



夜莺监控从 8.3 版本开始引入了新版的表格,力争对齐 Grafana(Grafana 积累了多年,确实太强了),本文图文并茂手把手教你配置一个 Table 仪表盘出来,用于展示机器列表,当然了,交换机、MySQL 实例等其他监控对象,也可以通过这个方式展示。
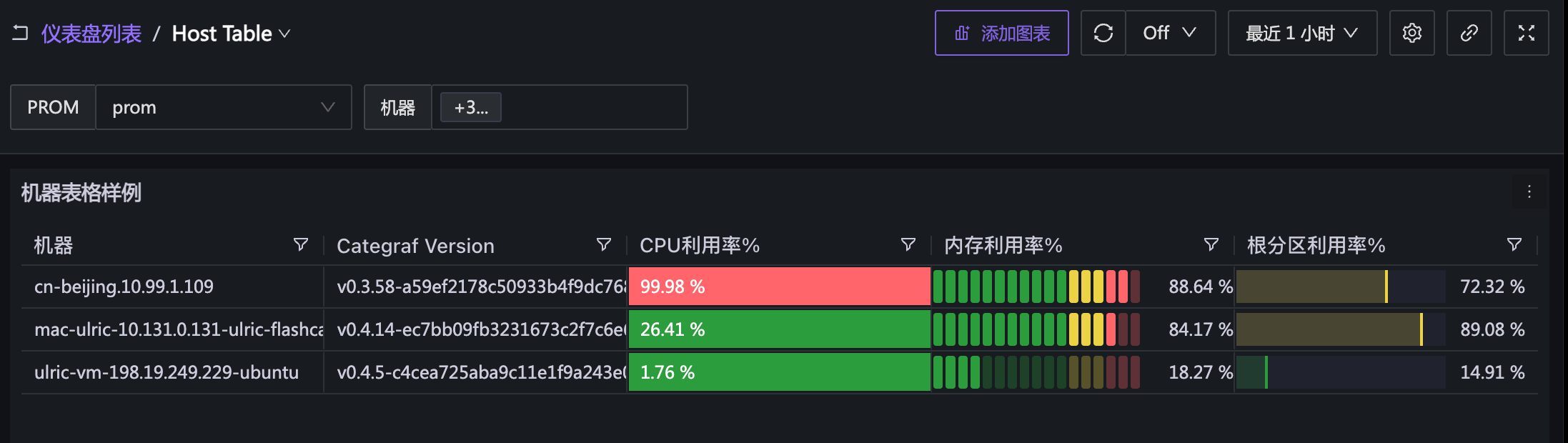
先看效果
JSON 文件:https://gist.github.com/UlricQin/c5d432b236a7a7fea3979026ab8e22c8
上图中:
- 有两个变量,一个是数据源变量,用于筛选数据源,另一个是机器变量,用于筛选机器,如果机器变量这里选择 All,就是查看所有机器的数据
- 表格里的数据用了四个指标,CPU、内存、根分区都是展示的对应指标的值,Categraf Version 字段是从某个指标里提取的标签
- 所有指标都有 ident 标签,通过 ident 标签 join 在一起,相同 ident 标签的数据位于同一行
下面我们来看看具体是如何配置的。
仪表盘变量
鼠标放到下面的位置,会出现变量编辑按钮:

点击之后弹窗里会展示配置了哪些变量:

这里我配置了两个变量,一个类型是
数据源(Datasource)
,另一个类型是查询(Query)
,点击变量名称,可以进入变量配置。上例,我们先点击prom变量,进入数据源的配置:
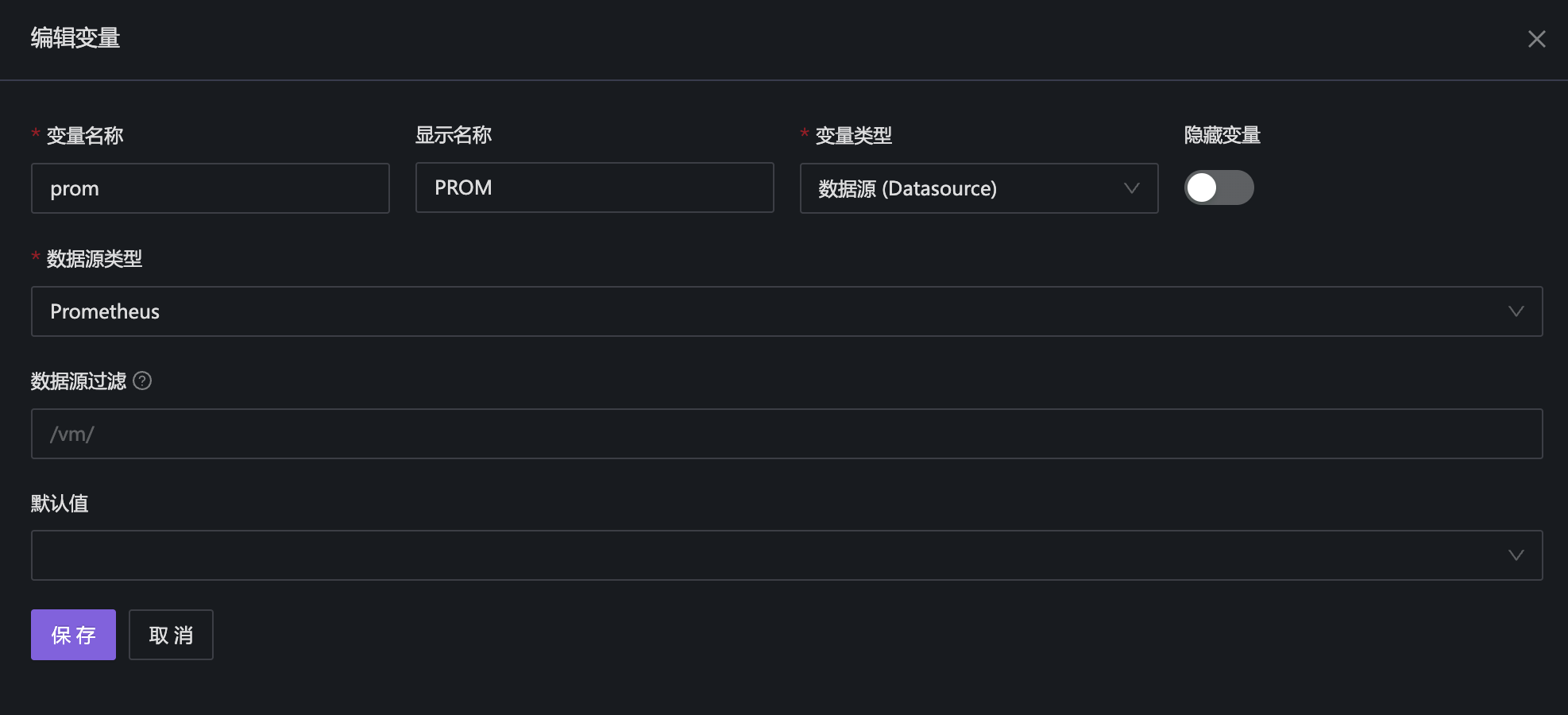
- 变量名称:一般写英文
- 显示名称:就是仪表盘里显示的那个名称,可以为中文
- 变量类型:很重要,这里是为了筛选数据源的,所以变量类型就是数据源
- 数据源类型:因为数据源也有多种类型,Prometheus、VictoriaMetrics 等数据源都选择 Prometheus 数据源类型
- 数据源过滤:是通过正则来做二次过滤,只展示符合过滤条件的数据源,我这里没有配置,展示我的环境里的所有数据源
然后进入ident变量配置部分:
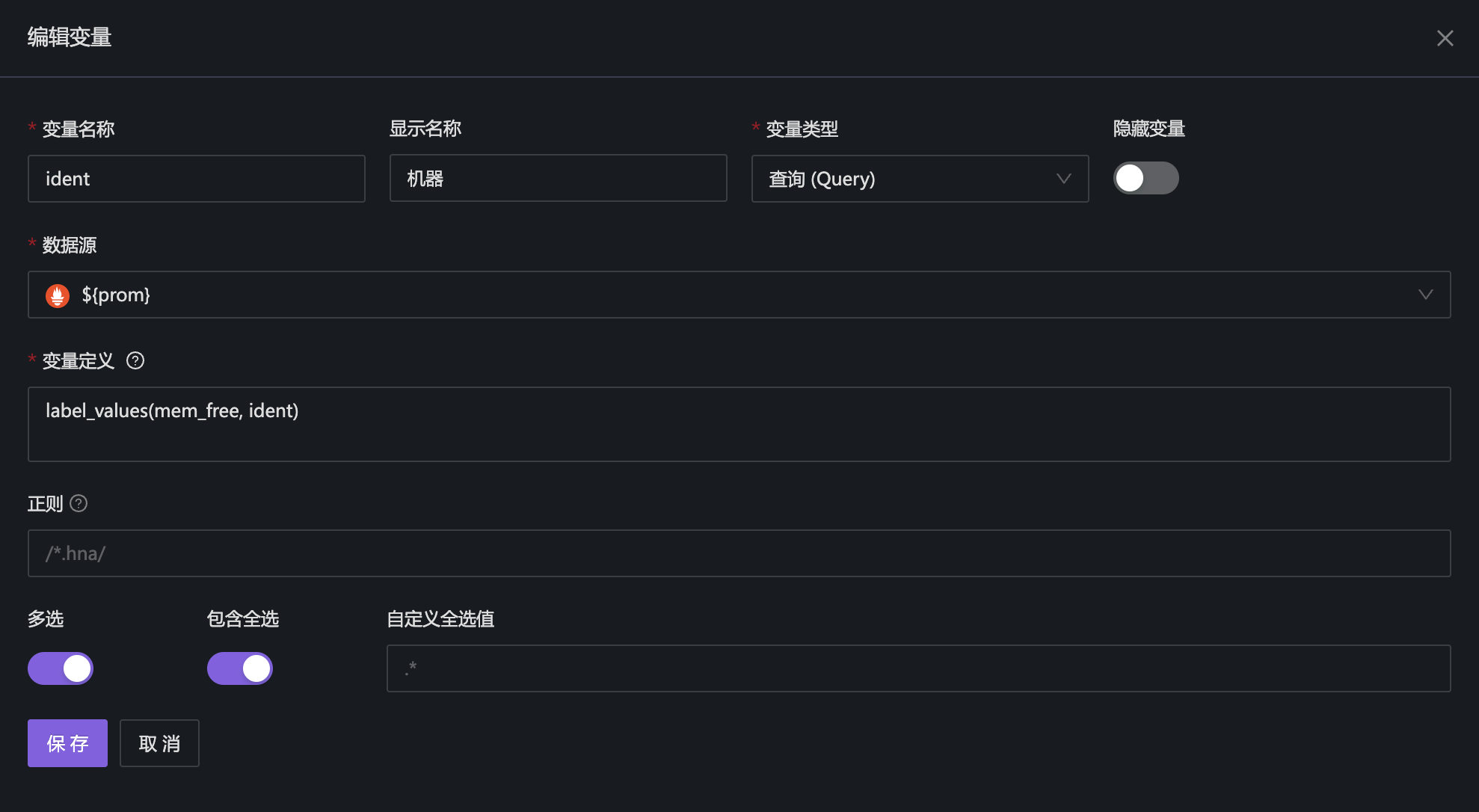
变量名称和显示名称就不重复解释了,其他的:
- 变量类型:选择
查询(Query)
,即通过一个查询表达式查询时序库中的数据,然后从数据中提取一些内容作为这个变量下拉框的内容 - 数据源:选择
${prom}而非选择一个写死的数据源,这样就能和数据源的下拉框联动起来了 - 变量定义:和 Grafana 保持一致,这里用的是 label_values 函数,这个函数有两个参数,第一个参数是一个 promql,用于查询过滤数据,第二个参数是标签名,即:使用第一个 promql 查询数据,然后遍历查到的数据,从中提取 ident 标签。第一个参数即 promql 其实也可以不写,这样的话,就会查询时序库里的所有数据,然后从中提取 ident 标签的值,这个性能就很差了
变量,就是为了定义下拉框的内容,下拉框的内容是否支持多选、全选,就是由下面的字段控制的。
另外,有时我们会看到一些仪表盘里有多个
查询(Query)
类型的变量,相互之间是联动的,核心就是在变量定义那里,会引用上一个变量的值。比如我上例中的 ident 变量,会展示机器列表,然后我还想做另一个变量展示机器上的网卡列表,而且希望二者联动,即选择某个机器的时候,网卡列表里就只展示这个机器的网卡,此时可以做一个 interface 变量,变量定义里可以这么写:
label_values(net_bits_recv{ident=~"$ident"}, interface) interface 变量引用了 ident 变量,这样就可以联动了。
扯远了,下面我们回来看这个 Table 的具体配置。
原始数据
我这里用到了 4 个指标:
cpu_usage_active 100 - mem_available_percent disk_used_percent categraf_info 分别来自 Categraf 采集器的四个插件:
- input.cpu
- input.mem
- input.disk
- input.self_metrics
各个 promql 都引用了 ident 变量,比如:
100 - mem_available_percent{ident=~"$ident"} promql 里必须引用变量,否则跟机器那个变量下拉框没法联动。
基本配置
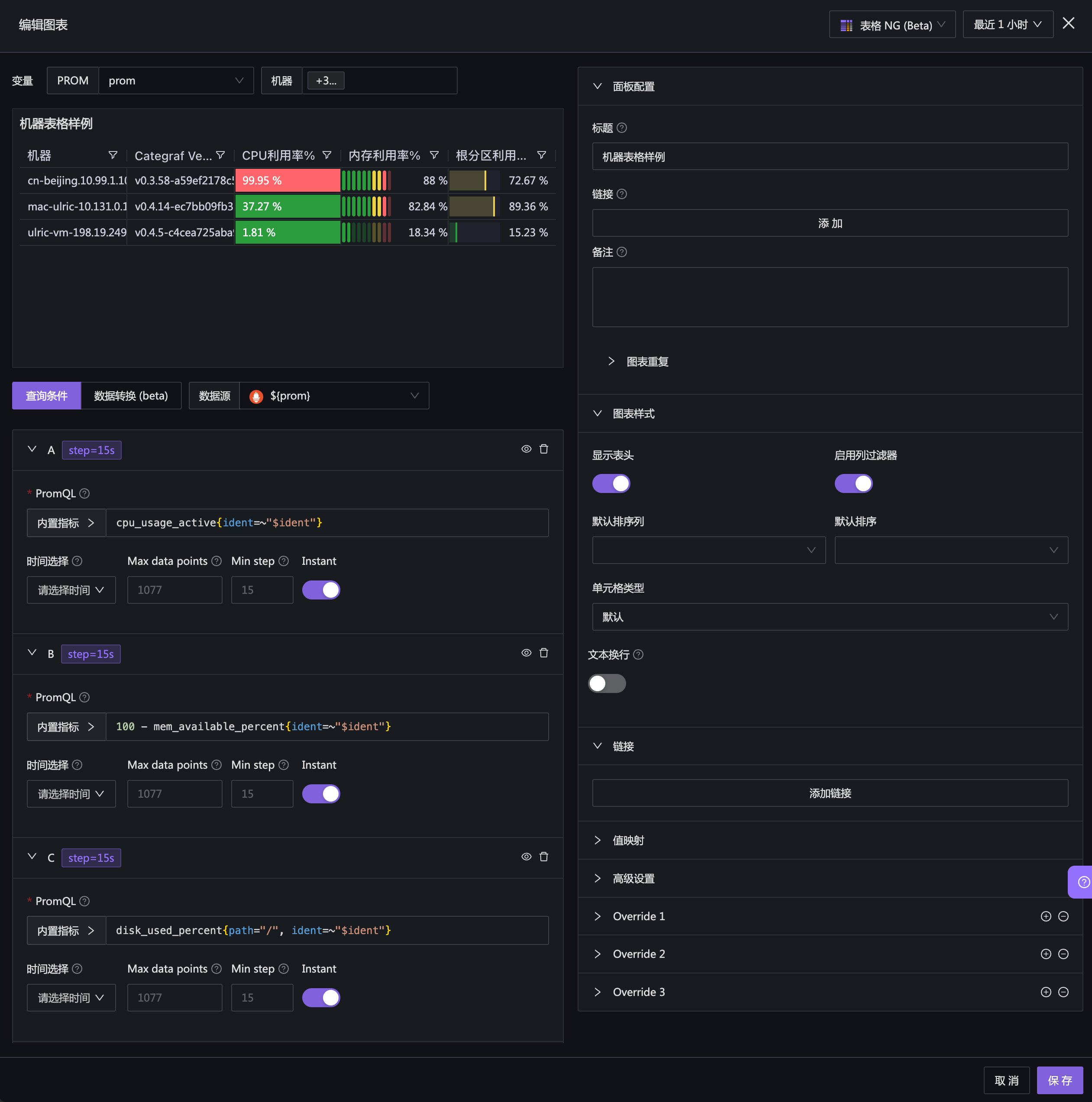
注意:
- 图表类型:选择表格NG,选项在右上角,现在还是Beta版本,如果你在使用过程中发现问题,可以给 github.com/n9e/fe 提 issue
- 多个指标的数据,ident 标签可以关联在一起,所以需要配置数据转换:Join by field

通过 ident 字段做 outer 连接,表格里会出现很多烂七八糟的数据,只留下自己想要的,其他都设置为隐藏:
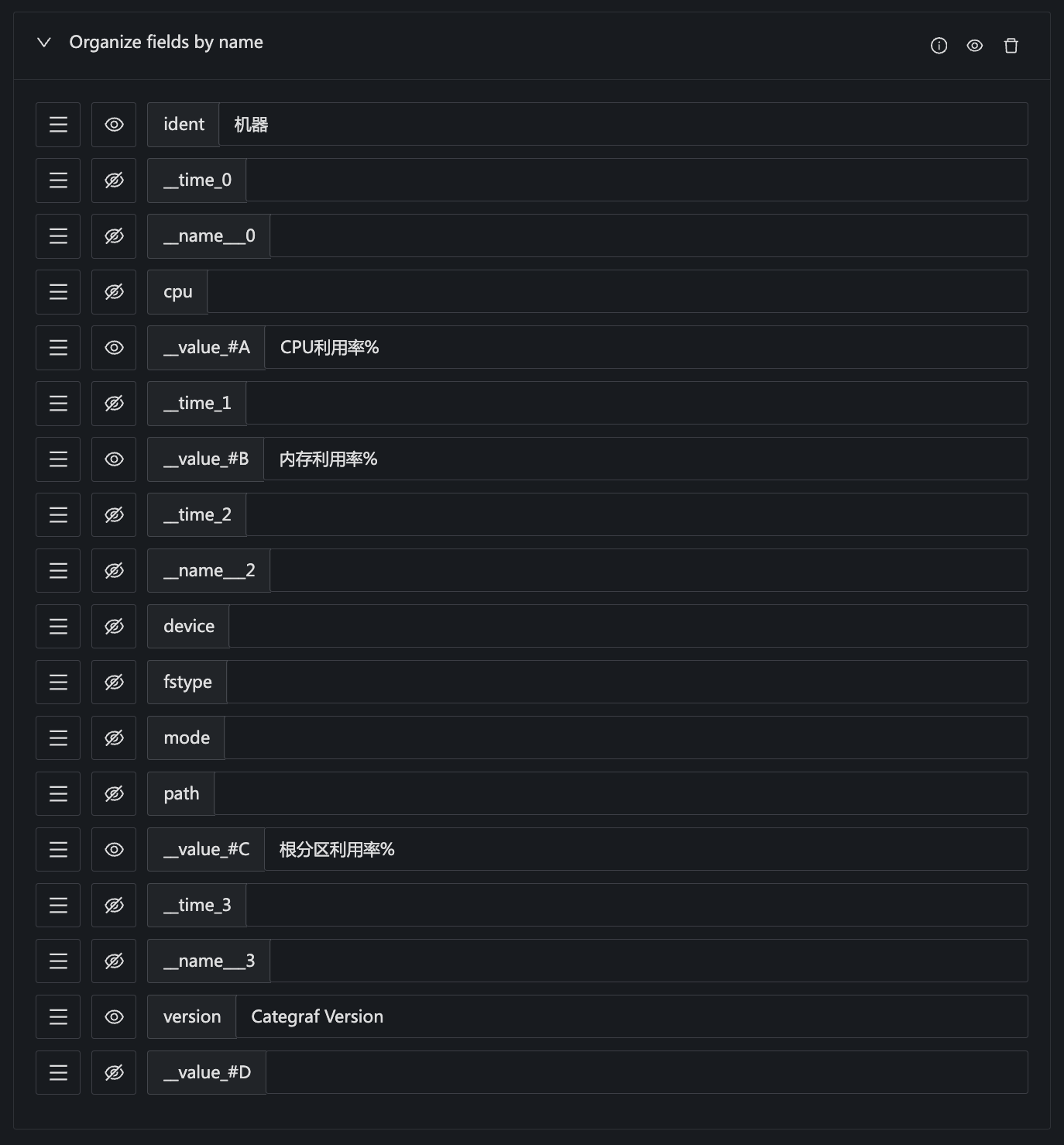
字段覆盖配置
右下方有一堆 Override 配置,用于配置不同的字段的展示效果,比如 CPU 那个:
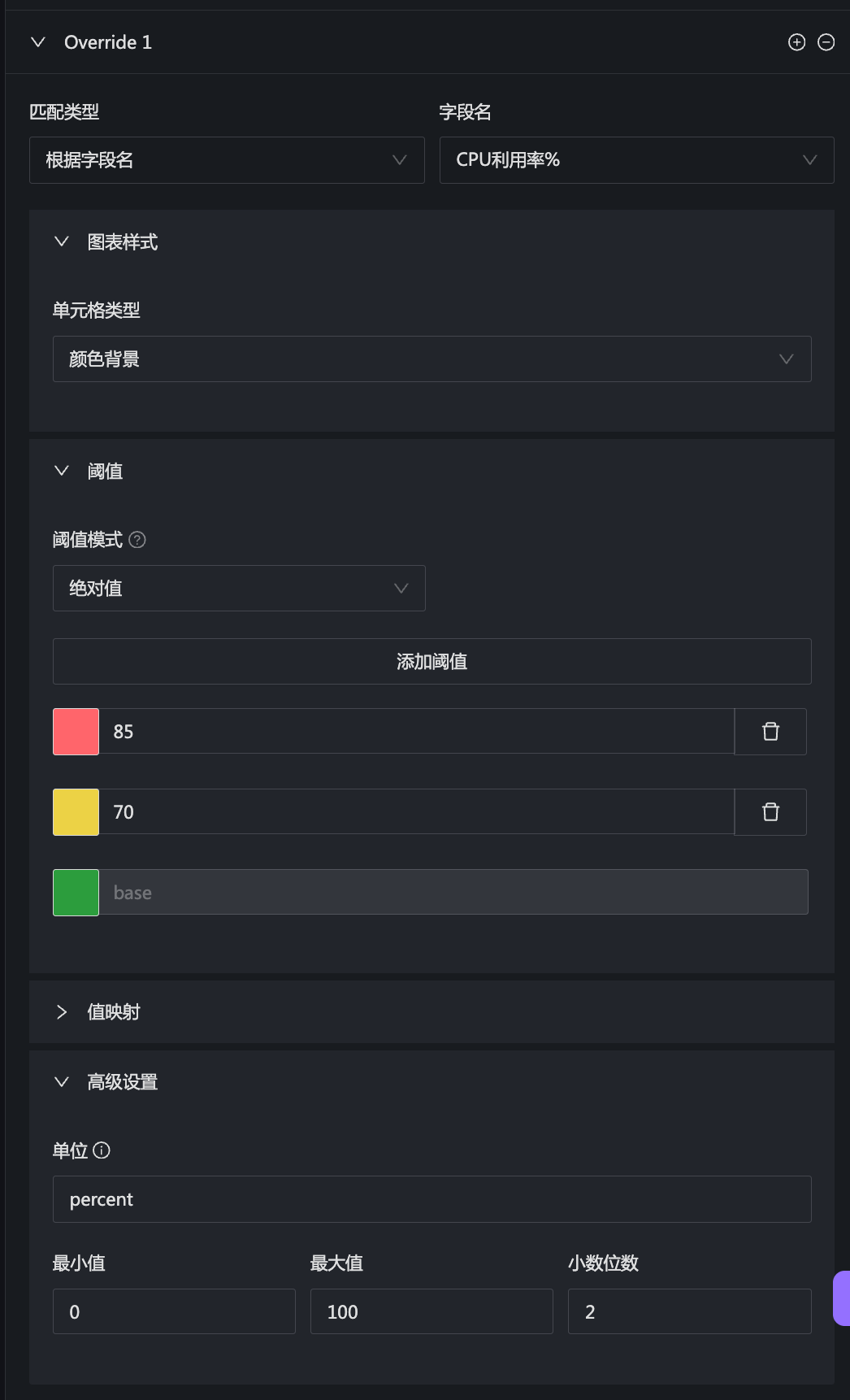
再比如内存那个:
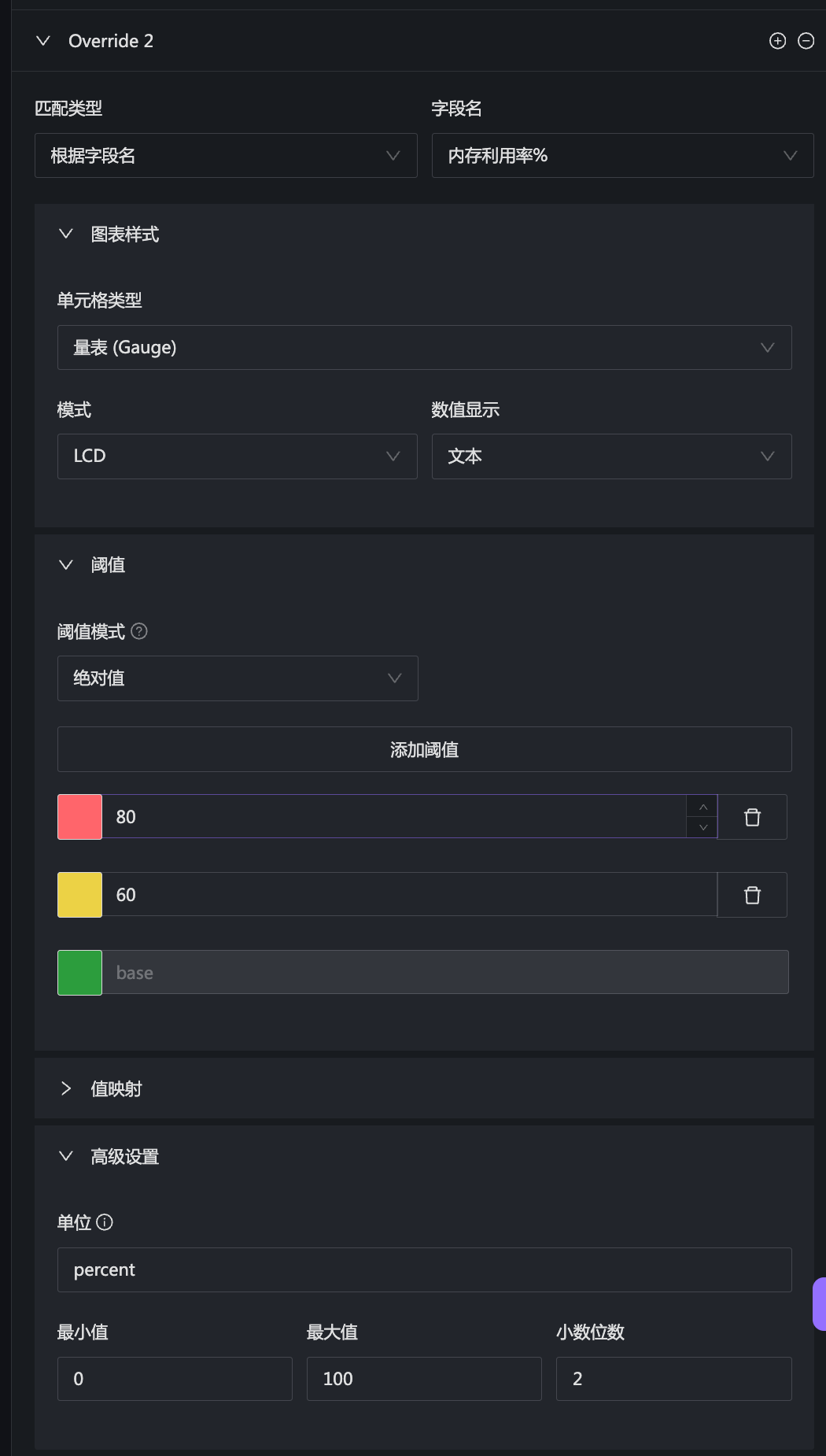
注意图表样式那个配置,一个用的颜色背景,另一个用的是量表。最后再看看根分区那个:
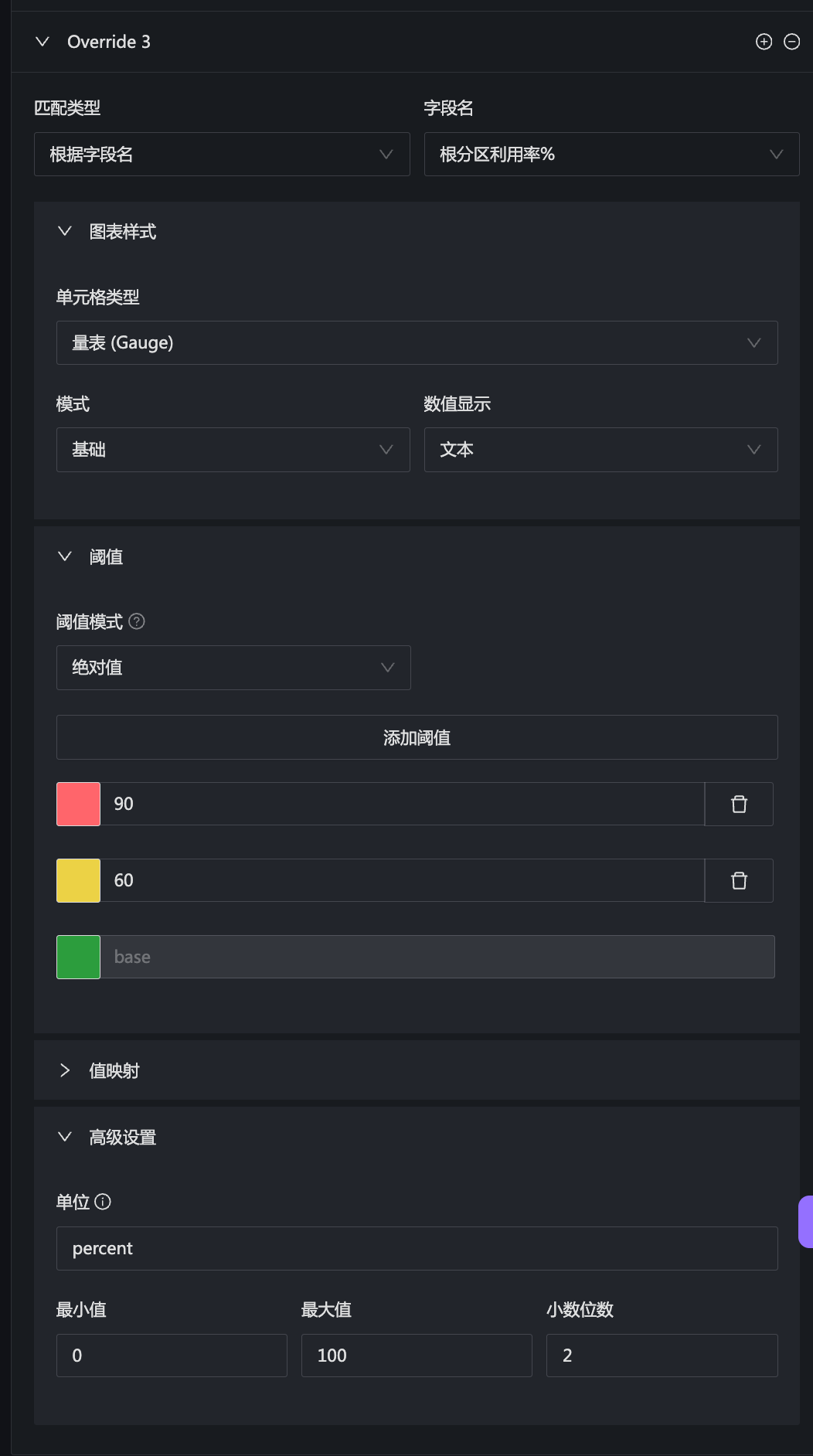
也是用的量表,但是模式不同。
后记
会了么?上例是机器列表,MySQL、Redis、交换机等各种监控对象都可以配置起来了。把各个对象的关键SLI数据放到表格里,看起来还是很方便的,一目了然即可知道哪个实例有问题。
近期文章
- 利用 OpenTelemetry 构建尾部采样
- 监控系统如何选型:Zabbix vs Prometheus
- Prometheus 监控 Kubernetes 最新极简方案
- NetFlix SRE 实践
- 可观测性体系建设的五步心法
- 十年磨一剑,运维监控、可观测性领域创业,拼的是产品细节和交付迭代能力
- 首席工程师教我的 10 个经验
- 从 1 到 100 万用户:我真希望早点知道的架构
- 做开源商业化创业3年,一点小感悟














这一切,似未曾拥有