


线程池是如何实现的?
线程池
线程池,就是
提前创建好一批线程,然后存储在线程池中,当有任务需要执行的时候,从线程池中选一个线程来执行。可以频繁的避免线程的创建和销毁的开销。
线程池是基于池化思想的一种实现,本质就是提前准备好一批资源,以备不时之需,在资源有限的情况下,可以大大的提高资源的利用率,提升性能。
还有一些其他基于池化思想的实现:
- 连接池
- 内存池
- 对象池
Java中线程池各接口与实现类之间的关系
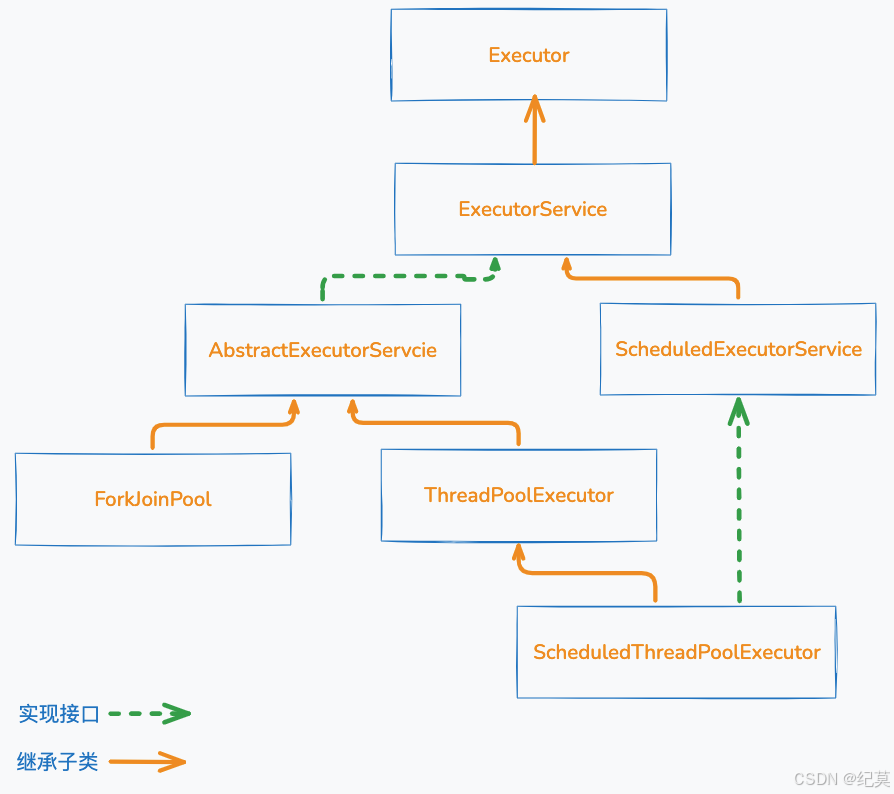
线程池的实现原理
除了ForkJoinPool以外,上图中,无论是通过接口还是实现类来创建线程池,最终都是通过ThreadPoolExecutor的构造方法来实现的。
在构造方法中参数,可以反应出这个对象的数据结构,就是下面这些参数
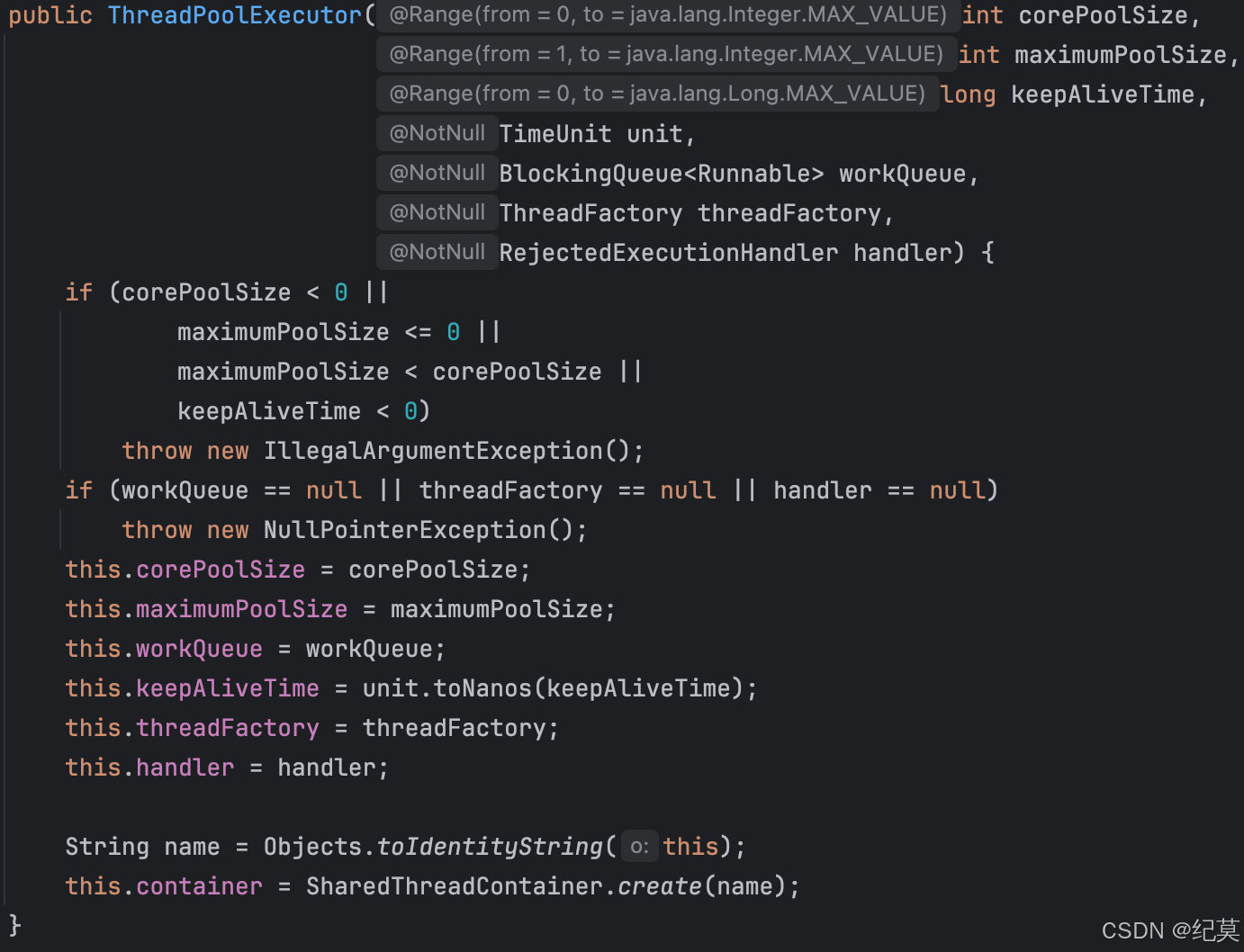
corePoolSize
,核心线程数数量,线程池中正式员工的数量。maximumPoolSize
,最大线程数数量,线程池中,正式员工与临时工(非核心线程)两者总共最大的数量workQueue
,任务等待队列,当核心线程数量的线程任务处理不过来的时候,会先将任务放到这个队列里面进行等待,直到队列满了,然后再有任务就继续创建线程,直到创建线程的数量到达maximumPoolSize数量。keepAliveTime
,非核心线程的最大空闲时间,就是当没有任务需要处理的时候,临时工可以待多久,超过这个时间就会被解雇threadFactory
,创建线程的工程,可以统一处理创建线程的属性。可以理解为每个公司对员工的要求都不一样,可以在这里指定员工手册。handler
,线程池拒绝策略,当核心线程数,处理不过来任务,等待队列里也满了,算上临时工线程数量也已经到了maxmumPoolSize了,还有任务提交过来,这个时候可以配置的拒绝任务的策略。默认情况下是抛出异常,告诉任务提交者,“忙不过来了,老子不干了!”
拒绝策略JDK提供的有这么几种:
AbortPolicy(默认策略)
抛出RejectedExecutionException异常,立即拒绝任务。
适用场景
:任务必须被处理,拒绝后需人工干预。DiscardPolicy
静默丢弃任务,不抛异常。
适用场景
:非关键任务(如日志记录、统计)。DiscardOldestPolicy
丢弃队列中最旧的任务,再尝试提交新任务。
适用场景
:实时性要求高的任务(如实时计算)。CallerRunsPolicy
由调用线程(提交任务的线程)直接执行任务。
适用场景
:降低任务提交速度,缓冲系统压力。
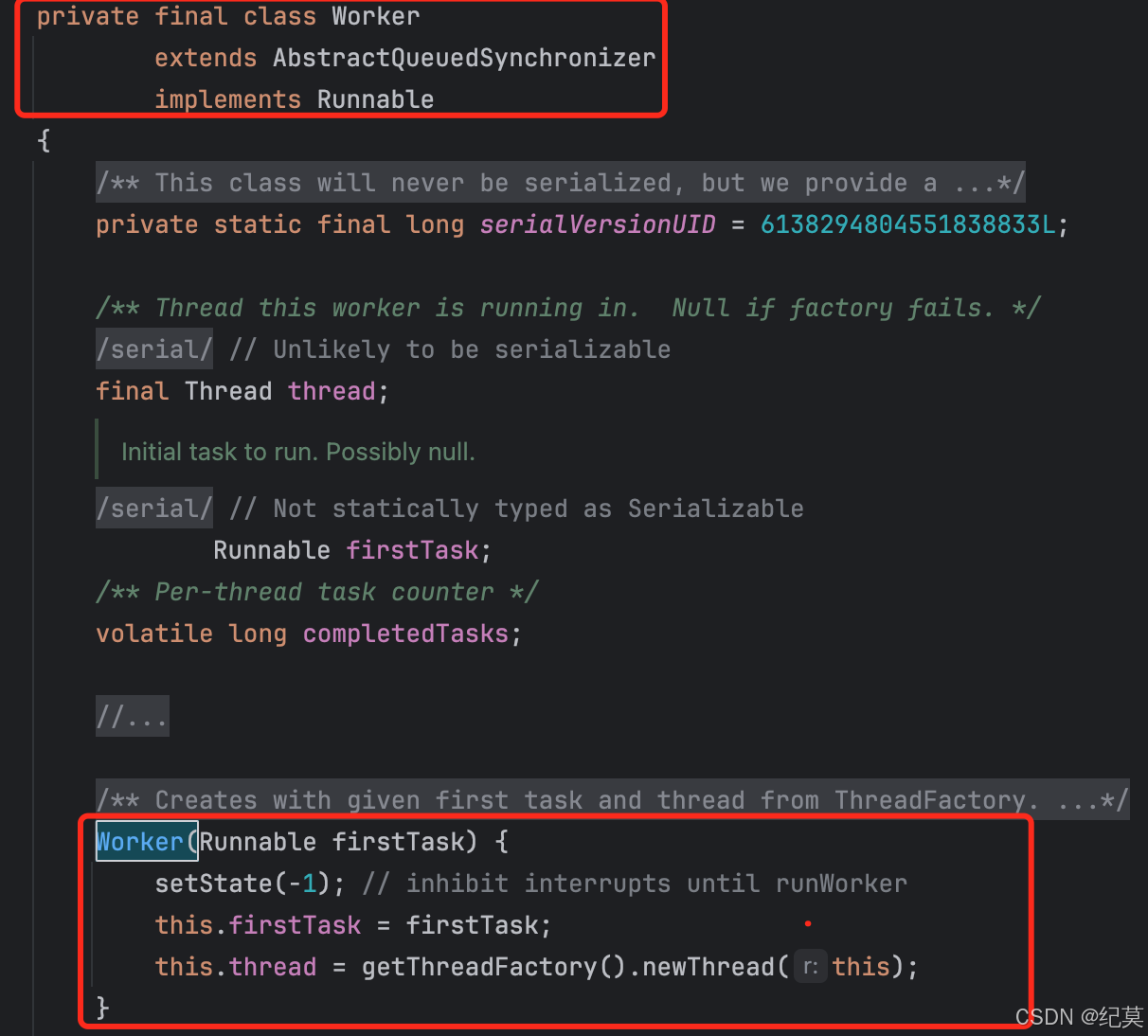
Worker
ThreadPoolExecutor里面还有一个重要的内部类Worker,这个Worker的概念也是比较重要的。它实现了Runnable接口,并且每个Worker对象包含一个任务和一个线程。
任务
(Runnable firstTask),这个任务就是我们提交给线程池要执行的那个任务(Runnable类型),就是说一个任务想要被线程池执行就必须变成一个Worker线程
(Thread thead),每个Worker会有一个线程来执行,这个线程是有ThreadPoolExecutor来进行管理的。
当 Worker被创建时,它会通过构造函数接收一个 Runnable 类型的任务。但是Worker并不是执行完这个任务就结束了,而是会继续从任务队列中取任务并执行,直到线程池关闭或任务队列为空。
Worker 中的Thread 对象,表示实际执行任务的工作线程。
每个 Worker都会拥有一个工作线程,工作线程会执行run()方法中的任务。
在 run()方法中,Worker 反复执行 runTask(firstTask)来执行任务。执行完一个任务后, Worker 会继续检查线程池的状态
(runStateAtLeast(ctl.get(),SHUTDOWN))并获取新的任务,直到线程池关闭。
在ThreadPoolExecutor中有一个字段,
workers类型是HashSet<Worker>,专门用来存储工作线程集合,负责管理所有工作线程的生命周期
,无论是想停止线程池还是说结束线程池,都会检查workers集合中是否还有正在运行的工作线程。 线程池执行任务
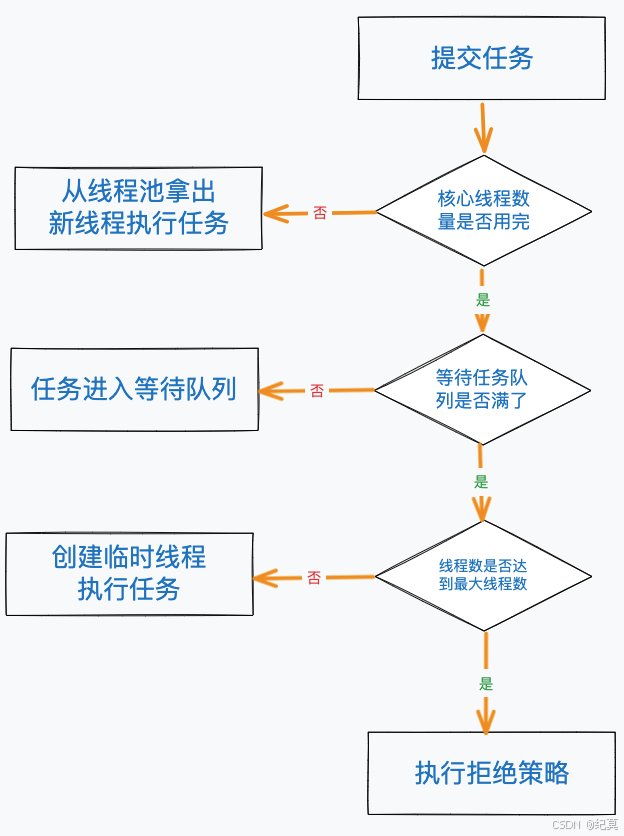
下面我们来看一下线程池是如何执行任务的,直接贴源码,因为用线程池执行任务,无论是使用execute方法还是使用submit方法,最终都是会调用execute方法,所以直接贴出execute方法的源码
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. * 这段注释就是介绍的线程池的执行流程,后面有翻译成中文的说明。 */ int c = ctl.get(); // 1. 如果当前运行的线程数少于 corePoolSize,尝试启动一个新线程并将其给定的任务作为第一个任务。 if (workerCountOf(c) < corePoolSize) { // 调用 addWorker 方法会原子性地检查 runState 和 workerCount,通过返回 false 来防止在不应该添加线程时的误报。 if (addWorker(command, true)) return; c = ctl.get(); } // 2. 如果任务可以成功排队,那么我们仍然需要再次检查是否应该添加一个线程(因为自上次检查以来已有线程死亡) if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); // 或者在此方法进入后线程池已关闭。因此我们需要重新检查状态,如果停止则回滚入队操作,或者在没有线程的情况下启动新线程。 if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } // 3. 如果我们无法将任务加入队列,则尝试添加一个新线程。如果失败,我们知道线程池已经关闭或饱和,因此拒绝该任务。 else if (!addWorker(command, false)) reject(command); } 执行步骤
- 如果当前运行的线程数少于
corePoolSize,尝试启动一个新线程并将其给定的任务作为第一个任务。调用addWorker方法会原子性地检查runState和workerCount,通过返回false来防止在不应该添加线程时的误报。 - 如果任务可以成功排队,那么我们仍然需要再次检查是否应该添加一个线程(因为自上次检查以来已有线程死亡)或者在此方法进入后线程池已关闭。因此我们需要重新检查状态,如果停止则回滚入队操作,或者在没有线程的情况下启动新线程。
- 如果我们无法将任务加入队列,则尝试添加一个新线程。如果失败,我们知道线程池已经关闭或饱和,因此拒绝该任务。
通过上面这段源码,我们可以看出来,最核心的,用来执行任务的方法就是addWorker那就也看看addWorker是如何执行的。
private boolean addWorker(Runnable firstTask, boolean core) { // 检查代码逻辑省略 boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { //1. 创建一个worker对象,firstTask作为传递给worker的任务。 w = new Worker(firstTask); // 2. 创建完worker对象后,会从线程池里面拿出一个线程用来执行worker final Thread t = w.thread; if (t != null) { // 3. 由于线程池需要保持对工作线程集合(workers)的同步访问,线程池会用一个锁来保护执行任务的逻辑。 final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int c = ctl.get(); // 4. 先判断线程池是否处于运行状态, // 若线程池没有关闭且任务有效,则允许添加工作线程。 if (isRunning(c) || (runStateLessThan(c, STOP) && firstTask == null)) { // 5. 确保新创建出来的线程状态是NEW,即尚未开始执行。 if (t.getState() != Thread.State.NEW) throw new IllegalThreadStateException(); // 6. 将worker对象添加到工作线程集合(workers)中。 workers.add(w); workerAdded = true; int s = workers.size(); if (s > largestPoolSize) // 7. 更新largestPoolSize, // 记录线程池中最大线程数,方便监控线程池负载情况。 largestPoolSize = s; } } finally { mainLock.unlock(); } // 8. worker对象添加到工作线程集合成功,开始启动工作线程执行worker。 if (workerAdded) { container.start(t); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; } - 创建一个
worker对象,firstTask作为传递给worker的任务。 - 创建完
worker对象后,会从线程池里面拿出一个线程用来执行worker,如果能从线程池中拿到线程,接下来就用这个线程开始执行worker。 - 由于线程池需要保持对工作线程集合(
workers)的同步访问,线程池会用一个锁来保护执行任务的逻辑。 - 先判断线程池是否处于运行状态,若线程池没有关闭且任务有效,则允许添加工作线程。
- 确保新创建出来的线程状态是
NEW,即尚未开始执行。 - 将
worker对象添加到工作线程集合(workers)中。 - 更新
largestPoolSize,记录线程池中最大线程数,方便监控线程池负载情况。 worker对象添加到工作线程集合成功,开始启动工作线程执行worker。
那么线程池的线程数具体应该设置成多少呢?
这个问题,面试官一般不是想听到你给出一个具体的数值,而是想听到的是你的一个思考过程,就算你回答出来了一个具体数值,也会问你为什么是这个值。
影响线程池线程数量的因素
CPU核数
,多核处理器当然是每个CPU运行一个线程最高效,但是随着技术的发展现在很多的CPU都有了超线程技术,也就是利用特殊的硬件指令,将两个逻辑内核模拟成物理处理器,单核处理器可以让线程并行执行,所以会看到有“4核8线程的CPU”。任务类型
,- CPU密集型,这种任务的核心线程数最好设置成cpu数的1至1.5倍
- I/O密集型,有阻塞有等待的任务,例如:数据库连接,文件操作,网络传输等,可以将核心线程数量设置成cpu数量的2倍,利用阻塞时间让其他CPU去干更多的事情。
JVM和系统资源
- 内存限制,每个线程占用一定的内存,线程过多有内存溢出的风险。
- 操作系统限制,通常操作系统对单个进程可创建的线程也是有数量限制的,数量过多会降低系统效率。
- 并发量与响应时间
- 高并发场景:增加线程数,但需避免资源竞争。
- 快速响应需求:减少任务等待时间,适当增加线程数或队列容量。
具体该怎么设置线程数量呢?
网上流传着一些固定的公式来告诉大家如何配置核心线程数量。
就是基于简单因素考虑,在主要参考CPU和任务类型时:
- CPU密集型任务,线程池的线程数量配置为(
CPU数量+1)
; - I/O密集型任务,线程池的线程数量配置为(
2*CPU数量)+1
;
由于无法根据具体的指标判断任务类型到底是CPU密集型还是I/O密集型,所以又有了,下面一个公式:

等段时间
,线程执行过程中等待外部操作完成的时间。在等待时间内,线程通常不占用CPU资源。
计算时间
,通常指线程实际计算处理的时间。
不建议直接套用公式
虽然网上流传了这些公式,但是并不是这个公式就是万能呢,很多时候我们的任务在执行的时候要考虑的因素有很多。而且现在很多服务器都是虚拟机,并不能真正的发挥出物理机的全部能力,所以很多依赖因素也是不准确的。
所以建议用以下的方式来进行配置:
- 可以在刚上线的时候,先根据公式大致的设置一个数值,然后再根据你自己的实际业务情况,以及不断的压测结果,再不断调整,最终达到一个相对合理的值。
- 也可以结合监控工具(如
Prometheus、Grafana)实时检测线程池的线程数量,然后再通过ThreadPoolExecutor.setCorePoolSize()和setMaximumPoolSize()动态修改参数。一些成熟的动态线程池框架,比如dynamicTp,不仅支持线程数调整,还支持队列容量和拒绝策略的调整。
ForkJoinPool和ThreadPoolExecutor有什么区别?
ForkJoinPool是基于工作窃取(
Work-Stealing
)算法实现的线程池,ForkJoinPool 中每个线程都有自己的工作队列,用于存储待执行的任务。当一个线程执行完自己的任务之后,会从其他线程的工作队列中窃取任务执行,以此来实现任务的动态均衡和线程的利用率最大化。 ThreadPoolExecutor 是基于任务分配(
Task-Assignment
)算法实现的线程池,ThreadPoolExecutor 中线程池中有一个共享的工作队列,所有任务都将提交到这个队列中。线程池中的线程会从队列中获取任务执行,如果队列为空,则线程会等待,直到队列中有任务为止。 ForkJoinPool的任务调度是通过fork()拆分,再通过join() 合并结果,支持递归分治。
默认线程数等于 CPU 核心数(Runtime.getRuntime().availableProcessors()),支持动态调整。
通过 ForkJoinTask 的异常传播机制处理子任务异常。
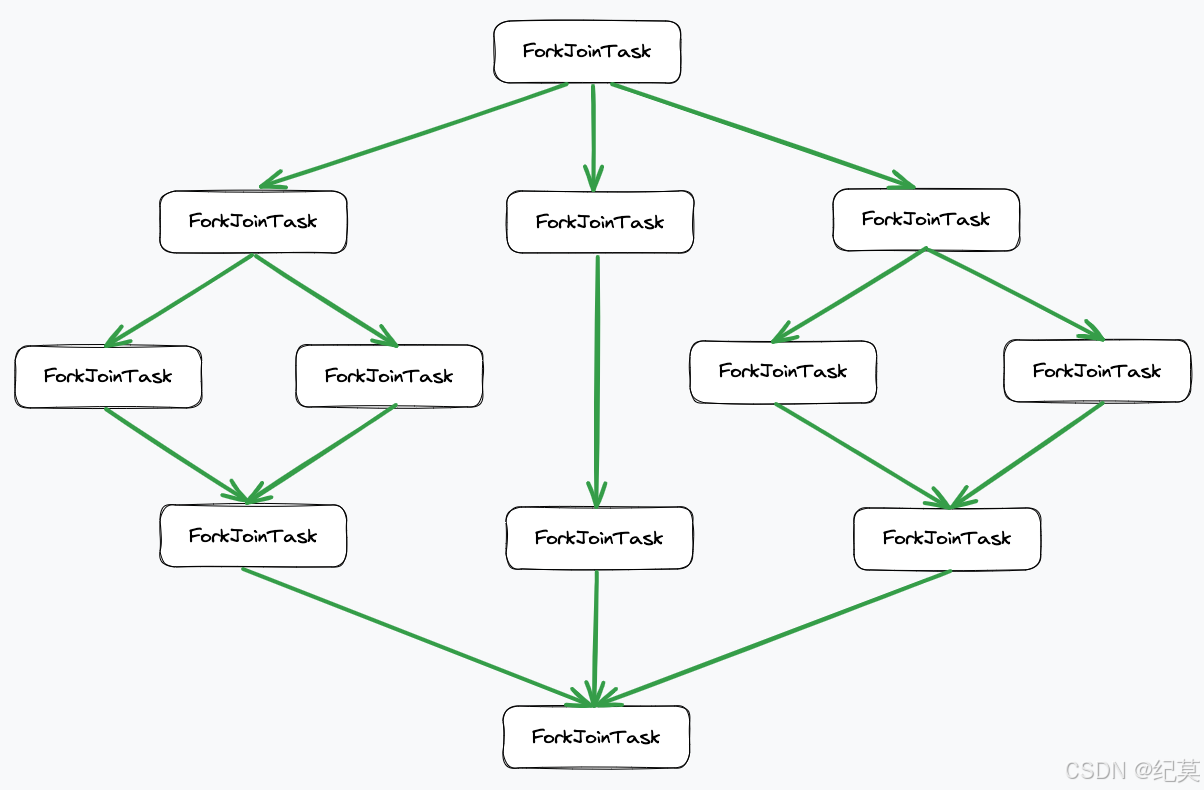
ForkJoinPool 中的工作线程是一种特殊的线程,与普通线程池中的工作线程有所不同。
它们会自动地创建和销毁,以及自动地管理线程的数量和调度。
这种方式可以降低线程池的管理成本,提高线程的利用率和并行度。
提交任务方式与使用场景
提交任务
| 特性 | ForkJoinPool | ThreadPoolExecutor |
|---|---|---|
| 任务类型 | 必须继承 ForkJoinTask 的子类(如 RecursiveAction 或 RecursiveTask)。 | 提交普通 Runnable 或 Callable 任务。 |
| 任务提交方法 | 使用 submit(ForkJoinTask) 或 invoke(ForkJoinTask)。 | 使用 execute(Runnable) 或 submit(Callable/Runnable)。 |
| 任务依赖性 | 任务间存在依赖关系 (需合并子任务结果)。 | 任务间独立,无依赖关系。 |
使用场景
| ForkJoinPool | ThreadPoolExecutor |
|---|---|
| 并行计算(如数组求和、归并排序); 分治算法(如矩阵乘法); - Java 并行流( parallelStream()); | 网络请求处理; -文件批量处理; 定时任务(如 ScheduledThreadPoolExecutor); |
CompletableFuture底层就是用ForkJoinPool来实现。
代码示例
public class SumTask extends RecursiveTask<Long> { private final long[] array; private final int start, end; private static final int THRESHOLD = 1000; public SumTask(long[] array, int start, int end) { this.array = array; this.start = start; this.end = end; } @Override protected Long compute() { if (end - start <= THRESHOLD) { long sum = 0; for (int i = start; i < end; i++) sum += array[i]; return sum; } else { int mid = (start + end) / 2; SumTask left = new SumTask(array, start, mid); SumTask right = new SumTask(array, mid, end); left.fork(); // 异步执行左子任务 return left.join() + right.compute(); // 合并结果 } } } public static void main(String[] args) { // 使用 ForkJoinPool ForkJoinPool pool = new ForkJoinPool(); long[] data = new long[1000000]; // 初始化 data for(int i=0;i<data.length;i++){ data[i] = i; } // 执行任务 Long result = pool.invoke(new SumTask(data, 0, data.length)); } 









这一切,似未曾拥有