


1 功能初体验
1.1 分析实例
仍以之前的vectorAdd程序为分析目标,在新建的工程中只指定编译好的可执行文件及其输出report文件,其他部分都保持默认,然后直接点击“Launch”进行分析。

图1 Launch界面
运行完毕后生成如下分析结果:

先整体介绍下report结果:
1. 基础信息(顶部栏)
首先是内核名称:vectorAdd,向量加法内核;接下来是核函数的执行Size,Grid Size(196, 1, 1),即网格维度,共196个线程块,Block Size(256, 1, 1),即块维度,每个线程块256个线程,总线程数196*256=50176,其中有176个闲置线程,因为源码中numElements值为50000,只要5万个线程;再接下来是时间指标Time,内核执行总时间是3.97 us,微秒级;Cycles是GPU核心执行内核函数所消耗的时钟周期数,这里为6059个周期;GPU是运行当前可执行程序的显卡,即NVIDIA GeForce RTX 4060 Laptop GPU(移动版 RTX 4060);SM Frequency是频率,1.52GHz,对应1个周期约为0.65789纳秒,乘于周期数6059,则为3986ns,和之前Time 3.97us基本相等。
2. 性能指标(表格列)
Summary选项卡中给出了总结信息:
Estimated Speedup:性能优化潜力(理论加速比),60.45 表示最多可加速 60 倍,表明kernel还有较大改进空间
Function Name:内核函数名 vectorAdd,对应代码中的 __global__ void vectorAdd(...)
Demangled Name:符号解析后的名称(编译器相关,一般无需关注)
Duration:内核执行总时间
Runtime Improvement:运行时优化空间,2.40 表示可通过优化减少 2.4 倍运行时间
Compute Throughput:计算吞吐量 8.63(单位:GFLOP/s 或类似),反映计算密集度
Memory Throughput:内存吞吐量 39.00(单位:GB/s),反映内存访问效率
# Registers:每个线程使用的寄存器数量 16,属于比较低的寄存器占用
Grid Size: 196,1,1
Block Size: 256,1,1
3. 优化建议(底部警告)
报告提示了三个主要的性能优化方向:
(1)Achieved Occupancy(估计可提升 29.62%)
问题:理论最大 occupancy 为 100%,实际测量值只有 70.4%,低 occupancy 的原因可能是 warp 调度开销或 workload 不均衡。
优化方法:调整 block size / grid size,提升 SM 利用率;避免线程块间负载不均衡。
(2)Long Scoreboard Stalls(估计可提升 60.45%)
问题:平均每个 Warp 有 63.5 cycles 在等待 L1TEX(本地、全局、表面、纹理)数据返回,占总周期的 60.4%,即60.4%时间浪费在指令间的等待上。
优化方法:内存访问模式(合并访问、提高数据局部性),将高频使用的数据移到共享内存(Shared Memroy)。
(3)Tail Effect(尾部效应)
问题:一个 grid 的线程块不能整除 GPU 可并行调度的“波数”,导致最后一批 thread block 不能充分利用硬件资源,当前配置造成了 最多 50% 的执行浪费。
优化方法:尝试修改 grid size,使得 block 数量更接近硬件多处理器的倍数,增加 workload(更多线程块),避免出现“半波”执行。
以上分析表明vectorAdd kernel 在 RTX 4060 上的主要瓶颈是
内存访问延迟 (Long Scoreboard Stalls)
和线程调度不足 (Tail Effect + Occupancy 不高)
。1.2 解析
1. 关键点
(1)vectorAdd 本质上就是 memory-bound kernel
每个线程只做一次加法(几乎没有算术量),主要开销就是把 A[i],B[i] 从 global memory 读出来再将和C[i]写回去,GPU 的带宽利用率才是限制性能的瓶颈,而不是ALU。即使优化了寄存器或者调度,提升也非常有限。
(2)Long Scoreboard Stalls
Nsight 显示大部分时间在等 L1TEX(global load/store 的 scoreboard 依赖),vectorAdd 这种 pattern 不容易通过 cache 命中率优化来改善,因为几乎就是一次性读写。
(3)Occupancy ~71%(理论 100%)
Nsight 提示 Launch 配置(196 个 block × 256 线程)导致最后一个 "wave" 不满,tail effect 占了 50%,如果 grid size 和 GPU SM 数量不匹配,就会有一部分 SM 没有被充分利用。这里Wave是 GPU 调度的基本单位:在 AMD GPU中称为“Wavefront”(32 个线程),在 NVIDIA GPU 中对应 “Warp”(线程束,同样是 32 个线程)。
2. 优化
vectorAdd的 kernel 已经是 “最简单、最轻量”的形式,瓶颈在内存带宽。除非:
- 使用更大数据规模去真正压满GPU内存带宽
- 改用pinned memory + cudaMemcpyAsync pipeline做数据传输 overlap
- 改写 kernel,让每个线程做 更多计算(算力 bound 而不是带宽 bound)
否则vectorAdd程序的Nsight的报告不会显示太大差别。
(1)增大数据规模
增大向量个数,再 profile 看 memory throughput 是否接近 GPU 理论带宽,同时看下Report结果是否有变化。修改后程序如下:
#include <cuda_runtime.h> #include <stdio.h> #include <stdlib.h> #define N (1 << 26) // 64M elements,大约 256 MB 数据 #define THREADS_PER_BLOCK 256 __global__ void vectorAdd(const float* A, const float* B, float* C, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < n) { C[idx] = A[idx] + B[idx]; } } int main() { size_t size = N * sizeof(float); float* h_A, * h_B, * h_C; float* d_A, * d_B, * d_C; // ==================== 查询 GPU 理论带宽 ==================== cudaDeviceProp prop; int device; cudaGetDevice(&device); cudaGetDeviceProperties(&prop, device); double memClockMHz = prop.memoryClockRate * 1e-3; // kHz -> MHz double busWidthBits = prop.memoryBusWidth; // 位宽 (bits) double theoreticalBW = 2.0 * memClockMHz * (busWidthBits / 8.0) / 1000.0; // GB/s GDDR6 是 双倍速率 (DDR)
,所以要乘 2 printf("GPU: %s\n", prop.name); printf("Memory Clock: %.0f MHz, Bus Width: %.0f bits\n", memClockMHz, busWidthBits); printf("Theoretical Memory Bandwidth = %.2f GB/s\n\n", theoreticalBW); // 分配 host 内存 h_A = (float*)malloc(size); h_B = (float*)malloc(size); h_C = (float*)malloc(size); // 初始化数据 for (int i = 0; i < N; i++) { h_A[i] = 1.0f; h_B[i] = 2.0f; } // 分配 device 内存 cudaMalloc((void**)&d_A, size); cudaMalloc((void**)&d_B, size); cudaMalloc((void**)&d_C, size); // 拷贝数据到 device cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice); // 设置 kernel launch 配置 int blocksPerGrid = (N + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; // CUDA event 计时 cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start); // 启动 kernel vectorAdd << <blocksPerGrid, THREADS_PER_BLOCK >> > (d_A, d_B, d_C, N); cudaEventRecord(stop); cudaEventSynchronize(stop); float milliseconds = 0; cudaEventElapsedTime(&milliseconds, start, stop); // 计算实际带宽:每个元素读 A,B 并写 C (共 3 次访问) double totalBytes = 3.0 * size; // bytes double bandwidthGBs = (totalBytes / (milliseconds / 1000.0)) / 1e9; printf("VectorAdd size = %d elements\n", N); printf("Time = %.3f ms\n", milliseconds); printf("Effective memory bandwidth = %.2f GB/s\n", bandwidthGBs); // 清理 cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); free(h_A); free(h_B); free(h_C); return 0; } 编译后重新用Compute对程序进行分析,结果如下:
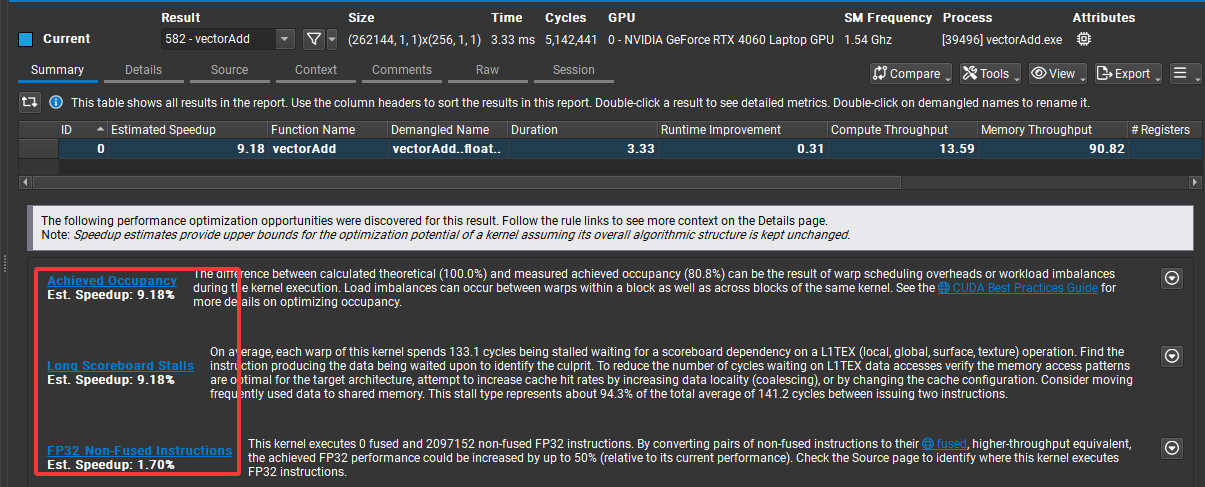
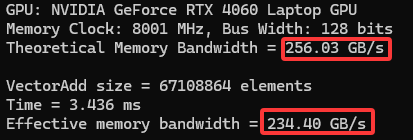
可以看出增大向量规模的情况下,程序可优化的空间已经大大减小,而且实际内存带宽利用率已经很接近理论值:
(2)pinned memory(页锁定内存)
默认 malloc 出来的 host 内存是 pageable(可分页)的,GPU 在拷贝时可能需要额外的staging(暂存缓冲区),速度会打折扣。用 cudaMallocHost() 或 cudaHostAlloc() 分配 页锁定内存,CUDA 就能直接 DMA 到显卡,带宽更高。另外cudaMemcpy 是阻塞的,拷贝完成前 CPU 会停在那里,cudaMemcpyAsync + stream 可以异步执行,拷贝和 kernel 可以 并行 overlap。最后借助Pipeline(流水线)技术,把大数据分成多块 (chunk),拷贝第 N 块时,GPU 可以同时计算第 N-1 块,实现计算与拷贝重叠,提升吞吐率。修改后程序如下:
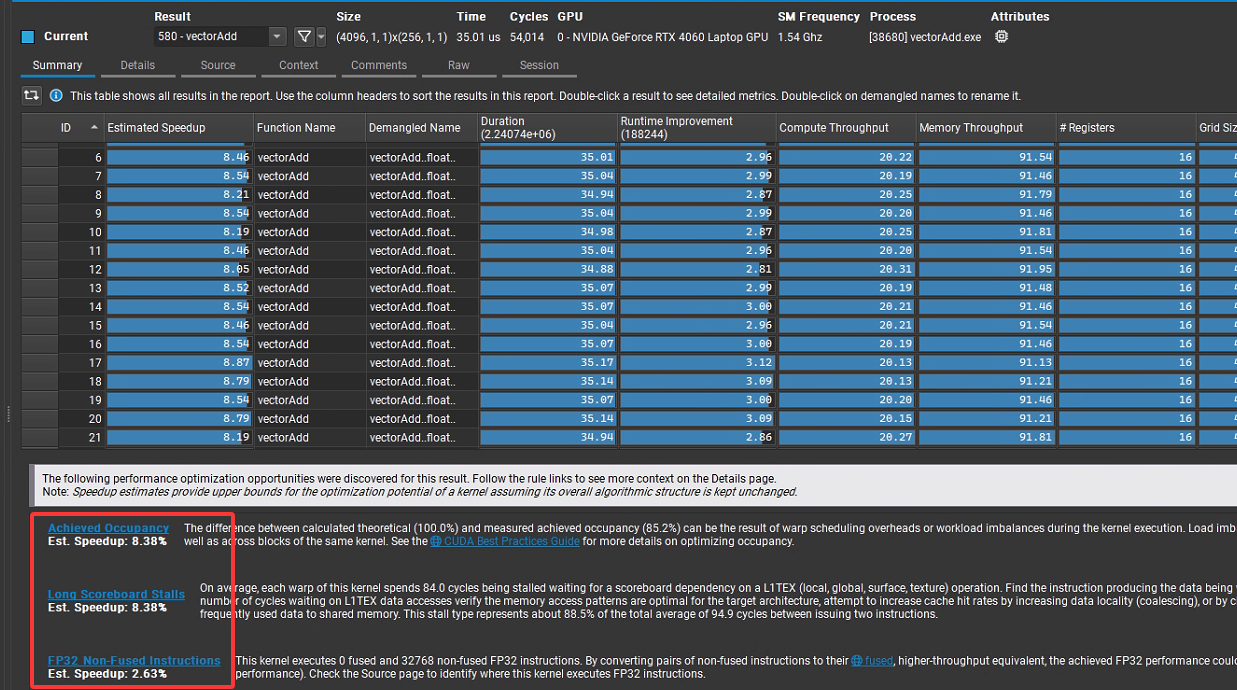
#include <cuda_runtime.h> #include <stdio.h> #define N (1 << 26) // 64M elements #define THREADS_PER_BLOCK 256 #define CHUNK_SIZE (1 << 20) // 每块 1M 元素 __global__ void vectorAdd(const float *A, const float *B, float *C, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < n) { C[idx] = A[idx] + B[idx]; } } int main() { size_t size = N * sizeof(float); // 使用 pinned host memory float *h_A, *h_B, *h_C; cudaMallocHost((void**)&h_A, size); cudaMallocHost((void**)&h_B, size); cudaMallocHost((void**)&h_C, size); for (int i = 0; i < N; i++) { h_A[i] = 1.0f; h_B[i] = 2.0f; } // device 内存(只分配一块 chunk 的大小) float *d_A, *d_B, *d_C; size_t chunkBytes = CHUNK_SIZE * sizeof(float); cudaMalloc((void**)&d_A, chunkBytes); cudaMalloc((void**)&d_B, chunkBytes); cudaMalloc((void**)&d_C, chunkBytes); // 创建 stream cudaStream_t stream; cudaStreamCreate(&stream); // 计时 cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start, 0); for (int offset = 0; offset < N; offset += CHUNK_SIZE) { int chunkElems = min(CHUNK_SIZE, N - offset); int blocks = (chunkElems + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; // 异步拷贝 H2D cudaMemcpyAsync(d_A, h_A + offset, chunkElems * sizeof(float), cudaMemcpyHostToDevice, stream); cudaMemcpyAsync(d_B, h_B + offset, chunkElems * sizeof(float), cudaMemcpyHostToDevice, stream); // 启动 kernel vectorAdd<<<blocks, THREADS_PER_BLOCK, 0, stream>>>(d_A, d_B, d_C, chunkElems); // 异步拷贝 D2H cudaMemcpyAsync(h_C + offset, d_C, chunkElems * sizeof(float), cudaMemcpyDeviceToHost, stream); } cudaEventRecord(stop, stream); cudaEventSynchronize(stop); float milliseconds = 0; cudaEventElapsedTime(&milliseconds, start, stop); printf("VectorAdd with pinned memory + async pipeline\n"); printf("Size = %d elements, Time = %.3f ms\n", N, milliseconds); // 校验结果 for (int i = 0; i < 10; i++) { if (h_C[i] != 3.0f) { printf("Error at %d: %f\n", i, h_C[i]); break; } } // 释放 cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); cudaFreeHost(h_A); cudaFreeHost(h_B); cudaFreeHost(h_C); cudaStreamDestroy(stream); cudaEventDestroy(start); cudaEventDestroy(stop); return 0; } 编译后重新用Compute对程序进行分析,结果如下:
(3)kernel计算复杂度提高
把算术强度 (Arithmetic Intensity, FLOPs/Byte) 提高——让每个线程在只读一次 A[i], B[i] 的前提下,做大量浮点运算(比如成千上万次 FMA),这样瓶颈就从“显存带宽”转移到“FP32 计算单元”,从而变成 compute-bound。源码如下:


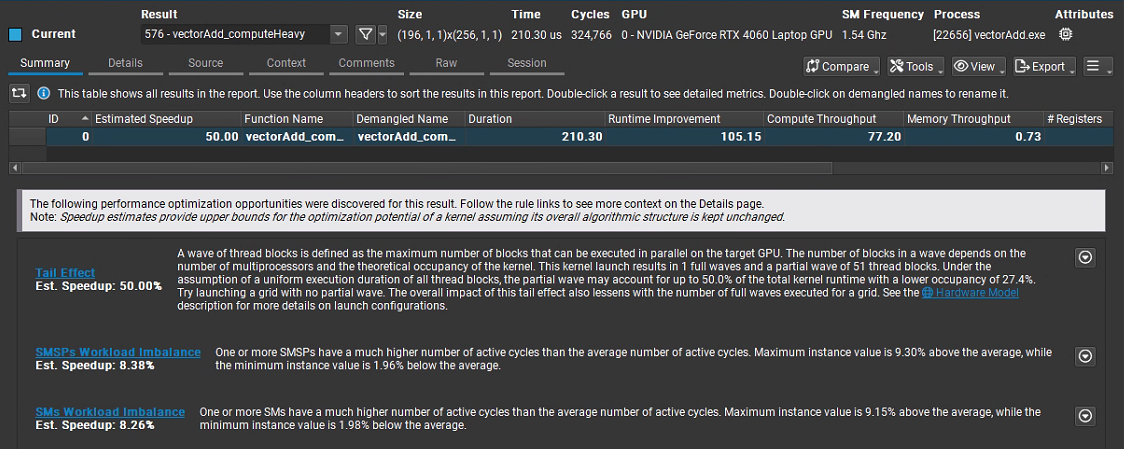
#include <stdio.h> #include <stdlib.h> #include <math.h> #include <cuda_runtime.h> //--------------------- 可调参数 --------------------- #define NUM_ELEMENTS 50000 #define TPB 256 // 每块线程数 #define WORK_ITERS 4096 // 每个元素的计算迭代次数(越大越 compute-bound) // 说明:本 kernel 每次迭代做 3 次 FMA(每次 FMA=2 FLOPs),所以每迭代=6 FLOPs //--------------------------------------------------- // 简单错误检查宏 #define CUDA_CHECK(call) do { \ cudaError_t err__ = (call); \ if (err__ != cudaSuccess) { \ fprintf(stderr, "CUDA error %s at %s:%d\n", \ cudaGetErrorString(err__), __FILE__, __LINE__);\ exit(EXIT_FAILURE); \ } \ } while (0) // 原始向量加法(保留以便对照/测试) __global__ void vectorAdd(const float* A, const float* B, float* C, int n) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) C[i] = A[i] + B[i]; } // 计算密集版:对每个元素执行大量 FMA(算力受限) __global__ void vectorAdd_computeHeavy(const float* A, const float* B, float* C, int n, int iters) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i >= n) return; // 只从全局内存取一次 float a = A[i]; float b = B[i]; // 累加器 float acc = 0.0f; // 让编译器展开一部分循环,提高指令吞吐 #pragma unroll 4 for (int k = 0; k < iters; ++k) { // 3 次 FMA;每次 FMA 记作 2 FLOPs acc = fmaf(a, b, acc); // acc += a*b acc = fmaf(acc, 1.000001f, 1e-7f); // 轻微扰动,避免常量折叠 b = fmaf(b, 0.9999993f, -1e-7f); // 变化寄存器值,避免被优化 } // 写回一次 C[i] = acc; } // CPU 端复现实验,验证正确性(与 GPU 相同的算法) void computeHeavy_cpu(const float* A, const float* B, float* C, int n, int iters) { for (int i = 0; i < n; ++i) { float a = A[i]; float b = B[i]; float acc = 0.0f; for (int k = 0; k < iters; ++k) { acc = fmaf(a, b, acc); acc = fmaf(acc, 1.000001f, 1e-7f); b = fmaf(b, 0.9999993f, -1e-7f); } C[i] = acc; } } int main() { const int N = NUM_ELEMENTS; const size_t bytes = N * sizeof(float); // Host 内存 float *hA = (float*)malloc(bytes); float *hB = (float*)malloc(bytes); float *hC = (float*)malloc(bytes); float *hRef = (float*)malloc(bytes); if (!hA || !hB || !hC || !hRef) { fprintf(stderr, "Host malloc failed\n"); return 1; } // 初始化 for (int i = 0; i < N; ++i) { hA[i] = (float)i * 0.001f + 1.0f; hB[i] = (float)i * 0.002f + 2.0f; } // Device 内存 float *dA, *dB, *dC; CUDA_CHECK(cudaMalloc(&dA, bytes)); CUDA_CHECK(cudaMalloc(&dB, bytes)); CUDA_CHECK(cudaMalloc(&dC, bytes)); CUDA_CHECK(cudaMemcpy(dA, hA, bytes, cudaMemcpyHostToDevice)); CUDA_CHECK(cudaMemcpy(dB, hB, bytes, cudaMemcpyHostToDevice)); // 启动配置 int blocks = (N + TPB - 1) / TPB; // 计时事件 cudaEvent_t start, stop; CUDA_CHECK(cudaEventCreate(&start)); CUDA_CHECK(cudaEventCreate(&stop)); printf("N=%d, TPB=%d, blocks=%d, WORK_ITERS=%d\n", N, TPB, blocks, WORK_ITERS); // --- 跑计算密集内核 --- CUDA_CHECK(cudaEventRecord(start)); vectorAdd_computeHeavy<<<blocks, TPB>>>(dA, dB, dC, N, WORK_ITERS); CUDA_CHECK(cudaEventRecord(stop)); CUDA_CHECK(cudaEventSynchronize(stop)); float msec = 0.f; CUDA_CHECK(cudaEventElapsedTime(&msec, start, stop)); // 统计 GFLOP/s: // 每元素 FLOPs = WORK_ITERS * 6(3 次 FMA × 2 FLOPs) const double flops_total = (double)N * WORK_ITERS * 6.0; const double gflops = (flops_total / (msec / 1e3)) / 1e9; // 统计内存访问字节:每元素只做 2 读 1 写(各 4B),总 12B const double bytes_total = (double)N * 12.0; const double bw_GBps = (bytes_total / (msec / 1e3)) / 1e9; printf("Kernel time: %.3f ms\n", msec); printf("Throughput: %.2f GFLOP/s (flops=%g)\n", gflops, flops_total); printf("Memory BW (effective for kernel body): %.2f GB/s\n", bw_GBps); printf("Arithmetic Intensity: %.2f FLOPs/Byte\n", (WORK_ITERS * 6.0) / 12.0); // 拷回结果并验证(CPU 端做同样的运算) CUDA_CHECK(cudaMemcpy(hC, dC, bytes, cudaMemcpyDeviceToHost)); computeHeavy_cpu(hA, hB, hRef, N, WORK_ITERS); // 随机抽查 int bad = -1; for (int i = 0; i < 10; ++i) { int idx = (i * 9973) % N; if (fabs(hC[idx] - hRef[idx]) > 1e-2f) { bad = idx; break; } } if (bad >= 0) { printf("Verification FAILED at %d: gpu=%f cpu=%f\n", bad, hC[bad], hRef[bad]); } else { printf("Verification PASSED (spot check)\n"); } // 清理 CUDA_CHECK(cudaFree(dA)); CUDA_CHECK(cudaFree(dB)); CUDA_CHECK(cudaFree(dC)); free(hA); free(hB); free(hC); free(hRef); CUDA_CHECK(cudaEventDestroy(start)); CUDA_CHECK(cudaEventDestroy(stop)); return 0; } View Code 为了能使得Compute快速分析,代码中又将向量个数改回50000,编译后运行结果如图所示,可见除了第一个我们已知原因的告警外,其他速度提升空间很有限:
2 界面详解
2.1 Launch界面
如第1节中的图1所示,图中上半部分内容显而易见不再进行说明,以下对下半部分内容进行说明。
1. Activity
支持四种分析模式:
Profile:
常规的性能分析模式,使用命令行分析器(command line profiler ),会序列化所有 GPU 工作负载(即按顺序分析 GPU 上的任务,便于精准采集每个 Kernel 等的性能数据 );“Attach is not supported for this activity” 表示该模式不支持 Attach 方式,只能通过 Launch 启动程序分析;“Supported APIs: CUDA, OptiX” 说明支持分析基于 CUDA(NVIDIA 通用并行计算架构)和 OptiX(光线追踪引擎)开发的程序。Interactive Profile:
交互式分析模式,相比常规 Profile ,能让你在分析过程中更灵活地探索数据,比如交互式查看不同 Kernel、不同指标的性能表现,进行实时的筛选、对比等操作。Occupancy Calculator:
专注于计算 GPU 内核(Kernel)的占用率相关指标,像活跃线程块数量、 warp 调度情况等,帮助你分析硬件资源利用是否充分,了解 Kernel 启动配置(如线程块大小等)对资源占用的影响 。System Trace:
系统级追踪模式,不仅关注 CUDA 程序本身,还会采集系统层面的事件,比如 CPU 线程调度、GPU 与 CPU 之间的数据传输时序等,用于分析程序在整个系统环境中与其他进程、硬件交互的性能瓶颈 。2. 分析具体配置
这里仅介绍最常用的Profile模式下的具体配置。
Output File:
设置性能分析结果文件的输出路径和命名规则,如D:\work\cuda\cuda-samples-12.5\bin\win64\Release\result%i,%i占位符可在生成分析结果时对report文件自动添加递增的标号,防止覆盖上一次的分析结果文件。Force Overwrite:
设置是否强制覆盖已存在的输出文件,选 Yes 则当输出路径下有同名文件时直接覆盖,选 No 则会提示文件已存在,需手动处理避免覆盖,如果在之前输出文件路径最后以增加%i,则该配置可忽略。Target Processes:
选择要分析的目标进程范围,All 会分析所有与指定应用程序相关联的进程,这不仅包括你主打的 CUDA 应用程序进程本身,还可能涵盖一些辅助进程,例如在应用程序运行期间启动的子进程等;这里还有另外一个选项Application Only,此选项下,Nsight Compute只会聚焦于指定的应用程序可执行文件所对应的主进程,会忽略掉在应用程序运行过程中启动的其他辅助进程,仅仅针对主应用程序的 GPU 活动、CPU - GPU 交互等进行性能分析。Replay Mode:
重放模式,这里有4种选项:- Application(应用程序)
- 重放范围:该模式会对整个应用程序的执行过程进行重放。它涵盖了从应用程序启动,到运行过程中执行的所有 CUDA 内核(Kernel)、CPU 与 GPU 之间的数据传输以及其他相关的计算和交互操作 。
- 适用场景:当你想要全面了解应用程序的完整执行流程和性能表现,排查可能影响整体性能的因素时适用。例如,分析一个复杂的深度学习训练应用程序,通过 “Application” 重放模式,可以观察到整个训练过程中数据加载、模型训练、参数更新等各个环节的性能情况,帮助发现诸如数据传输瓶颈、内核启动延迟等影响训练效率的问题 。
- Application+Range(应用程序 + 范围)
- 重放范围:在对整个应用程序执行重放的基础上,允许用户指定一个特定的范围进行更深入的分析。这个范围可以是应用程序执行过程中的某一段时间区间,或者是某些特定操作的集合 。用户可以先通过完整的应用程序重放,定位到性能问题可能出现的大致阶段,然后利用 “Application+Range” 模式,聚焦到这个特定范围进行详细分析。
- 适用场景:假设你在运行一个模拟应用程序时发现,在某个特定的计算阶段性能突然下降。这时可以先使用 “Application” 模式了解整体运行情况,确定问题出现的大致时间点或操作步骤,然后使用 “Application+Range” 模式,设置只重放出现问题的那个阶段,深入分析该阶段内内核的执行效率、资源使用情况等,更精准地定位性能瓶颈 。
- Kernel(内核)
- 重放范围:此模式专注于对单个 CUDA 内核的执行进行重放和分析。它会详细记录和重现每个内核的启动参数、线程执行情况、寄存器使用、内存访问等信息,而不关注应用程序中其他内核或非内核部分的执行情况 。
- 适用场景:当你需要对某个特定的内核进行调优时,“Kernel” 重放模式非常有用。比如,在开发一个 CUDA 并行计算程序时,发现某个特定的内核运行时间较长,通过 “Kernel” 重放模式,可以深入研究该内核的线程块(block)和线程(thread)的执行细节,分析寄存器溢出、内存访问冲突等问题,进而针对性地优化内核代码 。
- Range(范围)
- 重放范围:只对用户指定的某个特定范围进行重放。这个范围可以是应用程序执行过程中的一个时间片段,或者是一系列连续的内核执行操作 。与 “Application+Range” 不同的是,它不包含对整个应用程序的全面重放,只是单纯聚焦于用户划定的特定范围 。
- 适用场景:如果已知应用程序中某一段连续的计算操作存在性能问题,或者想要对比某几个内核在不同参数设置下的执行性能时,“Range” 模式就很合适。例如,在一个图像处理应用程序中,连续的几个图像滤波内核执行效率不高,使用 “Range” 模式,指定这几个内核执行的范围进行重放,能够快速对比不同滤波算法内核的性能差异,评估优化效果 。
Application Replay Match:
应用程序重放匹配方式,Grid 以线程网格(Grid,CUDA 中 Kernel 启动时的线程组织顶层结构 )为单位进行重放匹配,用于关联重放数据和原始程序的网格执行逻辑 。Application Replay Buffer:
应用程序重放缓冲区设置,File表示将重放相关的数据暂存到文件中,也可选择其他存储方式(如内存等,不同选项适配不同场景和性能需求 ),影响重放过程中数据的存储和读取效率 。Application Replay Mode:
应用程序重放模式,Strict 表示严格按照程序原始执行顺序、参数等进行重放,尽可能还原真实运行场景来分析性能,保证分析数据的准确性对应原始执行逻辑 。Graph Profiling:
图形分析配置,Node 以节点(可理解为 Kernel 或相关计算单元在性能分析图中的节点表示 )为单位进行图形化性能分析,用于构建、展示程序性能的拓扑结构,辅助识别性能关键路径 。Command Line:
显示最终执行性能分析的命令行内容,工具会根据你前面配置的各项参数,拼接成完整的命令行指令,用于调用底层的分析器(如 ncu.exe 等 NVIDIA 性能分析命令行工具 )执行分析。2.2 Result界面
1. Summary
这部分之前已经介绍过,不再详细说明。
2. Details
该部分内容最为全面,下面进行详细说明:
(1)GPU Speed Of Light Throughput(GPU光速吞吐量,也称为SOL分析)
含义:提供SM和内存利用率的概览,快速识别主要瓶颈。
用途:作为性能分析的起点,判断是计算还是内存受限。
场景:快速诊断程序性能瓶颈。
下图是最原始vectorAdd程序的分析结果,从图中柱状图可以直观的看出,Compute(SM) Throughput(计算吞吐量)代表 GPU 流多处理器(SM, Streaming Multiprocessors )计算资源的利用率,数值是 “实际计算性能 / 理论最大计算性能” 的百分比仅为9.21%,说明计算资源只用了不到10%,远没有触达GPU理论计算上限,计算资源还有较高的挖掘潜力。而对于Memory Throughput [%](内存吞吐量),即 GPU 内存子系统(含显存、缓存等)的带宽利用率,是 “实际内存带宽 / 理论最大内存带宽” 的百分比,在图中是41.11%,虽然内存带宽用了四成左右,但是也还有进一步优化空间。优化时首先应从这两个指标入手,其他指标在更以进一步优化时考虑。从这两个指标来看,可以认为memory throughput dominated,即计算受限,说明程序卡在GPU计算能力没有跑满,Kernel里计算逻辑简单,线程并行度不够,SM上的CUDA Core没有被充分利用,导致计算吞吐量上不去。如果要对该程序进行优化,方向就是增加kernel函数中的计算复杂度,同时增大向量规模,前者能使得CUDA Core尽可能的”忙碌“起来,后者会使得内存访问也变得更加频繁起来。

作为对比,可以看下上一节最后一个程序相应的分析结果,由于增加了kernel函数中计算复杂度,导致计算吞吐量显著增大,相对的内存访问反而更加”清闲“,导致其吞吐量进一步降低。需要说明的是这种情况仍是”计算受限“模型,因为在存储很清闲的情况下,”计算“仍没有被”喂饱“,所以是计算受限。

(2)PM Sampling(性能监控采样)
含义:通过性能监控 (Performance Monitoring) 采样,收集硬件计数器数据。
用途:提供实时性能数据,分析硬件级行为。
场景:深入分析硬件性能瓶颈。
以图中Average Active Warps Per Cycle指标为例,第2列中90.77 warp表示,在某个Cycle内平均活跃Warps达到kernel运行期间的最高水平90.77个,0表示纵轴最小值为0,从图中还可看出在kernel运行的不到4us内各个时刻的平均活跃Warp数是不同的,大体上成正态分布(两头少,中间多),对于这里使用的RTX 4060来说,maxThreadsPerMultiProcessor=1536,即每个周期活跃warp最大个数为1536/32=48,这里统计值竟然是90.77,暂时没搞清楚是怎么回事儿。
Total Active Warps Per Cycle是统计整个GPU范围内的活跃warp数1.09k,理论上RTX 4060中SM数是24,所以总的活跃warp数为24*48=1152,能看的出这里的值已经非常接近理论值,说明在warp调度层面已经达到较高的GPU利用率。

Blocks Launched = 144,是在采样周期内启动的block数,从图中可以看出block集中在早期启动,block启动后持续执行,不需要频繁启动新block。
SM Active Cycles = 1.55k cycle,是对所有 SM 处于活跃状态的时钟周期进行统计和累加,在 GPU 运行内核(Kernel)时,每个 SM 都有独立的调度器,负责管理线程束(warp)的执行。当 SM 内有可执行的 warp(比如 warp 没有因为等待内存数据、资源冲突等原因被阻塞 ),并且调度器给这些 warp 分配指令,让它们在计算单元(如 CUDA Core、FMA 单元等)上执行时, 这个 SM 就处于活跃状态,此时会记录一个活跃时钟周期,1.55k cycle是一个采样周期1us内活跃时钟cycle数。
Executed IPC Active = 366m inst/cycle,这里的 “m” 代表 “milli”(千分之一),所以366m = 0.366,在流多处理器(SM)处于活跃状态的每个周期内,平均执行了 0.366 条指令,这和Ada Lovelace 架构的理论 IPC(每周期指令数)约 4 - 5 左右相差甚远,所以说明从指令执行层面来说还有巨大优化空间。
再接下来,和SM相关指标:SM Throughput(流多处理器吞吐量)、SM ALU Pipe Throughput(SM整数和逻辑运算流水线吞吐量)、SM FMA Light Pipe Throughput(SM轻量浮点乘加流水线吞吐量,FP32)、SM FMA Heavy Pipe Throughput(SM重量浮点乘加流水线吞吐量,FP64)、SM Tensor Pipe Throughput(SM 张量核心流水线吞吐量)的值都比较低,如SM Throughput(SM 吞吐量)的实际数值最高仅约为 9.14%,远未达到左侧显示的 100%,这表明SM的大量计算资源处于闲置状态,没有被利用起来。

再之后的DRAM显存虽然也没有达到100%,但是在部分采样周期内已经达到88%,相比计算资源来说,利用率已经相对充分。
 再接下来的指标由于没有采样信息不再进行详细说明。
再接下来的指标由于没有采样信息不再进行详细说明。
(3)Compute Workload Analysis(计算工作负载分析)
含义:分析 SM 的计算工作负载,包括指令吞吐量、浮点运算效率等。
用途:评估 GPU 计算资源的利用率,识别计算瓶颈。
场景:优化矩阵计算或科学计算内核。
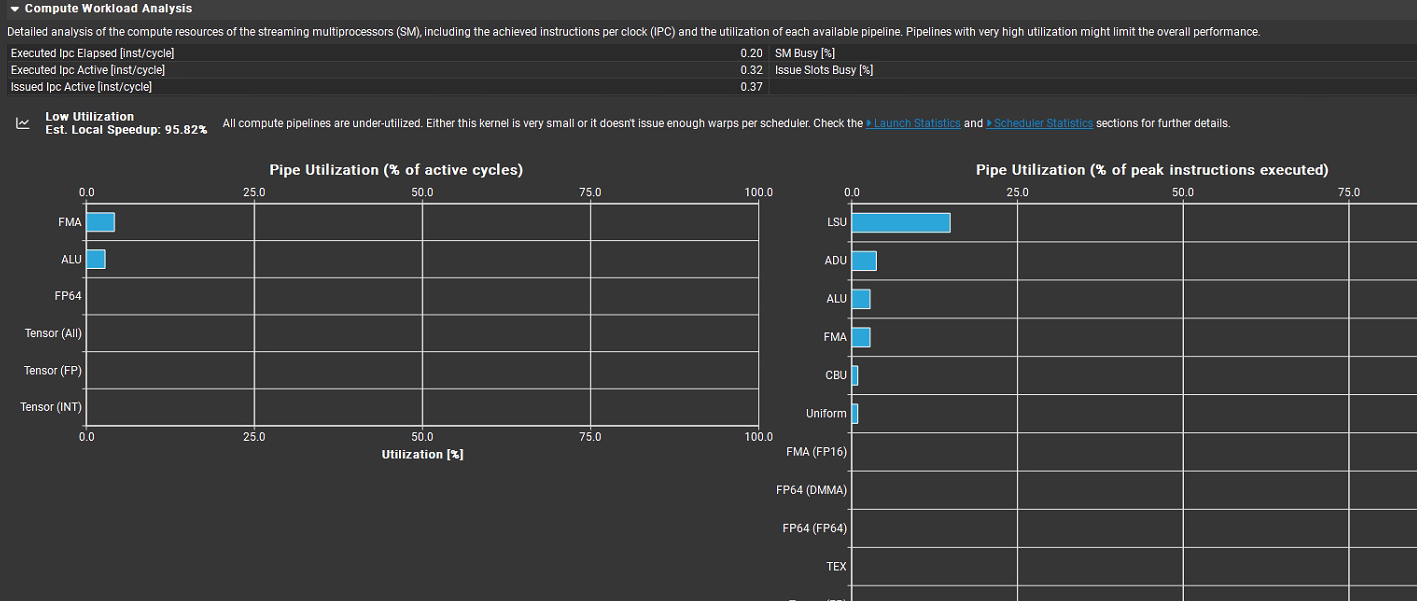
最上面核心指标:
Executed IPC Elapsed = 0.20 inst/cycle:在整个内核运行期间(包含空闲周期),平均每周期仅执行 0.2 条指令。
Executed IPC Active = 0.32 inst/cycle:在活跃周期内,每周期执行 0.32 条指令。对比 Ada Lovelace 架构理论峰值 ~8,这个利用率非常低。
Issued IPC Active = 0.37 inst/cycle:活跃周期内每周期发射(issue)的指令数是 0.37。和上面的 0.32 很接近,说明 pipeline 本身没有严重瓶颈,问题主要在并行度/指令密度不足。
SM Busy [%] = 0.20:SM 在总运行时间中只有 20% 的时间在忙碌,其余 80% 在空闲。
Issue Slots Busy [%] = 0.32:warp scheduler 的 issue 槽位利用率约 32%。调度器资源大部分时间闲置。
中间提示信息:
“所有计算管道都未充分利用(All compute pipelines are under-utilized)”,推测原因是 “内核非常小,或者每个调度器发出的 warp 数量不足”,并建议查看 “Launch Statistics” 和 “Scheduler Statistics” 部分获取更多细节。同时预估本地加速比(Est. Local Speedup)为 95.82%,说明有很大的性能提升空间。
下方 Pipe Utilization 图表:
左侧是活跃周期占比,FMA(浮点乘加)、ALU(整型算术)利用率只有个位数,Tensor Core、FP64、其他计算单元几乎完全空闲,说明这个 kernel 的算术指令极少。
右侧是峰值指令执行占比,LSU(加载 / 存储单元,内存访问管线)利用率相对最高,ADU、ALU、FMA 等有少量利用,其余如 CBJ(条件分支)、Uniform(统一操作)、各类 FP64 及 TEX(纹理单元)等利用率极低。说明这个 kernel 主要在做访存,几乎没有算术计算。
(4)Memory Workload Analysis(内存工作负载分析)
含义:分析内存工作负载,涵盖全局、共享、纹理和本地内存访问。
用途:识别内存访问瓶颈,如缓存未命中或非合并访问。
场景:优化内存访问模式,减少全局内存延迟。
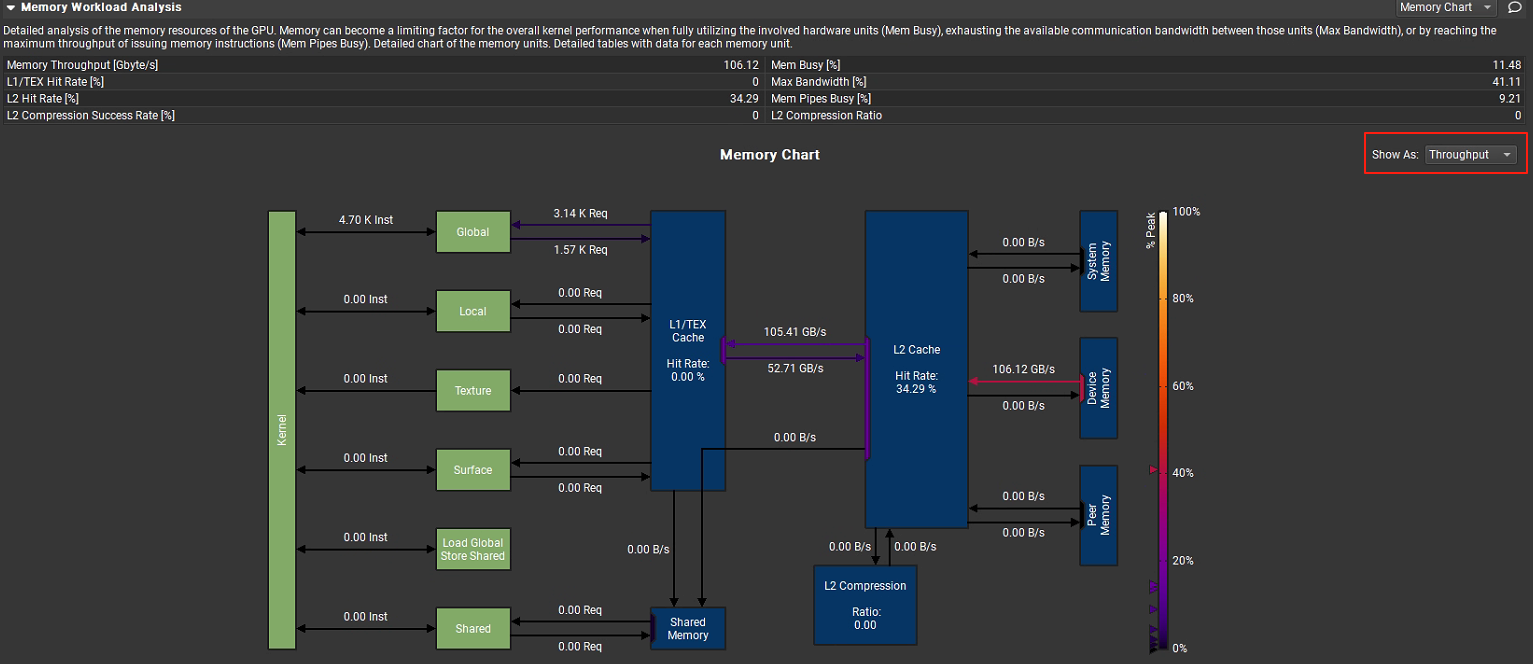
用于分析 GPU 内存资源的使用情况,当涉及内存硬件单元(Mem Busy)已经完全使用,各单元之间的最大通信宽带(Max Bandwidth)已经完全耗尽或者发射内存指令的管道(Mem Pipes Busy)已经达到最大吞吐量时,内存可能会成为整体kernel性能的限制因素。相关指标统计如下:
Memory Throughput [Gbyte/s]:106.12,即内存吞吐量为 106.12GB / 秒。
L1/TEX Hit Rate [%]:0.0,L1 缓存或纹理缓存的命中率为 0,说明从 L1 缓存或纹理缓存中获取数据的成功率极低。
L2 Hit Rate [%]:34.29,L2 缓存命中率为 34.29%,有一定比例的数据能从 L2 缓存命中。
Mem Busy [%]:11.48,内存总线忙碌程度为 11.48%,表示内存总线有 11.48% 的时间处于忙碌状态。
Max Bandwidth [%]:41.11,最大带宽利用率为 41.11%,说明内存带宽还有较大的利用空间。
Mem Pipes Busy [%]:9.21,内存管道忙碌程度为 9.21%,内存管道的使用并不充分。
L2 Compression Success Rate [%]:0,L2 缓存压缩成功率为 0,没有数据通过压缩节省空间。
L2 Compression Ratio:0,L2 缓存压缩比为 0,同样说明没有进行有效的压缩。
图中下方的内存图表直观的显示各关键部件之间的通信数据吞吐量,还可以通过左侧下拉列表切换查看总的传输大小。
(5)Scheduler Statistics(调度器统计)
含义:统计 warp 调度器行为,分析调度效率和暂停原因。
用途:定位调度瓶颈,如分支发散或资源竞争。
场景:优化 warp 调度,减少分支发散。
用于分析 GPU 指令调度器的工作情况,每个调度器维护一个 warp(线程束)池,可从中发射指令。warp 池的上限(Theoretical Warps)由启动配置限制。每个周期调度器会检查池中已分配 warp 的状态(Active Warps),未停滞的活跃 warp(Eligible Warps)可发射下一条指令,调度器从符合条件的 warp 中选择一个来发射一条或多条指令(Issued Warp)。若周期内无符合条件的 warp,发射槽会被跳过,无指令发射,大量跳过发射槽意味着延迟隐藏效果差。

上方核心指标
Active Warps Per Scheduler = 8.78:每个调度器平均有 ~8.8 个活跃 warp 在池子里,理论上限是 12 warp per scheduler,所以活跃 warp 数量还算可观(~73% 满载)。
No Eligible = 91.01:有91.01%的周期内没有符合条件的warp。
Eligible Warps Per Scheduler = 0.19:在这 8.78 个活跃 warp 里,平均只有 0.19 个 warp 处于“可立即发射指令”状态,换句话说,大多数 warp 虽然活跃,但被 stall(等待数据/资源) 卡住了。
One or More Eligible = 8.99:仅有 8.99% 的周期内有一个或多个符合条件的 warp。
Issued Warp Per Scheduler = 0.09:每个调度器每周期平均发射 0.09 个 warp,相当于 11.1 个周期才发射一次指令,调度效率非常低。
发射槽利用率(Issue Slot Utilization)
每个调度器每周期能发射一条指令,但当前内核每个调度器每 11.1 个周期才发射一条指令,这导致硬件资源未充分利用,性能不是最优。每个调度器最多可处理 12 个 warp,当前内核每个调度器平均分配 8.78 个活跃 warp,但每周期平均只有 0.19 个符合条件的 warp。没有符合条件的 warp 时,发射槽闲置。预估本地加速比(Est. Local Speedup)为 58.89%,说明有较大性能(59%)提升空间。Nsight Compute建议通过查看 “Warp State Statistics” 和 “Source Counters” 部分,减少活跃 warp 的停滞时间,以增加符合条件的 warp 数量。
调度器图表解读(Warps Per Scheduler)
GPU Maximum Warps Per Scheduler = 12:硬件上限,每个调度器最多可管理 12 个 warp。
Theoretical Warps Per Scheduler = 12:根据 kernel 配置(block 数、线程数),理论上最多能达到 12。
Active Warps Per Scheduler ≈ 8.78:实际运行中有 ~9 个 warp 活跃。
Eligible Warps Per Scheduler ≈ 0.19:活跃 warp 里,几乎都在等待(数据依赖、访存、同步等),只有不到 1 个 warp 真正 ready。
Issued Warp Per Scheduler ≈ 0.09:平均每 10+ 个周期才发射一次 warp,调度利用率极低。
综合分析,Warp并行度足够(8.78/12),说明block/warp数量是够的,但是几乎所有warp都在等待,从现象上看像是访存受限(memory-bound),实际上是因为kernel计算量太小,使得每次执行过程中好像时间都花费在等内存就位。
(6)Warp State Statistics
含义:详细统计 warp 状态(如等待内存、分支发散、活跃)。
用途:分析线程执行效率,定位 warp 级瓶颈。
场景:优化线程同步和分支逻辑。
用于分析 GPU 中 warp(线程束)在 kernel(内核)执行期间的状态,以找出性能瓶颈,相关信息如下:

核心指标
Warp Cycles Per Issued Instruction [cycle]:每条已发射指令对应的 warp 周期数,为97.67。该值越高,说明指令间延迟越大,需要更多并行 warp 来隐藏延迟。
Warp Cycles Per Executed Instruction [cycle]:每条已执行指令对应的 warp 周期数,为 115.61,反映指令执行的整体延迟情况。
Avg. Active Threads Per Warp:每个 warp 中平均活跃线程数,为 32,说明 warp 内线程基本都处于活跃状态。
Avg. Not Predicated Off Threads Per Warp:每个 warp 中平均未被谓词关闭的线程数,为 30.12,表明大部分线程未因谓词判断而不执行。
主要停滞类型
Stall Long Scoreboard:Long Scoreboard 表示 warp 在等长延迟内存操作(L1TEX:global/local/texture/surface)的数据依赖,也就是发起过 load/store 之后,结果没回来,scoreboard 把后续依赖指令卡住而停滞 69.4 个周期,这类停滞占总发射指令平均周期(97.7 周期)的约 71.0%。
Stall IMC Miss:因 IMC(内存控制器)未命中导致的停滞,有一定占比,需优化内存访问以提升缓存命中率。
Stall Wait、Stall No Instruction、Stall Short Scoreboard 等:这些停滞类型占比较小,对整体性能影响相对有限,但也可结合具体场景优化(如检查指令调度、减少不必要的等待等)。
和上节内容联系起来,Active Warps Per Scheduler为8.78,表示调度器运行过程中,平均有8.78个Warps处于活跃状态,而Warp Cycles Per Issued Instruction为97.67表明同一个Warp每发射一次需要97.67个cycle,即在97.67个cycle内要保证8.78个Warps处于活跃,每97.67/8.78=11.1个cycle发射一次Warp才能保证这样的活跃Warp数,这个和Issued Warp Per Scheduler ≈ 0.09是可以对应上的。
(7)Instruction Statistics
含义:统计 SASS(底层 Shader Assembly)指令的分布和执行情况。
用途:分析指令类型(如算术、内存操作)和执行频率,定位低效指令。
场景:优化指令级性能,减少冗余操作。

核心指标
Executed Instructions [inst]:执行的指令总数,为 26,656 条。
Issued Instructions [inst]:发射的指令总数,为 31,552 条(发射数多于执行数,可能因分支预测、指令回滚等原因)。
Avg. Executed Instructions Per Scheduler [inst]:每个调度器平均执行的指令数,为 277.67 条。
Avg. Issued Instructions Per Scheduler [inst]:每个调度器平均发射的指令数,为 328.67 条。
指令分布(Executed Instruction Mix)
IMAD:执行数量最多(约 6000+ 条),属于整数乘加类指令,是内核的核心计算指令之一。
S2R:特殊寄存器读取指令,数量约 3000+ 条,用于线程与特殊寄存器(如线程 ID、块 ID 等)的交互。
MOV:数据移动指令,数量约 3000+ 条,用于寄存器间的数据传递。
LDG:全局内存加载指令,数量约 3000+ 条,负责从 GPU 全局内存读取数据。
FADD:单精度浮点加法指令,数量约 3000+ 条,是浮点计算的核心指令。
EXIT:线程退出指令,数量约 3000+ 条,用于线程执行完毕后的退出操作。
ULDC、STG、ISETP:执行数量相对较少,分别涉及常量内存加载、全局内存存储、整数比较等操作。
(8)NVLink Topology
含义:显示 NVLink 拓扑结构,描述多 GPU 间的互连配置。
用途:帮助理解系统拓扑,优化 GPU 间数据传输路径。
场景:规划多 GPU 系统的数据分配。
(9)NVLink Tables
含义:提供 NVLink 性能的详细表格数据,补充 Nvlink Section。
用途:为 NVLink 性能提供结构化数据,便于分析。
场景:导出 NVLink 数据进行离线分析。
(10)NUMA Affinity
含义:分析 NUMA(非均匀内存访问)亲和性,评估内存分配与 GPU/CPU 亲和性。
用途:在多 GPU 或 CPU-GPU 系统中,优化内存分配以降低访问延迟。
场景:优化 DGX 或服务器环境中的内存亲和性。
(11)Launch Statistics
启动统计(Launch Statistics)用于分析 GPU 内核启动配置的相关信息,以下是详细解读:
核心配置参数
这些参数定义了内核启动时的资源分配和并行结构:
Grid Size:内核网格大小,值为 196,表示整个计算任务被划分为 196 个 “块(block)” 的集合。
Registers Per Thread [register/thread]:每个线程使用的寄存器数量,为 16,寄存器是 GPU 线程的快速存储资源,该值影响线程束(warp)的调度和资源占用。
Block Size:每个块的大小,为 256,即每个块包含 256 个线程。
Threads Per Thread:表述可能有误,结合上下文应为 Threads Per Block(每个块的线程数),与 Block Size 一致(256)。
Waves Per SM:每个流式多处理器(SM)上的 “波(wave)” 数量,为 1.36。“波” 指 SM 上可并行执行的块的最大数量,该值反映 SM 的并行度利用情况。
Uses Green Context:是否使用 “Green Context”(一种特殊的执行上下文,通常与低延迟、高优先级任务相关),此处未明确显示具体值,需结合工具逻辑判断(若为 true 则启用)。
# SMs [SM]:GPU 包含的流式多处理器数量,为 24,SM 是 GPU 的核心计算单元。
缓存与共享内存配置
这些参数控制 GPU 内存子系统的资源分配:
Function Cache Configuration:函数缓存配置,为 CachePreferNone,表示函数缓存策略为 “不偏好特定缓存”(可根据需求调整为偏好 L1 / 纹理缓存等)。
Static Shared Memory Per Block [byte/block]:每个块的静态共享内存大小,为 0,静态共享内存是编译时确定的块内共享内存。
Dynamic Shared Memory Per Block [byte/block]:每个块的动态共享内存大小,为 0,动态共享内存是运行时分配的块内共享内存。
Driver Shared Memory Per Block [byte/block]:驱动层为每个块分配的共享内存大小,为 1.02 字节(通常由驱动自动管理)。
Shared Memory Configuration [Kbyte]:共享内存总配置大小,为 16.38 KB,反映块可使用的共享内存总容量。

(12)Occupancy
含义:评估 SM 的占用率,即活跃 warp 数与最大 warp 数的比例。
用途:分析线程并行度,优化资源利用。
场景:调整块大小以提高 SM 占用率。
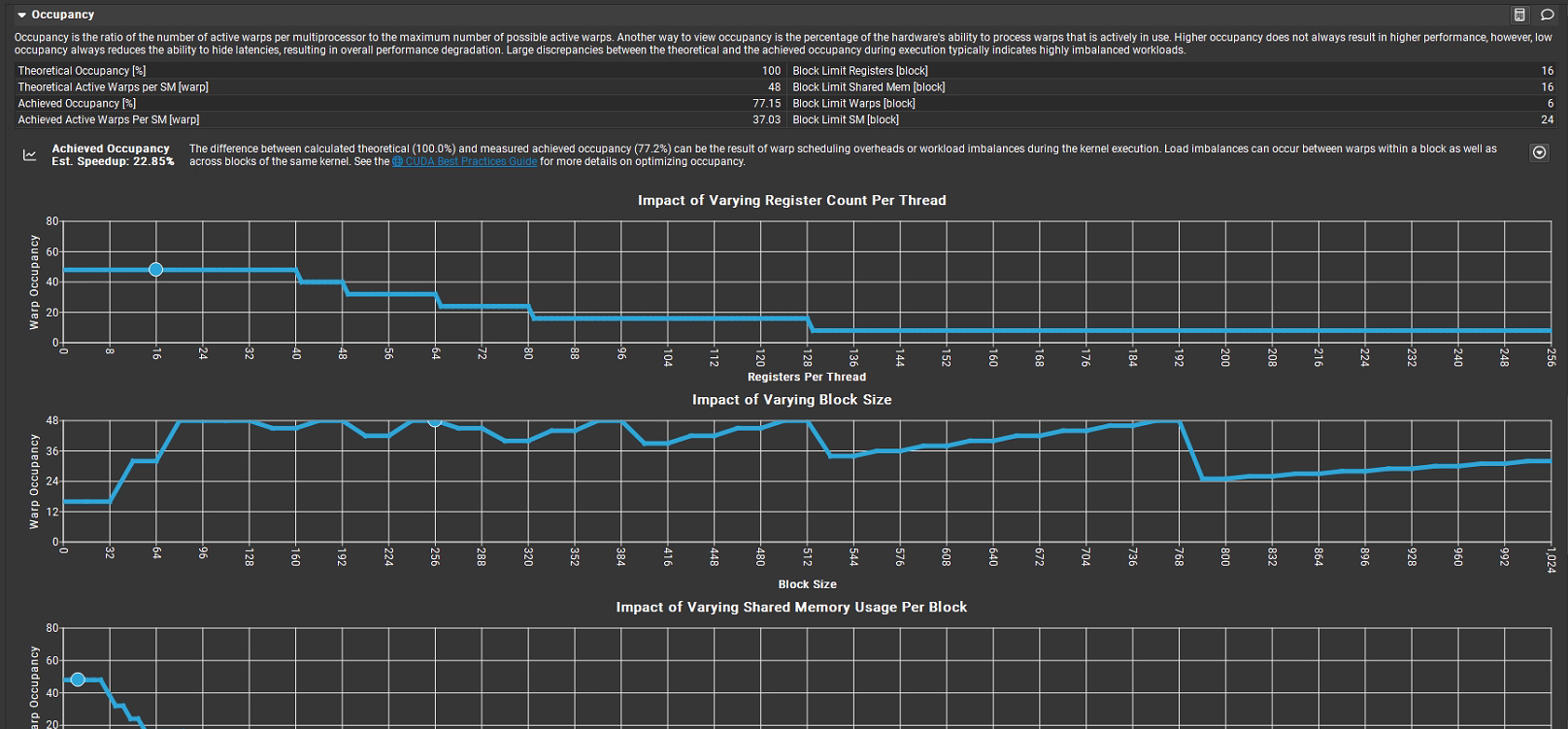
占用率核心指标
占用率是每个多处理器的活跃线程束数与最大可能活跃线程束数的比值,反映硬件处理线程束能力的实际使用率:
Theoretical Occupancy [%]:理论占用率为 100%,表示硬件资源(寄存器、共享内存等)理论上可支持的最大线程束并行度。
Theoretical Active Warps per SM [warp]:每个 SM 理论上可容纳的活跃线程束数,为 48。
Achieved Occupancy [%]:实际达到的占用率为 77.15%,说明实际活跃线程束数仅为理论值的约 77%。
Achieved Active Warps per SM [warp]:每个 SM 实际活跃的线程束数,为 37.03(约为 48 × 77.15%)。
理论占用率(100%)与实际占用率(77.15%)的差异,可能源于线程束调度开销或内核执行时的负载不均衡(Block 内或 Block 间的负载差异)。
资源限制说明
右侧列出了不同资源对线程块(Block)的限制:
Block Limit Registers [block]:寄存器限制下,每个 Block 最多支持 16 个线程束。
Block Limit Shared Mem [block]:共享内存限制下,每个 Block 最多支持 16 个线程束。
Block Limit Warps [block]:综合限制下,每个 Block 最多支持 6 个线程束。
Block Limit SM [block]:SM 资源限制下,每个 SM 最多支持 24 个 Block。
参数影响图表
界面包含三张图表,展示不同参数对占用率的影响:
Impact of Varying Register Count Per Thread:横轴为 “每个线程的寄存器数量”,纵轴为 “线程束占用率”。随着寄存器数增加,占用率在某一阈值后骤降(如寄存器数 > 40 时,占用率从约 50% 快速下降),说明寄存器过度使用会严重限制线程束并行度。
Impact of Varying Block Size:横轴为 “Block 大小”,纵轴为 “线程束占用率”。Block 大小在 96–768 范围内时,占用率维持在较高水平(约 40–50%);当 Block 过大(如 > 768),占用率骤降,说明 Block 大小需合理选择以平衡并行度与资源消耗。
Impact of Varying Shared Memory Usage Per Block:横轴为 “每个 Block 的共享内存使用量”,纵轴为 “线程束占用率”。共享内存使用量增加时,占用率快速下降(如从 0 增加到一定值时,占用率从约 50% 降至接近 0),说明共享内存过度使用会极大限制线程束并行度。
(13)GPU and Memory Workload Distribution
含义:分析工作负载在 SM 间的分布,评估负载均衡性。
用途:确保所有 SM 均匀分配工作,最大化 GPU 利用率。
场景:优化线程块分配,平衡多 SM 负载。
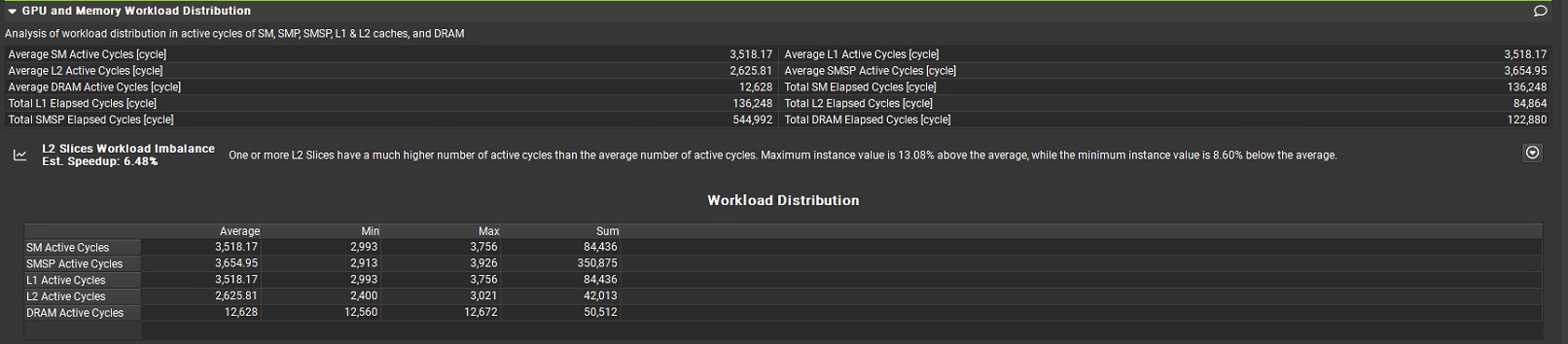
核心指标
Average SM Active Cycles [cycle]:每个流式多处理器(SM)的平均活跃周期,为 3,518.17 周期,SM 是 GPU 的核心计算单元。
Average L1 Active Cycles [cycle]:L1 缓存的平均活跃周期,为 3,518.81 周期,L1 是核心专用或SM专用。每个GPU SM都有自己私有的L1缓存。
Average L2 Active Cycles [cycle]:L2 缓存的平均活跃周期,为 2,625.81 周期,L2 是共享缓存,所有GPU SM共享一个统一的L2缓存,L1访问速度快于L2快于DRAM。
Average SMSP Active Cycles [cycle]:流式多处理器子系统(SMSP,包含 SM 及周边控制单元)的平均活跃周期,为 3,654.95 周期。
Average DRAM Active Cycles [cycle]:DRAM(显存)的平均活跃周期,为 12,628 周期,DRAM 是 GPU 的大容量内存。
Total SM Elapsed Cycles:SM总用时12,628 cycles (这是基准时间)
Total L1 Elapsed Cycles:L1总用时136,248 cycles。
Total L2 Elapsed Cycles:84,864 cycles。
Total SMSP Elapsed Cycles:544,992 cycles。
Total DRAM Elapsed Cycles:122,880 cycles。
(14)Source Counters
含义:将性能指标映射到源代码行,分析代码级性能。
用途:帮助开发者定位特定代码行的性能瓶颈。
场景:优化特定 CUDA 内核代码。

这部分可以结合下一节Source进行分析,从图中左侧可知0x200c64cd0对应指令等待时间最长,对应源码A[idx] + B[idx]即浮点数加法指令,图中右侧部分执行指令最多次数的指令,这里1568=50176/32,50167是总的线程数,32是每个warp中包含线程数,每个warp中线程指令并行执行,相当于对该指令仅需发射 1 次 ,即所谓SIMD(Single Instruction, Multiple Data),相当于仅执行“一次”指令,所以总共执行1568次指令。
3. Source
功能概述:该页面主要展示内核代码的原始视图,并将性能数据与代码行进行关联。
具体作用:
- 定位性能热点:你可以看到每条代码指令对应的执行统计信息,如指令执行次数、占用的周期数等,从而快速定位到内核中哪些代码行对性能影响较大,帮助开发者聚焦于性能优化的关键区域。
- 指令级分析:对于汇编指令(SASS 指令),可以详细查看其执行情况,结合其他指标分析指令的效率,比如判断是否存在大量低效的指令操作、指令融合的机会等。
- 调试与优化参考:通过性能数据和代码的对应关系,开发者可以更直观地分析代码逻辑对性能的影响,进而调整算法或代码结构来优化性能。
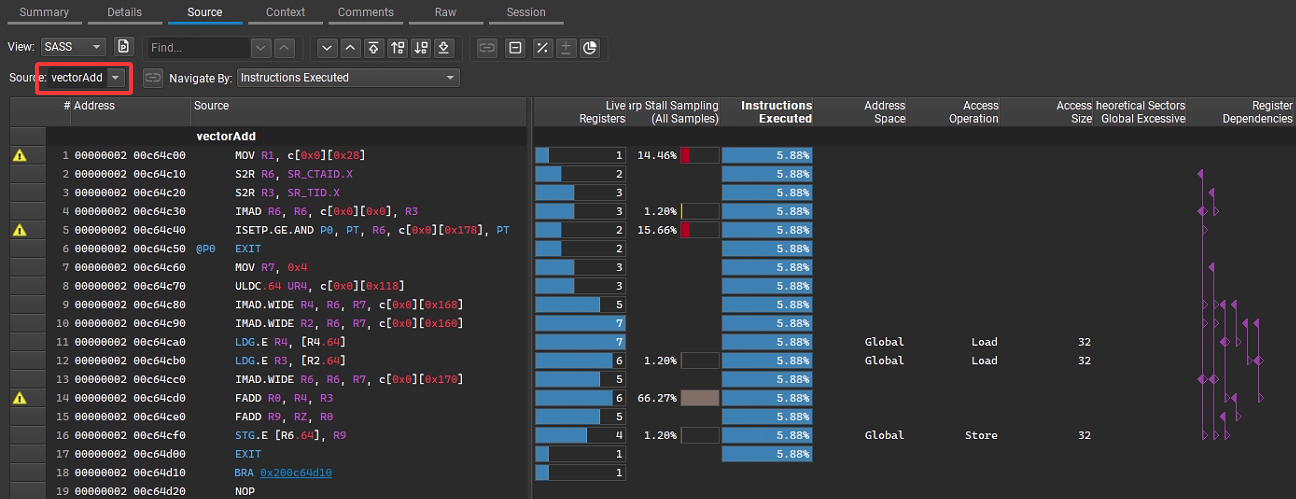
核函数vectorAdd对应PTX汇编指令解析如下:
MOV R1, c[0x0][0x28] 加载线程块数量等核配置参数(辅助后续索引计算)。 S2R R6, SR_CTAID.X 读取当前线程块的 blockIdx.x(线程块在网格中的 X 维度索引)。 S2R R3, SR_TID.X 读取当前线程的 threadIdx.x(线程在线程块中的 X 维度索引)。 IMAD R6, R6, c[0x0][0x0], R3 计算全局索引 i = blockIdx.x * blockDim.x + threadIdx.x(c[0x0][0x0] 存储 blockDim.x)。 ISETP.GE.AND P0, PT, R6, c[0x0][0x178], PT 判界:比较 i(R6)与 numElements(c[0x0][0x178] 存储 numElements),若 i >= numElements,则标记分支条件 P0 为真。 @P0 EXIT 若 P0 为真(即 i >= numElements),直接退出线程,跳过后续计算(对应核函数的 if (i < numElements) 不成立的分支)。 MOV R7, 0x4 准备后续内存访问的偏移量(0x4 对应 float 类型的字节数,因为 float 占 4 字节)。 ULDC.64 UR4, c[0x0][0x118] 加载数组 A 的基地址到寄存器 UR4(UR 是统一寄存器,用于地址计算)。 IMAD.WIDE R4, R6, R7, UR4 计算 A[i] 的地址:A 的基地址 UR4 + 索引 i × 4 字节(R7=0x4)。 IMAD.WIDE R2, R6, R7, c[0x0][0x160] 计算 B[i] 的地址:B 的基地址(c[0x0][0x160]) + 索引 i × 4 字节。 LDG.E R4, [R4,64] 加载 A[i] 的值到寄存器 R4(LDG 是全局内存加载指令)。 LDG.E R3, [R2,64] 加载 B[i] 的值到寄存器 R3。 IMAD.WIDE R6, R6, R7, c[0x0][0x170] 计算 C[i] 的地址:C 的基地址(c[0x0][0x170]) + 索引 i × 4 字节。 FADD R0, R4, R3 执行浮点加法:A[i] + B[i],结果存在 R0。 FADD R9, RZ, R0 执行 0.0f + (A[i] + B[i])(RZ 是值为 0 的寄存器),对应核函数的 +0.0f。 STG.E [R6,64], R9 将结果存储到 C[i] 的地址(全局内存写操作)。 EXIT 线程正常退出(对应 if 分支执行完毕)。
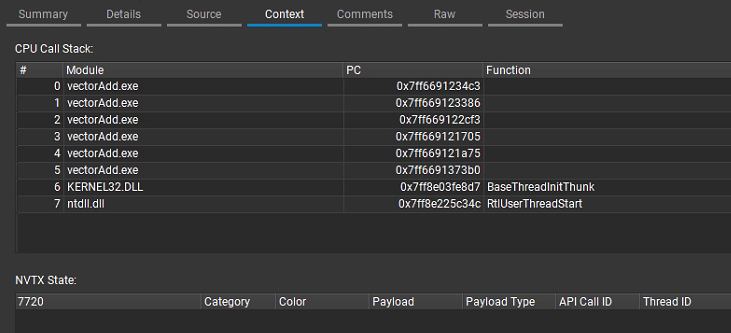
4. Context
功能概述:提供当前内核分析的上下文信息,帮助理解内核执行的环境和条件。
具体作用:
- 系统与硬件信息:展示运行内核的硬件平台信息,如 GPU 型号、SM 数量、显存容量等,以及操作系统和 CUDA 版本等,这些信息对于分析性能瓶颈和对比不同平台的性能表现非常重要。
- 内核配置参数:显示内核启动时的配置,例如网格(grid)和线程块(block)的大小、共享内存的使用量等。通过这些参数,开发者可以评估内核的并行度设置是否合理,是否充分利用了硬件资源。
- 性能指标对比:可以提供一些基础的性能指标参考值或历史数据对比,帮助判断当前内核的性能表现是否符合预期,或者在不同运行条件下的性能变化情况。
5. Comments
功能概述:用于添加和查看关于当前性能分析报告的注释信息,方便记录分析过程中的想法、发现和结论。
具体作用:
- 记录分析思路:开发者在分析性能数据时,可以随时在该页面记录自己对某些性能现象的理解、猜测以及下一步的分析计划,便于后续回顾和整理。
- 团队协作沟通:在多人协作进行性能优化时,团队成员可以通过注释共享信息和见解,提高沟通效率,避免重复工作。
- 报告总结:可以将最终的性能优化结论、建议等记录在注释中,使报告更加完整和易于理解。
6. Raw
功能概述:呈现原始的性能数据,提供最基础、未经过多处理和汇总的数据记录。
具体作用:
- 深度数据分析:对于需要进行更深入的性能研究或自定义数据分析的用户,可以直接从该页面获取原始数据,使用其他工具或脚本进行进一步的处理和挖掘,满足个性化的分析需求。
- 数据验证:当对汇总后的性能数据存在疑问时,可以通过查看原始数据进行验证,确保分析结果的准确性。
- 科研与定制化需求:在一些科研项目或对性能分析有特殊要求的场景下,原始数据可以为研究人员提供丰富的信息,用于构建更复杂的性能模型或算法。

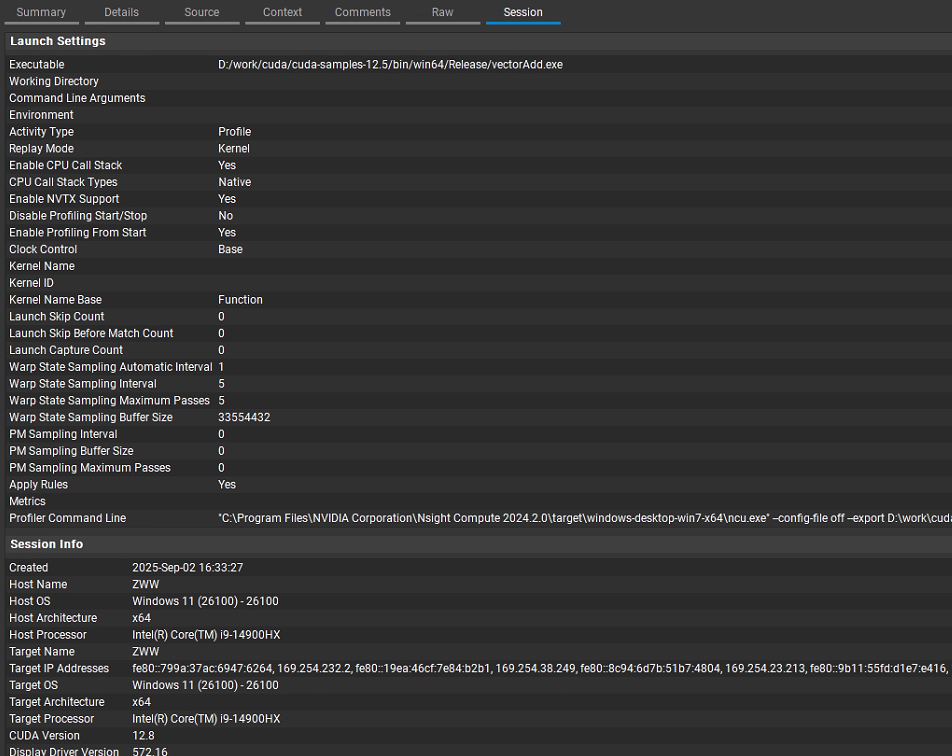
7. Session
功能概述:管理和展示性能分析会话相关的信息,包括会话的创建时间、保存状态等。
具体作用:
- 会话管理:允许用户保存、加载和删除性能分析会话,方便管理多个不同的分析任务和结果,便于随时恢复之前的分析工作。
- 会话信息查看:显示每个会话的基本信息,如会话名称、创建时间、使用的配置文件等,帮助用户快速识别和选择需要的会话。
- 对比与版本控制:在进行多次性能优化迭代后,可以通过不同会话之间的对比,直观地看到性能的变化情况,辅助进行版本控制和优化效果评估。
3 命令行使用
3.1 基本使用
通过命令行启动ncu,基本语法如下:
ncu [options] <application> [application arguments]
如下图在命令行下对vectorAdd.exe可执行程序进行分析,ncu会实时给出解析结果:
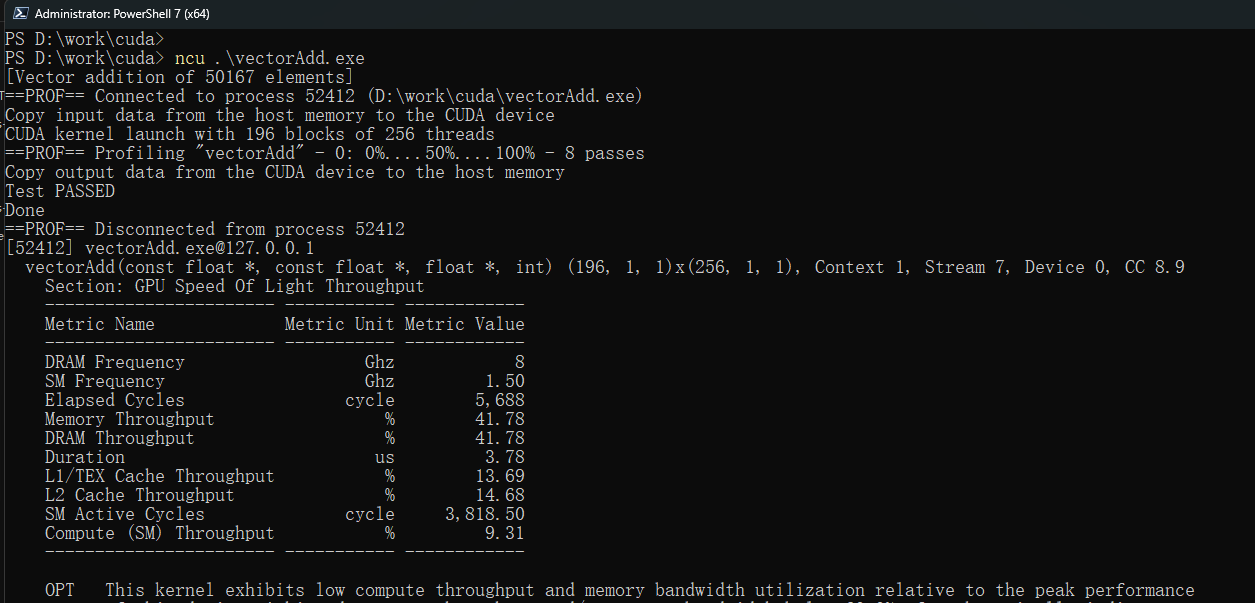
该基本命令只是输出简要的解析信息,要想详细分析可执行程序,还需要传入不同的参数来实现。
3.2 常用选项
1. 指定输出文件
使用-o选项将分析结果保存到文件:
ncu -o profile_result .\vectorAdd.exe
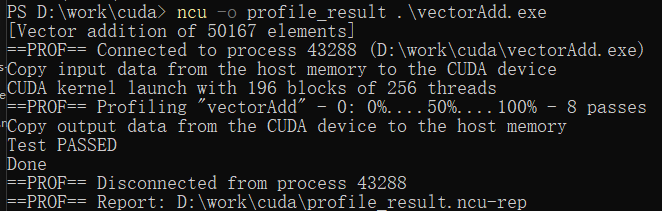
2. 详细报告
使用--print-details all选项生成详细报告:
ncu --print-details all .\vectorAdd.exe
3. 指定内核
使用--kernel-name选项分析特定内核:
ncu --kernel-name vectorAdd .\vectorAdd.exe
4. 性能指标
使用--metrics选项指定性能指标:
ncu --metrics gpu__time_duration.sum .\vectorAdd.exe
5. 内存带宽分析
使用--section MemroyWorkloadAnalysis分析内存带宽:
ncu --section MemoryWorkloadAnalysis .\vectorAdd.exe
其实可以用--help查看所支持参数详细用法,另外在文章最开始的图1中最下端其实GUI工具也已经给出了当前launch的附加参数,可以对比进行学习参数用法。
参考
1. https://blog.csdn.net/weixin_43258309/article/details/148257449
2. https://blog.csdn.net/UCAS_HMM/article/details/126514127
3. https://docs.nvidia.com/nsight-compute/
4. https://blog.csdn.net/weixin_42849849/article/details/146290086















这一切,似未曾拥有