





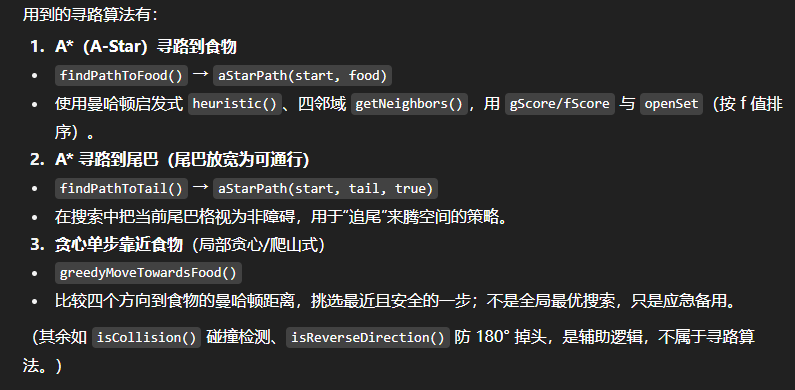
第三个是grok4,grok4最简洁,没有输出任何说明,只有代码。我把代码拿到后问了其他AI,它的算法主要还是A*,最终止步于79分
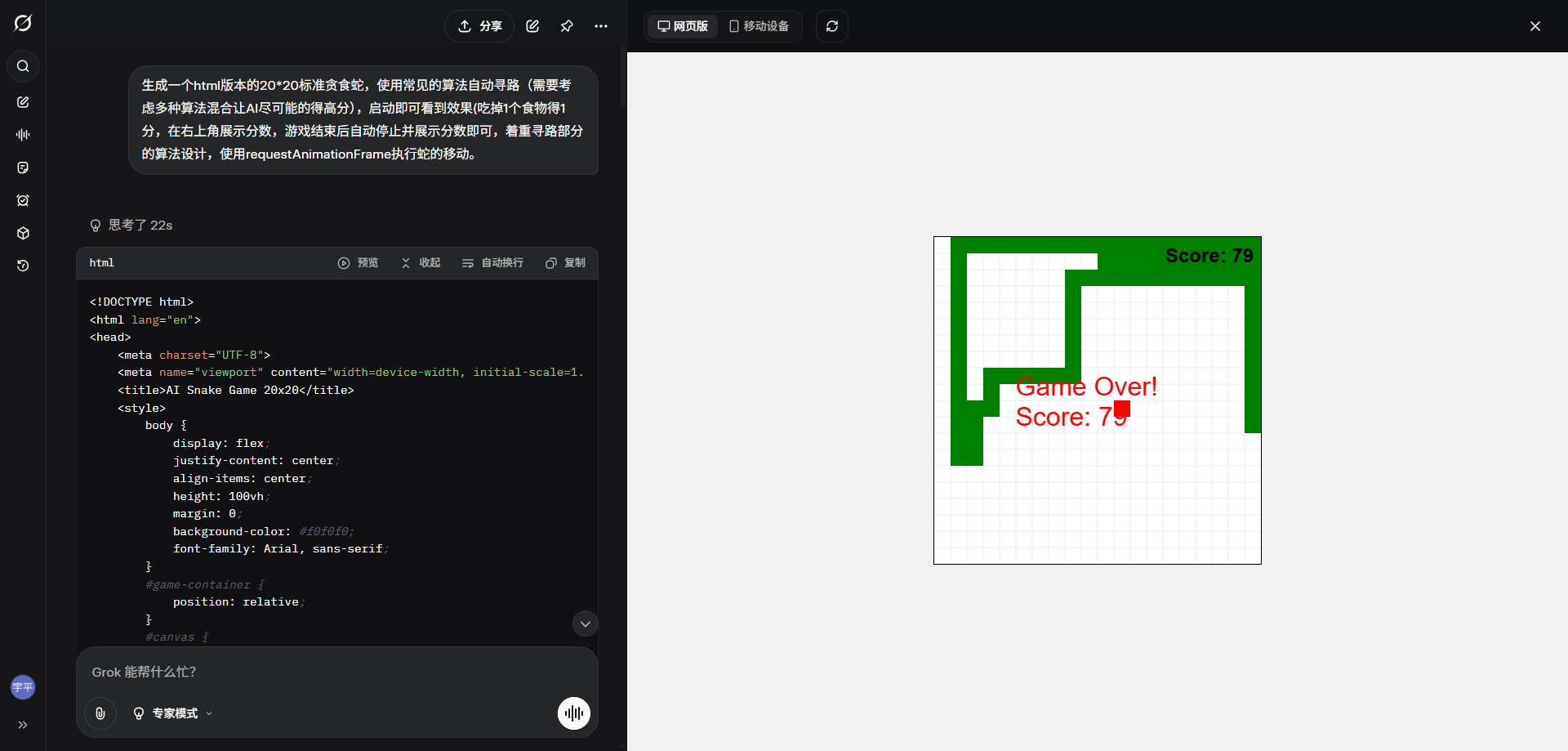
第四个是claude sonnet 4,也是A*+哈密顿路径,最终止步52分。
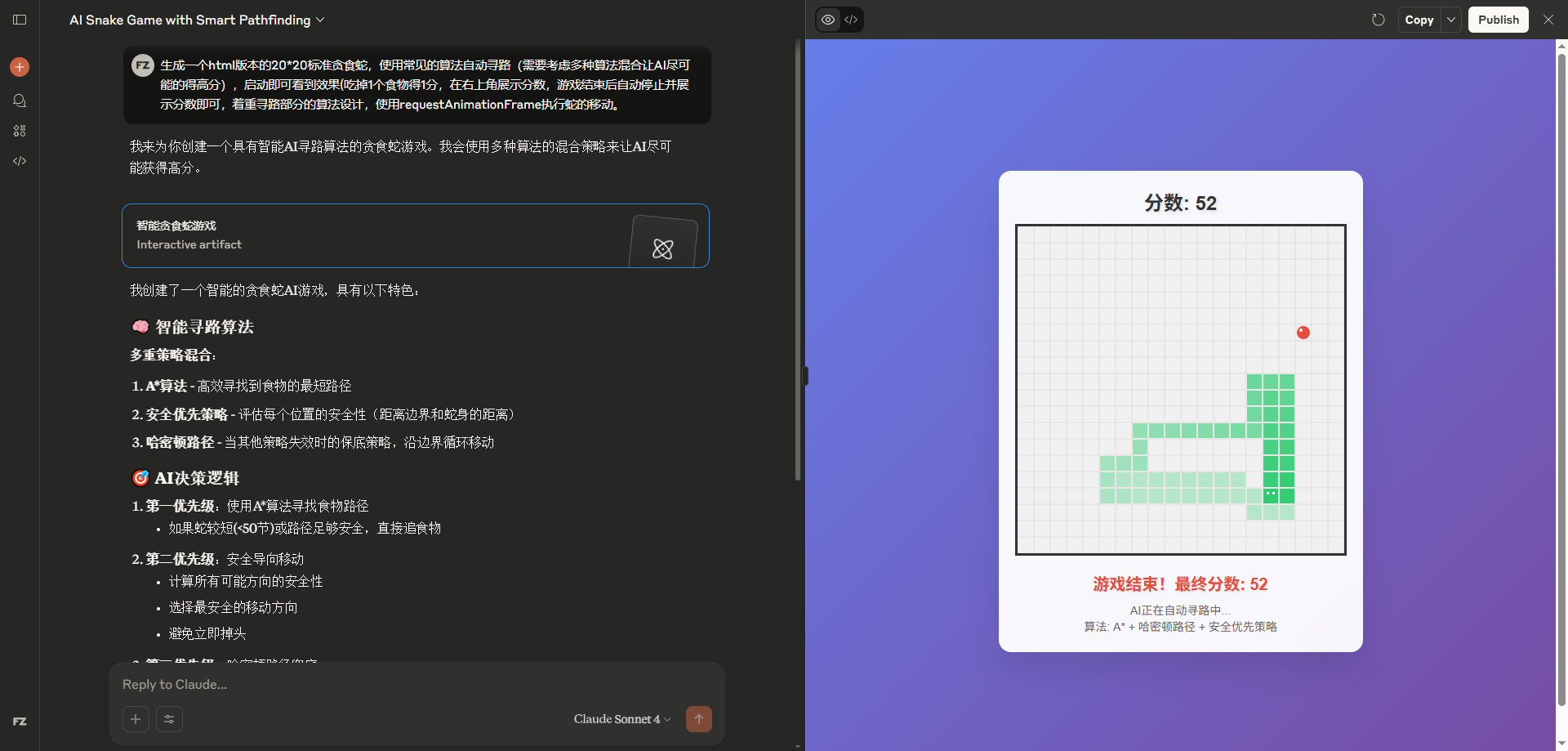
接下来上场的是deepseek-v3.1-思考模式,它同样使用了BFS,但是偶发性的每次初始化刷新会出现2个食物(这在其他几个AI的代码里没有出现过,算BUG),最终的分53
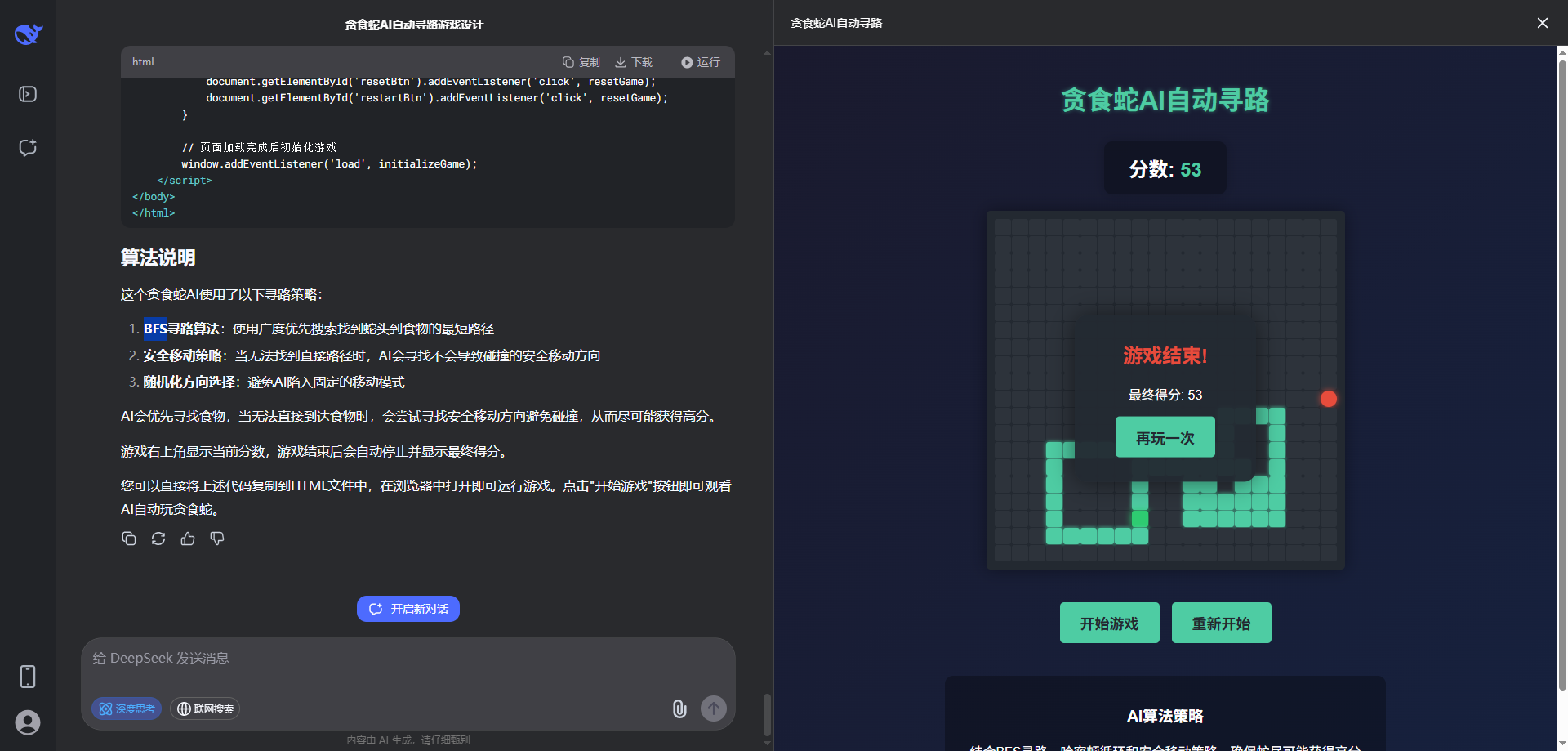
接着是kimi-k2,由于它的代码有点错乱(尝试两次均如此),遂我自行粘贴到html单页运行如下结果,它也是A*+哈密顿+贪心,最终得分2分。

然后是Qwen3-235B-A22B-2507-思考模式,同样的以BFS作为主要手段,另外它也有一个BUG就是第20列格子被遮挡了没有展示完全,最终得分80分:
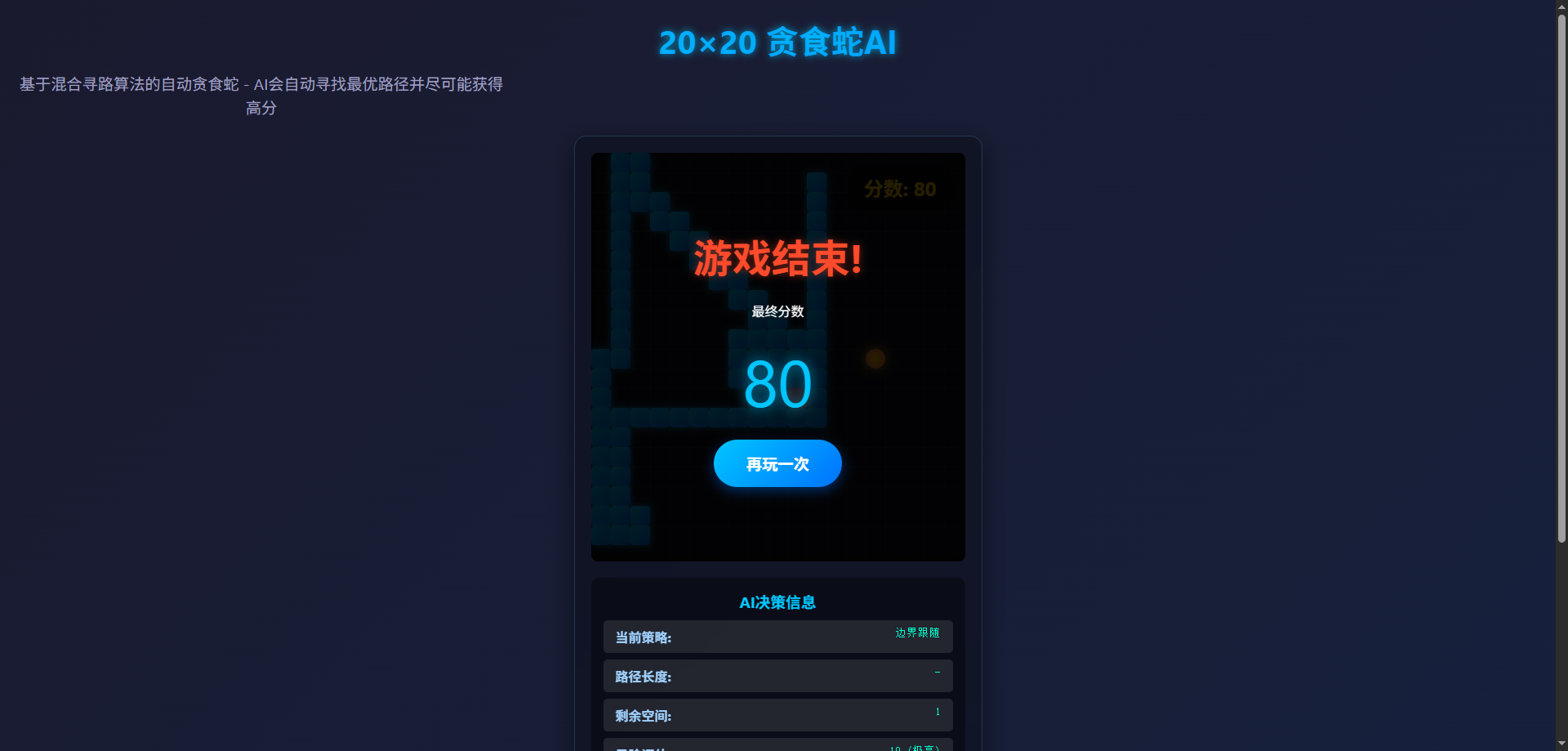
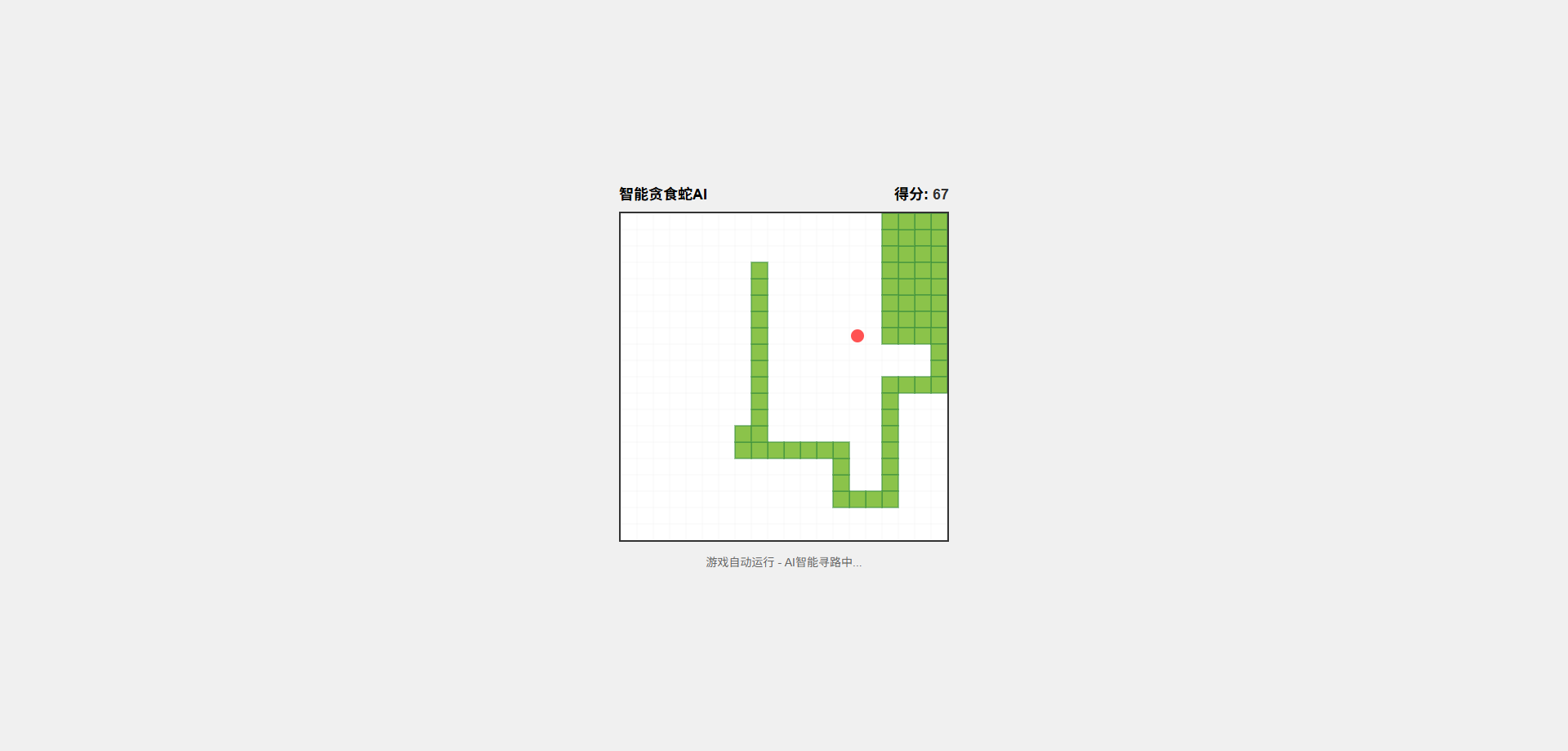
最后压轴的是Qwen3-Coder,它也主要采用了A*,最终得分67分:

以上内容均为单次提示词输出(kimi由于第二次输出的格式混乱故采用的第一次输出的内容自行拼接),所有运行的html代码也仅为单次运行结果。不排除大模型本身输出不确定性和游戏本身的随机性,结果仅供娱乐!!!















这一切,似未曾拥有