
深入浅出了解生成模型
更加好的排版:https://www.big-yellow-j.top/posts/2025/07/06/DFBaseModel.html
基座扩散模型
主要介绍基于Unet以及基于Dit框架的基座扩散模型,其中SD迭代版本挺多的(从1.2到3.5)因此本文主要重点介绍SD 1.5以及SDXL两个基座模型,以及两者之间的对比差异,除此之外还有许多闭源的扩散模型比如说Imagen、DALE等。对于Dit基座模型主要介绍:Hunyuan-DiT、FLUX.1等。对于各类模型评分网站(模型评分仁者见仁智者见智,特别是此类生成模型视觉图像生成是一个很主观的过程,同一张图片不同人视觉感官都是不同的):https://lmarena.ai/leaderboard
SDv1.5 vs SDXL[1]
SDv1.5
: https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5
SDXL
:https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
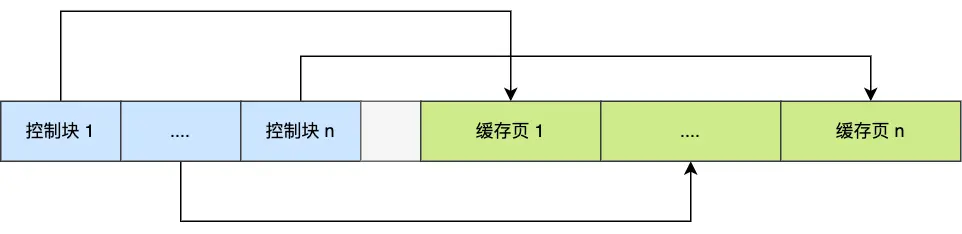
两者模型详细的模型结构:SDv1.5--SDXL模型结构图,其中具体模型参数的对比如下:
1、CLIP编码器区别
:在SD1.5中选择的是
CLIP-ViT/L
(得到的维度为:768)而在SDXL中选择的是两个CLIP文本编码器:OpenCLIP-ViT/G
(得到的维度为:1280)以及CLIP-ViT/L
(得到维度为:768)在代码中对于两个文本通过编码器处理之后SDXL直接通过cat方式拼接:prompt_embeds = torch.concat(prompt_embeds_list, dim=-1) 也就是说最后得到的维度为:[..,..,1280+768]。最后效果很明显:SDXL对于文本的理解能力大于SD1.5
2、图像输出维度区别
:再SD1.5中的默认输出是:512x512而再SDXL中的默认输出是:1024x1024,如果希望将SD1.5生成的图像处理为1024x1024可以直接通过超分算法来进行处理,除此之外在SDXL中还会使用一个refiner模型(和Unet的结构相似)来强化base模型(Unet)生成的效果。
3、SDXL论文中的技术细节
:- 1、
图像分辨率优化策略
。
数据集中图像的尺寸图像利用率问题(选择512x512舍弃256x256就会导致图像大量被舍弃)如果通过超分辨率算法将图像就行扩展会放大伪影,这些伪影可能会泄漏到最终的模型输出中,例如,导致样本模糊。(The second method, on the other hand, usually introduces upscaling artifacts which may leak into the final model outputs, causing, for example, blurry samples.)作者做法是:
训练阶段
直接将原始图像的分辨率 \(c=(h_{org},w_{org})\)作为一个条件,通过傅里叶特征编码而后加入到time embedding中,推理阶段
直接将分辨率作为一个条件就行嵌入,进而实现:当输入低分辨率条件时,生成的图像较模糊;在不断增大分辨率条件时,生成的图像质量不断提升。

- 2、
图像裁剪优化策略
直接统一采样裁剪坐标top和cleft(分别指定从左上角沿高度和宽度轴裁剪的像素数量的整数),并通过傅里叶特征嵌入将它们作为调节参数输入模型,类似于上面描述的尺寸调节。第1,2点代码中的处理方式为:
def _get_add_time_ids( self, original_size, crops_coords_top_left, target_size, dtype, text_encoder_projection_dim=None ): add_time_ids = list(original_size + crops_coords_top_left + target_size) passed_add_embed_dim = ( self.unet.config.addition_time_embed_dim * len(add_time_ids) + text_encoder_projection_dim ) expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features ... add_time_ids = torch.tensor([add_time_ids], dtype=dtype) return add_time_ids 推荐阅读
:
1、SDv1.5-SDXL-SD3生成效果对比
Imagen
https://imagen.research.google/
https://deepmind.google/models/imagen/
非官方实现:https://github.com/lucidrains/imagen-pytorch
类似Github,通过3阶段生成:https://github.com/deep-floyd/IF
Imagen[2]论文中主要提出:1、纯文本语料库上预训练的通用大型语言模型(例如T5、CLIP、BERT等)在编码图像合成的文本方面非常有效:在Imagen中增加语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和Imagetext对齐。
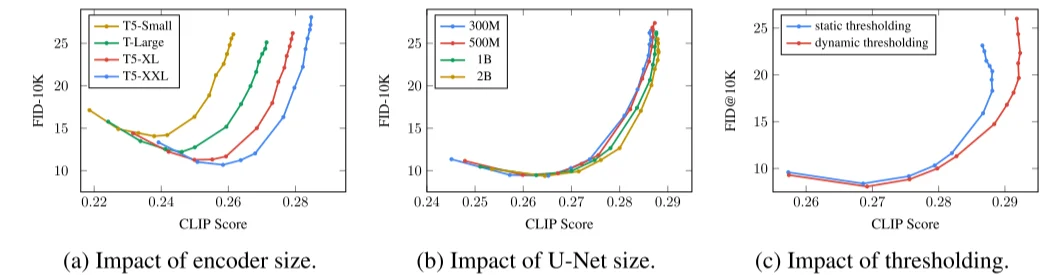
2、通过提高classifier-free guidance weight(\(\epsilon(z,c)=w\epsilon(z,c)+ (1-w)\epsilon(z)\) 也就是其中的参数 \(w\))可以提高image-text之间的对齐,但会损害图像逼真度,产生高度饱和不自然的图像(论文里面给出的分析是:每个时间步中预测和正式的x都会限定在 \([-1,1]\)这个范围但是较大的 \(w\)可能导致超出这个范围),论文里面做法就是提出
动态调整方法
:在每个采样步骤中,我们将s设置为 \(x_0^t\)中的某个百分位绝对像素值,如果s>1,则我们将 \(x_0^t\)阈值设置为范围 \([-s,s]\),然后除以s。
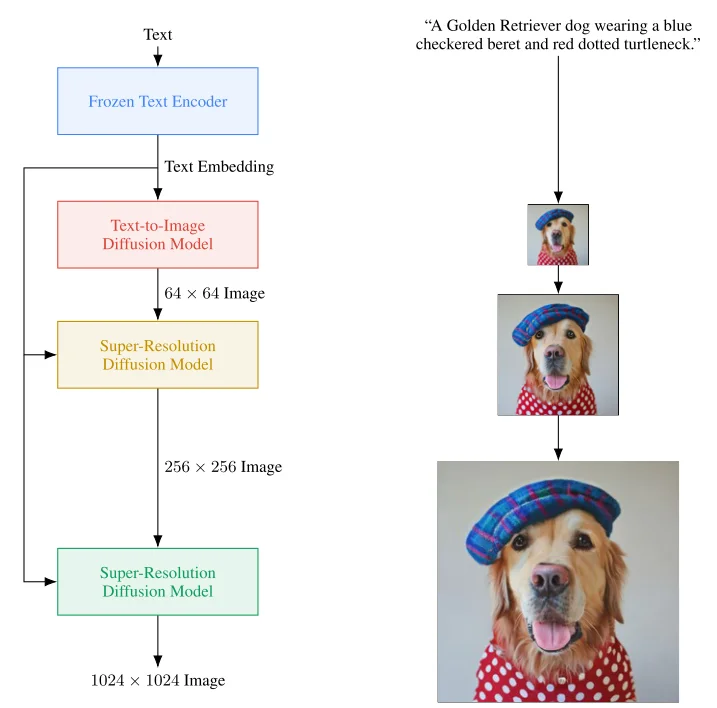
3、和上面SD模型差异比较大的一点就是,在imagen中直接使用多阶段生成策略,模型先生成64x64图像再去通过超分辨率扩散模型去生成256x256以及1024x1024的图像,在此过程中作者提到使用noise conditioning augmentation(NCA)策略(
对输入的文本编码后再去添加随机噪声
)
Dit
https://github.com/facebookresearch/DiT
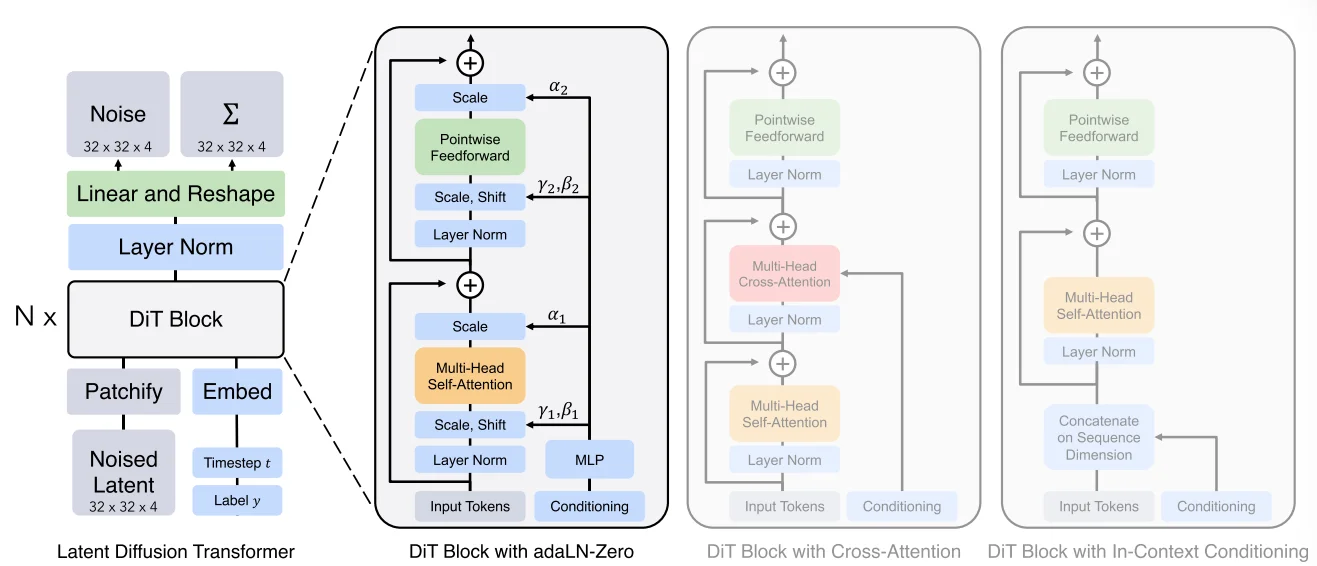
Dit[3]模型结构上,1、
模型输入
,将输入的image/latent切分为不同patch而后去对不同编码后的patch上去添加位置编码(直接使用的sin-cos位置编码),2、时间步以及条件编码
,对于时间步t以及条件c的编码而后将两部分编码后的内容进行相加,在TimestepEmbedder上处理方式是:直接通过正弦时间步嵌入
方式而后将编码后的内容通过两层liner处理;在LabelEmbedder处理方式上就比较简单直接通过nn.Embedding进行编码处理。3、使用Adaptive layer norm(adaLN)block以及adaZero-Block(对有些参数初始化为0,就和lora中一样初始化AB为0,为了保证后续模型训练过程中的稳定) 在layernorm中一般归一化处理方式为:\(\text{Norm}(x)=\gamma \frac{x-\mu}{\sqrt{\sigma^2+ \epsilon}}+\beta\) 其中有两个参数 \(\gamma\) 和 \(\beta\) 是固定的可学习参数(比如说直接通过
nn.Parameter进行创建),在模型初始化时创建,并在训练过程中通过梯度下降优化。但是在 adaLN中则是直接通过 \(\text{Norm}(x)=\gamma(c) \frac{x-\mu}{\sqrt{\sigma^2+ \epsilon}}+\beta(c)\) 通过输入的条件c进行学习的,
Hunyuan-DiT
https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
腾讯的Hunyuan-DiT[4]模型整体结构
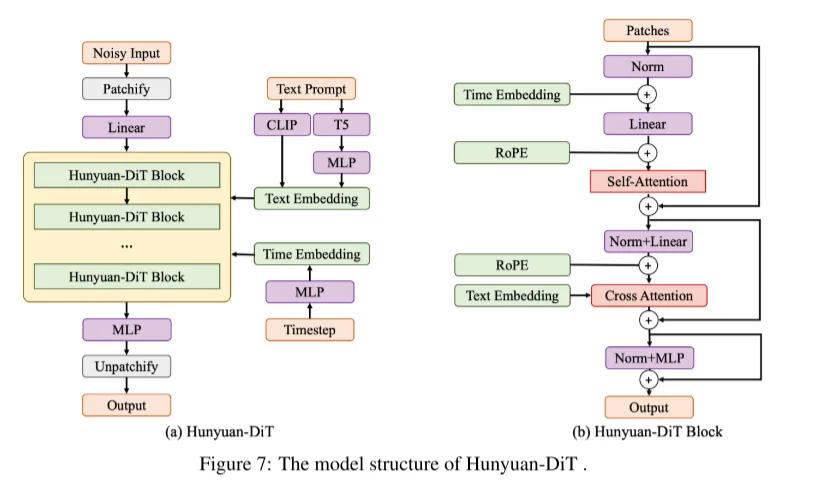
整体框架不是很复杂,1、文本编码上直接通过结合两个编码器:CLIP、T5;2、VAE则是直接使用的SD1.5的;3、引入2维的旋转位置编码;4、在Dit结构上(图片VAE压缩而后去切分成不同patch),使用的是堆叠的注意力模块(在SD1.5中也是这种结构)self-attention+cross-attention(此部分输入文本)。论文里面做了改进措施:1、借鉴之前处理,计算attention之前首先进行norm处理(也就是将norm拿到attention前面)。
简短了解一下模型是如何做数据的:
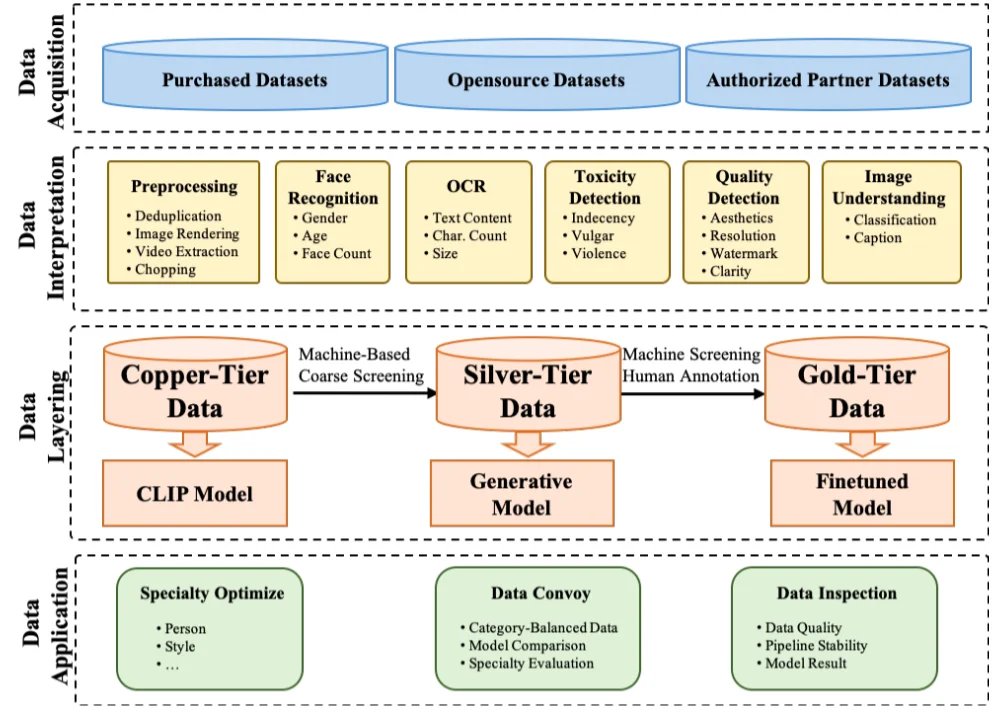
PixArt
https://pixart-alpha.github.io/
华为诺亚方舟实验室提出的 \(\text{PixArt}-\alpha\)模型整体框架如下:
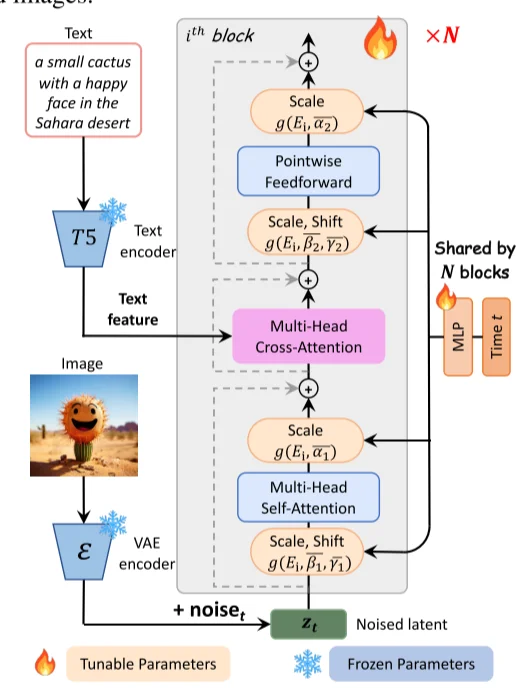
相比较Dit模型论文里面主要进行的改进如下:
1、
Cross-Attention layer
,在DiT block中加入了一个多头交叉注意力层,它位于自注意力层(上图中的Multi-Head Self-Attention)和前馈层(Pointwise Feedforward)之间,使模型能够灵活地引入文本嵌入条件。此外,为了利用预训练权重,将交叉注意力层中的输出投影层初始化为零,作为恒等映射,保留了输入以供后续层使用。
2、AdaLN-single,在Dit中的adaptive normalization layers(adaLN)中部分参数(27%)没有起作用(在文生图任务中)将其替换为adaLN-single
不同模型参数对生成的影响
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#stable-diffusion-20
- 参数
guidance_rescale对于生成的影响
引导扩散模型(如 Classifier-Free Guidance,CFG)中,用于调整文本条件对生成图像的影响强度。它的核心作用是控制模型在生成过程中对文本提示的“服从程度”。公式上,CFG 调整预测噪声的方式如下:
\[\epsilon = \epsilon_{\text{uncond}} + \text{guidance\_scale} \cdot (\epsilon_{\text{cond}} - \epsilon_{\text{uncond}}) \]其中:1、\(\epsilon_{\text{cond}}\):基于文本条件预测的噪声。2、\(\epsilon_{\text{uncond}}\):无条件(无文本提示)预测的噪声。3、guidance_scale:决定条件噪声相对于无条件噪声的权重。得到最后测试结果如下(参数分别为[1.0, 3.0, 5.0, 7.5, 10.0, 15.0, 20.0],prompt = "A majestic lion standing on a mountain during golden hour, ultra-realistic, 8k", negative_prompt = "blurry, distorted, low quality"),容易发现数值越大文本对于图像的影响也就越大。

其中代码具体操作如下,从代码也很容易发现上面计算公式中的 uncond代表的就是我的negative_prompt,也就是说
CFG做的就是negative_prompt对生成的影响
:if self.do_classifier_free_guidance: prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0) add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0) add_neg_time_ids = add_neg_time_ids.repeat(batch_size * num_images_per_prompt, 1) add_time_ids = torch.cat([add_neg_time_ids, add_time_ids], dim=0) prompt_embeds = prompt_embeds.to(device) Adapters
https://huggingface.co/docs/diffusers/tutorials/using_peft_for_inference
此类方法是在完备的 DF 权重基础上,额外添加一个“插件”,保持原有权重不变。我只需修改这个插件,就可以让模型生成不同风格的图像。可以理解为在原始模型之外新增一个“生成条件”,通过修改这一条件即可灵活控制模型生成各种风格或满足不同需求的图像。
ControlNet
https://github.com/lllyasviel/ControlNet
建议直接阅读:https://github.com/lllyasviel/ControlNet/discussions/categories/announcements 来了解更加多细节
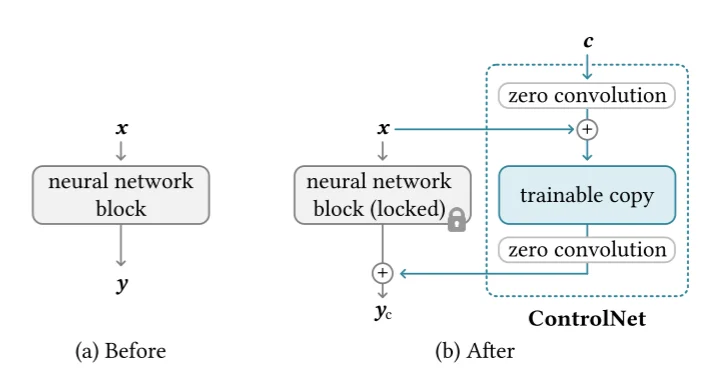
ControlNet[5]的处理思路就很简单,再左图中模型的处理过程就是直接通过:\(y=f(x;\theta)\)来生成图像,但是在ControlNet里面会
将我们最开始的网络结构复制
然后通过在其前后引入一个zero-convolution
层来“指导”( \(Z\) )模型的输出也就是说将上面的生成过程变为:\(y=f(x;\theta)+Z(f(x+Z(c;\theta_{z_1});\theta);\theta_{Z_2})\)。通过冻结最初的模型的权重保持不变,保留了Stable Diffusion模型原本的能力;与此同时,使用额外数据对“可训练”副本进行微调,学习我们想要添加的条件。因此在最后我们的SD模型中就是如下一个结构: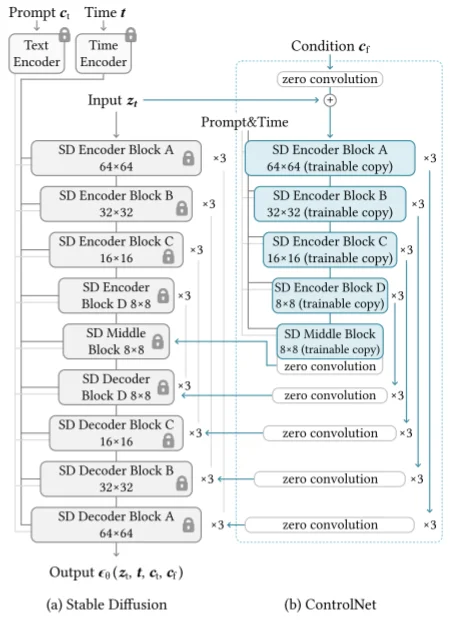
在论文里面作者给出一个实际的测试效果可以很容易理解里面条件c(条件 𝑐就是提供给模型的显式结构引导信息,
用于在生成过程中精确控制图像的空间结构或布局
,一般来说可以是草图、分割图等)到底是一个什么东西,比如说就是直接给出一个“线稿”然后模型来输出图像。
补充-1
:为什么使用上面这种结构
在github上作者讨论了为什么要使用上面这种结构而非直接使用mlp等(作者给出了很多测试图像),最后总结就是:这种结构好
补充-2
:使用0卷积层会不会导致模型无法优化问题?
不会,因为对于神经网络结构大多都是:\(y=wx+b\)计算梯度过程中即使 \(w=0\)但是里面的 \(x≠0\)模型的参数还是可以被优化的
ControlNet代码操作
Code: https://github.com/shangxiaaabb/ProjectCode/tree/main/code/Python/DFModelCode/training_controlnet
模型权重:
首先
,简单了解一个ControlNet数据集格式,一般来说数据主要是三部分组成:1、image(可以理解为生成的图像);2、condiction_image(可以理解为输入ControlNet里面的条件 \(c\));3、text。比如说以raulc0399/open_pose_controlnet为例
模型加载
,一般来说扩散模型就只需要加载如下几个:DDPMScheduler、AutoencoderKL(vae模型)、UNet2DConditionModel(不一定加载条件Unet模型),除此之外在ControlNet中还需要加载一个ControlNetModel。对于ControlNetModel中代码大致结构为,代码中通过self.controlnet_down_blocks来存储ControlNet的下采样模块(初始化为0的卷积层
)。self.down_blocks用来存储ControlNet中复制的Unet的下采样层。在forward中对于输入的样本(sample)首先通过 self.down_blocks逐层处理叠加到 down_block_res_samples中,而后就是直接将得到结果再去通过 self.controlnet_down_blocks每层进行处理,最后返回下采样的每层结果以及中间层处理结果:down_block_res_samples,mid_block_res_sample class ControlNetModel(ModelMixin, ConfigMixin, FromOriginalModelMixin): @register_to_config def __init__(...): ... self.down_blocks = nn.ModuleList([]) self.controlnet_down_blocks = nn.ModuleList([]) # 封装下采样过程(对应上面模型右侧结构) controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1) controlnet_block = zero_module(controlnet_block) self.controlnet_down_blocks.append(controlnet_block) for i, down_block_type in enumerate(down_block_types): # down_block_types就是Unet里面下采样的每一个模块比如说:CrossAttnDownBlock2D ... down_block = get_down_block(down_block_type) # 通过 get_down_block 获取uet下采样的模块 self.down_blocks.append(down_block) for _ in range(layers_per_block): controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1) controlnet_block = zero_module(controlnet_block) self.controlnet_down_blocks.append(controlnet_block) @classmethod def from_unet(cls, unet,...): ... # 通过cls实例化的类本身ControlNetModel controlnet = cls(...) if load_weights_from_unet: # 将各类权重加载到 controlnet 中 controlnet.conv_in.load_state_dict(unet.conv_in.state_dict()) controlnet.time_proj.load_state_dict(unet.time_proj.state_dict()) ... return controlnet def forward(...): ... # 时间编码 t_emb = self.time_proj(timesteps) emb = self.time_embedding(t_emb, timestep_cond) if self.class_embedding is not None: ... class_emb = self.class_embedding(class_labels).to(dtype=self.dtype) emb = emb + class_emb # 对条件进行编码 if self.config.addition_embed_type is not None: if self.config.addition_embed_type == "text": aug_emb = self.add_embedding(encoder_hidden_states) elif self.config.addition_embed_type == "text_time": time_ids = added_cond_kwargs.get("time_ids") time_embeds = self.add_time_proj(time_ids.flatten()) time_embeds = time_embeds.reshape((text_embeds.shape[0], -1)) add_embeds = torch.concat([text_embeds, time_embeds], dim=-1) add_embeds = add_embeds.to(emb.dtype) aug_emb = self.add_embedding(add_embeds) emb = emb + aug_emb if aug_emb is not None else emb sample = self.conv_in(sample) controlnet_cond = self.controlnet_cond_embedding(controlnet_cond) sample = sample + controlnet_cond # 下采样处理 down_block_res_samples = (sample,) for downsample_block in self.down_blocks: if ... ... else: sample, res_samples = downsample_block(hidden_states=sample, temb=emb) down_block_res_samples += res_samples # 中间层处理 ... # 将输出后的内容去和0卷积进行叠加 controlnet_down_block_res_samples = () for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks): down_block_res_sample = controlnet_block(down_block_res_sample) controlnet_down_block_res_samples = controlnet_down_block_res_samples + (down_block_res_sample,) ... if not return_dict: return (down_block_res_samples, mid_block_res_sample) ... 模型训练
,训练过程和DF训练差异不大。将图像通过VAE处理、产生噪声、时间步、将噪声添加到(VAE处理之后的)图像中,而后通过controlnet得到每层下采样的结果以及中间层结果:down_block_res_samples, mid_block_res_sample = controlnet(...)而后将这两部分结果再去通过unet处理 model_pred = unet( noisy_latents, timesteps, encoder_hidden_states=encoder_hidden_states, down_block_additional_residuals=[ sample.to(dtype=weight_dtype) for sample in down_block_res_samples ], mid_block_additional_residual=mid_block_res_sample.to(dtype=weight_dtype), return_dict=False, )[0] 后续就是计算loss等处理
模型验证
,直接就是使用StableDiffusionControlNetPipeline来处理了。最后随机测试的部分例子(controlnet微调效果不是很好):
T2I-Adapter
https://github.com/TencentARC/T2I-Adapter
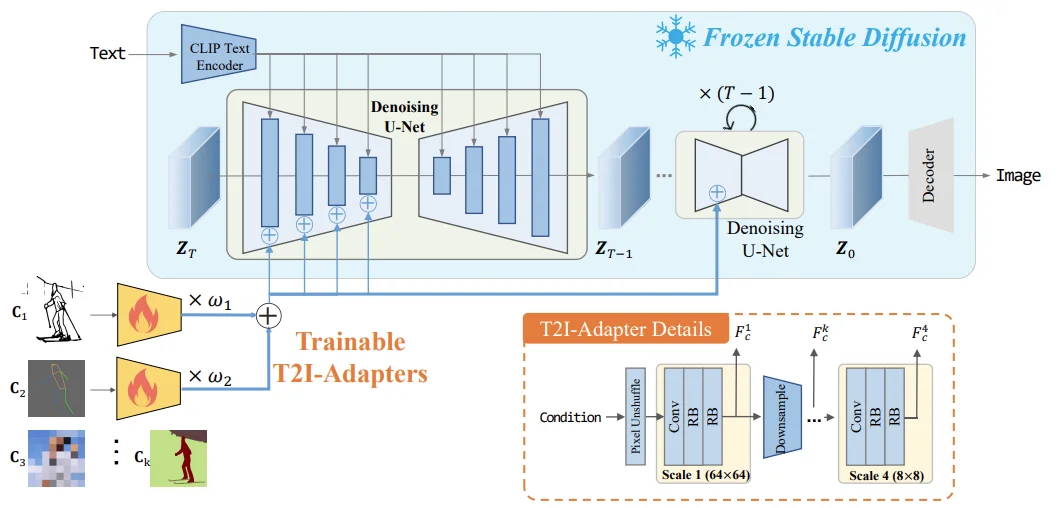
T2I[6]的处理思路也比较简单(T2I-Adap 4 ter Details里面其实就写的很明白了),对于输入的条件图片(比如说边缘图像):512x512,首先通过 pixel unshuffle进行下采样将图像分辨率改为:64x64而后通过一层卷积+两层残差连接,输出得到特征 \(F_c\)之后将其与对应的encoder结构进行相加:\(F_{enc}+ F_c\),当然T2I也支持多个条件(直接通过加权组合就行)
DreamBooth
https://huggingface.co/docs/diffusers/v0.34.0/using-diffusers/dreambooth
论文[7]里面主要出发点就是:1、解决
language drif
(语言偏离问题):指的是模型通过后训练(微调等处理之后)模型丧失了对某些语义特征的感知,就比如说扩散模型里面,模型通过不断微调可能就不知道“狗”是什么从而导致模型生成错误。2、高效的生成需要的对象,不会产生:生成错误、细节丢失问题,比如说下面图像中的问题: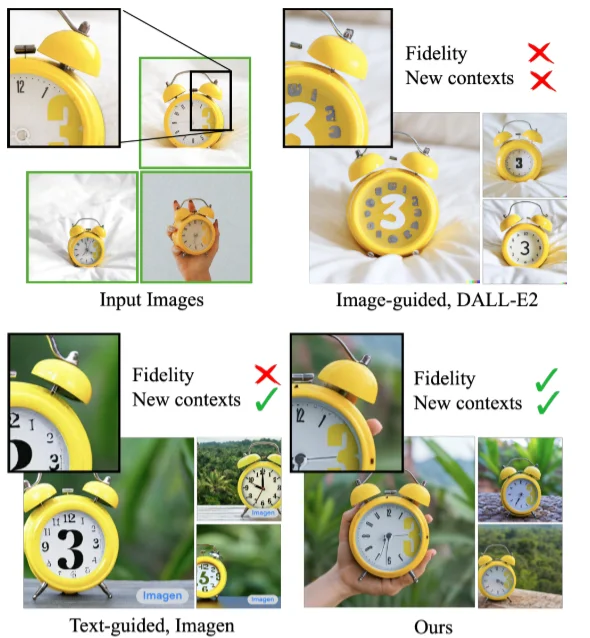
为了实现图像的“高效迁移”,作者直接将图像(比如说我们需要风格化的图片)作为一个特殊的标记,也就是论文里面提到的 a [identifier] [class noun](其中class noun为类别比如所狗,identifier就是一个特殊的标记),在prompt中加入类别,通过利用预训练模型中关于该类别物品的先验知识,并将先验知识与特殊标记符相关信息进行融合,这样就可以在不同场景下生成不同姿势的目标物体。就比如下面的 fine-tuning过程通过几张图片让模型学习到 特殊的狗,然后再推理阶段模型可以利用这个 特殊的狗去生成新的动作。
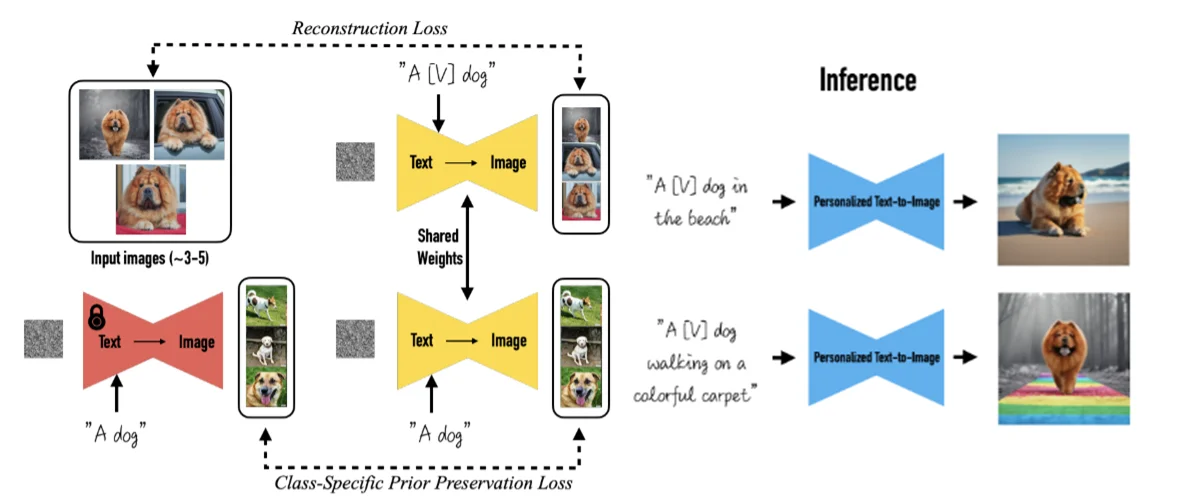
再论文里面作者设计如下的Class-specific Prior Preservation Loss(参考stackexchange)[8]:
\[\begin{aligned} & \mathbb{E}_{x,c,\epsilon,t}\left[\|\epsilon-\varepsilon_{\theta}(z_{t},t,c)\|_{2}^{2}+\lambda\|\epsilon^{\prime}-\epsilon_{pr}(z_{t^{\prime}}^{\prime},t^{\prime},c_{pr})\|_{2}^{2}\right] \end{aligned}\]上面损失函数中后面一部分就是我们的先验损失,比如说\(c+{pr}\)就是对 "a dog"进行编码然后计算生成损失。在代码中:
if args.with_prior_preservation: model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0) target, target_prior = torch.chunk(target, 2, dim=0) # Compute instance loss loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean") # Compute prior loss prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean") # Add the prior loss to the instance loss. loss = loss + args.prior_loss_weight * prior_loss else: loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean") DreamBooth代码操作
代码:https://github.com/shangxiaaabb/ProjectCode/tree/main/code/Python/DFModelCode/training_dreambooth_lora/
权重:https://www.modelscope.cn/models/bigyellowjie/SDXL-DreamBooth-LOL/files
在介绍DreamBooth代码之前,简单回顾DreamBooth原理,我希望我的模型去学习一种画风那么我就需要准备
样本图片
(如3-5)这几张图片就是专门的模型需要学习的,但是为了防止模型过拟合(模型只学习了我的图片内容,但是对一些细节丢掉了,比如说我提供的5张油画,模型就学会了我的油画画风但是为了防止模型对更加多的油画细节忘记了,那么我就准备num_epochs * num_samples 张油画类型图片然后通过计算 Class-specific Prior Preservation Loss)需要准备 类型图片
来计算Class-specific Prior Preservation Loss。代码处理(SDXL+Lora):首先是lora处理模型
:在基于transformer里面的模型很容易使用lora,比如说下面代码使用lora包裹模型并且对模型权重进行保存:from peft import LoraConfig def get_lora_config(rank, dropout, use_dora, target_modules): '''lora config''' base_config = { "r": rank, "lora_alpha": rank, "lora_dropout": dropout, "init_lora_weights": "gaussian", "target_modules": target_modules, } return LoraConfig(**base_config) # 包裹lora模型权重 unet_target_modules = ["to_k", "to_q", "to_v", "to_out.0"] unet_lora_config = get_lora_config( rank= config.rank, dropout= config.lora_dropout, use_dora= config.use_dora, target_modules= unet_target_modules, ) unet.add_adapter(unet_lora_config) 一般的话考虑SD模型权重都比较大,而且我们使用lora微调模型没必要对所有的模型权重进行存储,那么一般都会定义一个hook来告诉模型那些参数需要保存、加载比如:
def save_model_hook(models, weights, output_dir): if accelerator.is_main_process: unet_lora_layers_to_save = None for model in models: if isinstance(model, type(unwrap_model(unet))): unet_lora_layers_to_save = convert_state_dict_to_diffusers(get_peft_model_state_dict(model)) ... weights.pop() # 去掉不需要保存的参数 StableDiffusionXLPipeline.save_lora_weights( output_dir, unet_lora_layers= unet_lora_layers_to_save, ... ) def load_model_hook(models, input_dir): unet_ = None while len(models) > 0: model = models.pop() if isinstance(model, type(unwrap_model(unet))): unet_ = model lora_state_dict, network_alphas = StableDiffusionLoraLoaderMixin.lora_state_dict(input_dir) unet_state_dict = {f"{k.replace('unet.', '')}": v for k, v in lora_state_dict.items() if k.startswith("unet.")} unet_state_dict = convert_unet_state_dict_to_peft(unet_state_dict) incompatible_keys = set_peft_model_state_dict(unet_, unet_state_dict, adapter_name="default") ... accelerator.register_save_state_pre_hook(save_model_hook) accelerator.register_load_state_pre_hook(load_model_hook) 这样一来使用 accelerator.save_state(save_path) 就会先去使用 hook处理参数然后进行保存。
其次模型训练
:就是常规的模型训练(直接在样本图片:instance_data_dir以及样本的prompt:instance_prompt上进行微调)然后计算loss即可,如果涉及到Class-specific Prior Preservation Loss(除了上面两个组合还需要:class_data_dir以及 class_prompt)那么处理过程为(以SDXL为例),不过需要事先了解的是在计算这个loss之前会将两个数据集以及prompt都组合到一起成为一个数据集
(instance-image-prompt 以及 class-image-prompt之间是匹配的): # 样本内容编码 instance_prompt_hidden_states, instance_pooled_prompt_embeds = compute_text_embeddings(config.instance_prompt, text_encoders, tokenizers) # 类型图片内容编码 if config.with_prior_preservation: class_prompt_hidden_states, class_pooled_prompt_embeds = compute_text_embeddings(config.class_prompt, text_encoders, tokenizers) ... prompt_embeds = instance_prompt_hidden_states unet_add_text_embeds = instance_pooled_prompt_embeds if not config.with_prior_preservation: prompt_embeds = torch.cat([prompt_embeds, class_prompt_hidden_states], dim=0) unet_add_text_embeds = torch.cat([unet_add_text_embeds, class_pooled_prompt_embeds], dim=0) ... model_pred = unet(...) if config.with_prior_preservation: model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0) target, target_prior = torch.chunk(target, 2, dim=0) ... prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean") ... loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean") ... loss = loss + config.prior_loss_weight * prior_loss accelerator.backward(loss) 在这个里面之所以用 chunk是因为在数据集构件中:
pixel_values = [example["instance_images"] for example in examples] ... if with_prior_preservation: pixel_values += [example["class_images"] for example in examples] pixel_values = torch.stack(pixel_values) ... 那么这样一来数据中一半来自样本图片一部分来自类型图片,在模型处理之后在model_pred就有一部分是样本图片的预测,另外一部分为类型图片预测。最后测试的结果为(prompt: "A photo of Rengar the Pridestalker in a bucket",模型代码以及权重下载):

总结
对于不同的扩散(基座)模型(SD1.5、SDXL、Imagen)等大部分都是采用Unet结构,当然也有采用Dit的,这两个模型(SD1.5、SDXL)之间的差异主要在于后者会多一个clip编码器再文本语义上比前者更加有优势。对于adapter而言,可以直接理解为再SD的基础上去使用“风格插件”,这个插件不去对SD模型进行训练(从而实现对参数的减小),对于ControNet就是直接对Unet的下采样所有的模块(前后)都加一个zero-conv而后将结果再去嵌入到下采用中,而T2I-Adapter则是去对条件进行编码而后嵌入到SD模型(上采用模块)中。对于deramboth就是直接通过给定的样本图片去生“微调”模型,而后通过设计的Class-specific Prior Preservation Loss来确保所生成的样本特里不会发生过拟合。
参考
https://arxiv.org/pdf/2307.01952 ↩︎
https://arxiv.org/pdf/2205.11487 ↩︎
Scalable Diffusion Models with Transformers ↩︎
https://arxiv.org/pdf/2405.08748 ↩︎
https://arxiv.org/pdf/2302.05543 ↩︎
https://arxiv.org/pdf/2302.08453 ↩︎
https://arxiv.org/pdf/2208.12242 ↩︎
https://stats.stackexchange.com/questions/601782/how-to-rewrite-dreambooth-loss-in-terms-of-epsilon-prediction ↩︎






评论