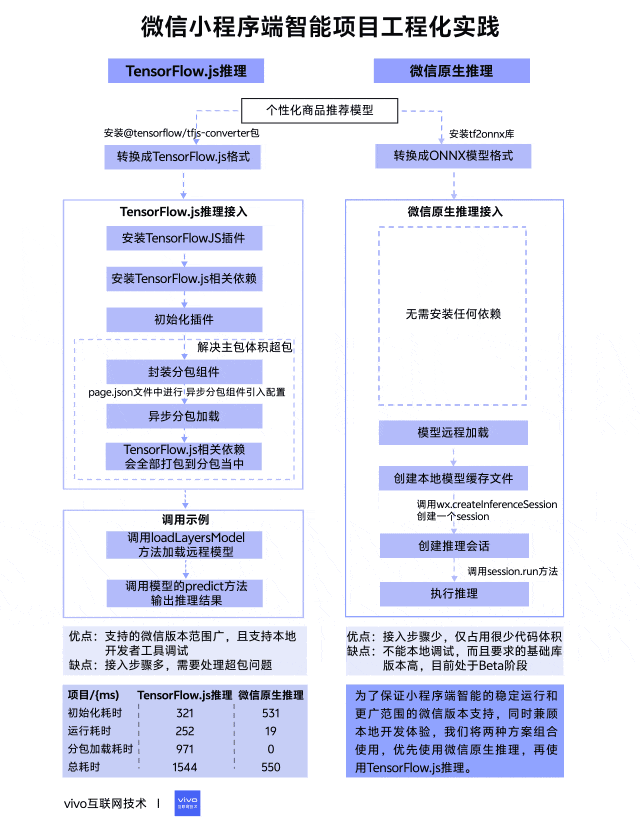
在项目启动之前我们进行了相关技术调研,发现完备的微信小程序端智能方案并不是很多,最终锁定了 TensorFlow.js 推理和微信原生推理这两种方案,它们有着相对完善的说明介绍,整体对比如下表所示。
2.1 TensorFlow.js 推理
TensorFlow.js 是谷歌开发的机器学习开源项目,致力于为Javascript提供具有硬件加速的机器学习模型训练和部署,在小程序端以插件的方式封装了TensorFlow.js库,方便小程序进行调用,同时需要配合安装相应的TensorFlow.js npm包来使用,接入步骤相对繁琐,但支持更低的微信基础库版本。

2.2 微信原生推理
微信原生推理是指调用小程序AI通用接口来进行推理,它是一套官方提供的通用AI模型推理解决方案,开发者无需关注其内部实现,只需要提供训练好的ONNX模型,小程序内部就可以自动完成推理。该方案接入步骤很少,目前还处于Beta阶段,所需要的微信基础库版本更高。

三、项目接入
技术方案选定好以后进入到项目接入环节,接下来将会分别介绍 TensorFlow.js 推理和微信原生推理方案的接入细节以及在项目接入过程中遇到的一些问题。
3.1 模型处理
在开始之前需要准备一个训练好的个性化商品推荐模型,本次模型是基于TensorFlow框架来进行训练的,模型训练完保存的格式是默认的SavedModel格式,但这个格式无法在小程序上直接使用,还需要进行相应的格式转换。
3.1.1 TensorFlow.js 格式
如果使用TensorFlow.js推理方案,要将SavedModel格式转换成TensorFlow.js格式,可以安装@tensorflow/tfjs-converter包,这个包专门用来将TensorFlow模型格式转换成Web端可加载的TensorFlow.js格式,具体转换命令如下:
tensorflowjs_converter --input_format=keras_saved_model output output/tfjs_model执行命令后会生成model.json模型拓扑文件和后缀为.bin的二进制权重文件。
3.1.2 ONNX 格式
如果使用微信原生推理方案,同样要将SavedModel格式转换成ONNX模型格式,可以安装tf2onnx库,这个库可以将TensorFlow模型格式转换成ONNX模型格式,具体转换命令如下:
python -m tf2onnx.convert --saved-model output --output output/model.onnx执行命令后会生成一个后缀为.onnx的文件。
3.1.3 模型更新
通过前面的操作得到了不同格式的模型文件,我们将这些模型文件放到静态资源服务器上,小程序端远程加载模型文件,需要注意模型需要定期用最新的数据进行训练更新,因此在获取模型链接时我们通过服务端接口来获取,方便随时进行更新。
3.2 小程序AI能力封装
小程序端相对于其它端有很大的不同,小程序代码包体积受限,单个包体积不能超过2MB,因此在设计AI模型调用方案时需要考虑到代码体积问题。vivo+云店项目是基于uniapp框架开发的小程序,接下来介绍不同推理方案的接入细节。
3.2.1 TensorFlow.js推理接入
TensorFlow.js 推理在接入之前需要在小程序管理后台安装一下TensorFlow.js插件,直接搜索wx6afed118d9e81df9即可完成添加:

接着在项目代码仓启用该插件,并安装TensorFlow.js相关依赖,可以按需加载必要的依赖,本次项目使用了tfjs-core、tfjs-layers、tfjs-backend-webgl和fetch-wechat这几个包。安装完相关依赖以后,还需要初始化插件:
const plugin = requirePlugin('tfjsPlugin') plugin.configPlugin({ // polyfill fetch function fetchFunc: fetchWechat.fetchFunc(), // inject tfjs runtime tf, // inject webgl backend webgl, // provide webgl canvas canvas: wx.createOffscreenCanvas() })初始化完成以后就可以加载使用模型了,然而在小程序打包上传的时候提示主包体积严重超包,原因是TensorFlow.js相关依赖包体积太大了,达到了1.3MB左右,严重影响了正常的业务代码体积,因此还要解决超包问题。我们最终采用了分包异步加载的方式将相关依赖剥离出主包,具体步骤如下:
(1)封装分包组件
将TensorFlow.js相关依赖的引入和插件初始化逻辑封装到分包组件当中,采用事件传递的方式将引入的TensorFlow模块传递给父页面。
// 组件路径/sdkPackages/tensorflow/index <template> <div></div> </template> <script> import * as tf from '@tensorflow/tfjs-core' import * as tfLayers from '@tensorflow/tfjs-layers' ... export default { mounted() { this.initTf() }, methods: { initTf() { // 插件初始化 ... // 将引入的依赖模块以事件的方式抛出 this.$emit('start', { tf, tfLayers }) } } } </script>
(2)异步分包加载
封装的组件想要在父页面中进行异步分包加载,还需要在page.json文件中进行异步分包组件引入配置,设置完成以后直接在父页面里使用即可,具体配置如下:
{ "path": "pages/demo/index", "style": { "navigationBarTitleText": "demo", "componentPlaceholder": { "tf-com": "view" }, "usingComponents": { "tf-com": "/sdkPackages/tensorflow/index" } } }需要注意,父页面获取的异步分包组件传递的事件值和普通Vue组件传递的事件值不太一样,需要在 e.detail.args[0]中获取到。
<template> <div> <!-- 父页面引入分包异步组件 --> <tf-com @start="startTf"></tf-com> </div> </template> <script> export default { methods: { startTf(e) { //获取子组件传递的Tensorflow模块 const { tf, tfLayers } = e.detail.__args__[0] .... } } } </script>完成上面两个步骤,TensorFlow.js相关依赖会全部打包到分包当中,不会占用主包体积。
到这里 TensorFlow.js 推理相关准备已全部完成,以下是调用示例,主要分为两个阶段:
-
模型加载
:调用loadLayersModel方法加载远程模型 -
模型推理
:调用模型的predict方法输出推理结果
export class TfModel { modelUrl modelName model hasInited = false constructor({ modelUrl, modelName, spuIdList}) { this.modelUrl = modelUrl this.modelName = modelName } // 模型加载 async load() { this.model = await tfLayers.loadLayersModel(this.modelUrl) this.hasInited = true } // 模型推理 async run(inputList) { const prediction = this.model.predict(tf.tensor([inputList])) const values = await prediction.array() console.log('模型推理结果:', values) } }由上可以看出TensorFlow.js推理方案缺点是接入步骤挺多,需要处理超包问题,但优点是支持的微信版本范围广,更重要的是它支持本地开发者工具调试。看到这里可能有人会疑问为什么支持本地调试也是优点?继续往下看就能得到答案。
3.2.2 微信原生推理接入
微信原生推理方案不需要安装任何依赖,仅使用微信提供的API即可完成模型调用,以下是调用示例:
export class OnnxModel { modelUrl modelName session hasInited = false// 模型是否初始化完成 constructor({ modelUrl, modelName }) { this.modelUrl = modelUrl this.modelName = modelName }, // 模型加载初始化 load() {...}, // 创建推理会话 createInferenceSession(modelPath) {...}, // 推理运行 run(inputList) {...} }整个模型加载推理分为下面
3个阶段
:
(1)模型加载初始化
模型先远程加载,下载到本地同时创建模型缓存文件,当二次加载时会查看本地是否有缓存的模型文件,如果有缓存就直接使用缓存数据。
load() { return new Promise((resolve, reject) => { const modelPath = `${wx.env.USER_DATA_PATH}/${this.modelName}.onnx` // 判断之前是否已经下载过onnx模型 wx.getFileSystemManager().access({ path: modelPath, success: () => { // 模型有本地缓存 // 创建推理会话 this.createInferenceSession(modelPath) ... }, fail: (res) => { // 远程加载onnx模型 wx.downloadFile({ url: this.modelUrl, success: (result) => { wx.getFileSystemManager().saveFile({ tempFilePath: result.tempFilePath, filePath: modelPath, success: (res) => { // 创建推理会话 const modelPath = res.savedFilePath this.createInferenceSession(modelPath) ... }, fail: (err) => { reject(err) } }) } fail: (err) => { reject(err) } }) } }) })
(2)创建推理会话
模型加载完以后调用wx.createInferenceSession创建一个session用来模型推理。
createInferenceSession(modelPath) { return new Promise((resolve, reject) => { this.session = wx.createInferenceSession({ model: modelPath }) // 监听error事件 this.session.onError((error) => { reject(error) }) this.session.onLoad(() => { resolve() }) }) }需要注意,在实际代码调试时发现本地开发者工具目前还不支持该API,只能真机调试。

(3)执行推理
创建好session以后就可以执行模型推理了,直接调用session.run方法即可。
async run(inputList){ const input = { type: 'float32', shape: [1, 8], data: new Float32Array(inputList).buffer } const res = await this.session.run({ input }) console.log('onnx模型推理结果:', Array.from(new Float32Array(res.output.data))) }到这里微信原生推理方案也介绍完了,可以看出它的优点是接入步骤很少,仅占用很少代码体积,但它的缺点也很明显,不能本地调试,而且要求的基础库版本高,目前处于Beta阶段,还不清楚线上不同系统机型是否都支持。
3.3 组合调用
为了保证小程序端智能的稳定运行和更广范围的微信版本支持,同时兼顾本地开发体验,我们将两种方案组合起来使用,优先使用接入简单的微信原生推理,其次使用TensorFlow.js 推理。调用示例如下:
async initAI(){ if (wx.canIUse('getInferenceEnvInfo')) { // 基础库满足微信原生推理 await new Promise((resolve) => { wx.getInferenceEnvInfo({ success: async () => { // 调用微信原生推理 ... resolve() }, fail: (res) => { // 调用TensorflowJS推理 ... resolve() } }) }) } else if(checkVersion()){ // 检查基础库版本,符合条件调用TensorflowJS推理 ... } else { // 不支持端智能,兜底处理 ... } }通过调用微信getInferenceEnvInfo方法可以获取通用AI推理引擎版本,如果当前手机支持微信原生推理就会触发成功的回调,否则会触发失败的回调,如果基础库不支持微信原生推理就会去判断是否满足TensorFlow.js推理调用条件,通过这样的方式动态选择当前手机支持的推理方式,如果都不支持就走兜底处理方案。通过该方式,线上90%以上的用户成功走到了端智能场景。
3.4 性能效果
当小程序端智能能力正式上线以后,推荐设计一些埋点监控模型推理执行的性能效果,包括模型推理运行各阶段耗时和模型推理异常日志,方便后续的迭代优化。
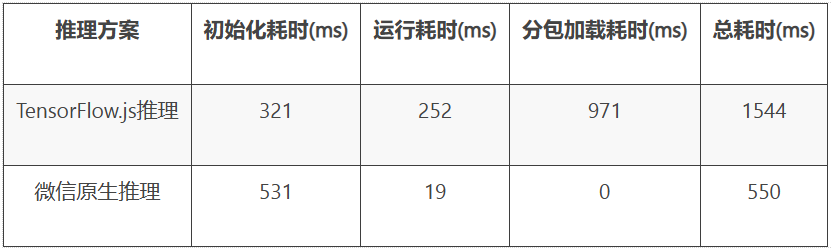
上表是业务上线后两种推理方案的各阶段平均耗时,我们使用的模型大小在110KB左右,从数据表现来看微信原生推理方案性能更好,总耗时仅需要550ms,而TensorFlow.js推理方案总耗时多是因为需要加载异步分包组件,当然可以考虑设置分包预加载来减少前置等待。
四、总结
整体回顾一下,本文介绍了两种可以在微信小程序上落地实施的端智能工程化解决方案:TensorFlow.js推理和微信原生推理,在项目接入过程中针对以下几个方面进行了处理:
-
模型格式
:一键命令格式转换,适配不同推理方案 -
代码包体积
:异步分包加载,解决TensorFlow.js相关依赖超包问题 -
开发体验、支持范围
:组合两种方案,保障开发体验,最大化覆盖微信版本范围
希望本文采取的方案以及处理的问题对你进行小程序端智能技术选型有所帮助,也欢迎在评论区一起交流其它可行性方案。














这一切,似未曾拥有