
从零开始实现简易版Netty(五) MyNetty FastThreadLocal实现
从零开始实现简易版Netty(五) MyNetty FastThreadLocal实现
1. ThreadLocal介绍
在上一篇博客中,lab4版本的MyNetty对事件循环中的IO写事件处理进行了优化,解决了之前版本无法进行大数据消息写出的问题。
按照计划,本篇博客中,lab5版本的MyNetty需要实现FastThreadLocal。由于本文属于系列博客,读者需要对之前的博客内容有所了解才能更好地理解本文内容。
- lab1版本博客:从零开始实现简易版Netty(一) MyNetty Reactor模式
- lab2版本博客:从零开始实现简易版Netty(二) MyNetty pipeline流水线
- lab3版本博客:从零开始实现简易版Netty(三) MyNetty 高效的数据读取实现
- lab4版本博客:从零开始实现简易版Netty(四) MyNetty 高效的数据写出实现
在实现FastThreadLocal之前,我们先介绍一下java中的ThreadLocal。对ThreadLocal的工作原理和优缺点有所了解后,才能更好的去理解netty为什么要额外实现一个功能类似的FastThreadLocal。
ThreadLocal,顾名思义是用来存储线程本地变量的一个容器(叫ThreadLocalVariable更为贴切)。虽然形式上是对同一个变量进行操作,但底层每个线程都持有一个独属于本线程的变量副本,不同线程对ThreadLocal变量的增删改查操作都是彼此完全隔离的。
下面的demo程序中,t1和t2两个线程虽然对static的threadLocal变量进行了并发的set操作,但彼此之间所设置的值却并不会串,t1线程get到的永远是t1-set,t2线程get到的永远是t2-set。
public class ThreadLocalDemo { private static ThreadLocal<String> threadLocal = new ThreadLocal<>(); public static void main(String[] args) { new Thread(() -> { doSleep(); for(int i=0; i<100; i++){ //设置t1线程中本地变量的值 threadLocal.set("t1-set"); //获取t1线程中本地变量的值 System.out.println("t1线程局部变量的value : " + threadLocal.get() + " " + Thread.currentThread().getName()); }}, "t1").start(); new Thread(() -> { doSleep(); for(int i=0; i<100; i++){ //设置t2线程中本地变量的值 threadLocal.set("t2=set"); //获取t1线程中本地变量的值 System.out.println("t2线程局部变量的value : " + threadLocal.get() + " " + Thread.currentThread().getName()); }}, "t2").start(); LockSupport.park(); } private static void doSleep(){ try { Thread.sleep(1000L); } catch (InterruptedException e) { throw new RuntimeException(e); } } } 基于这个特性,ThreadLocal很适合用于存储线程级别隔离的,跨方法调用的变量。比如BIO模式下当前请求的用户上下文信息,或是数据库连接Connection来管理事务等。
2. ThreadLocal工作原理解析
ThreadLocal的使用非常简单,其仅提供了get、set和remove三个方法让用户实现增删改查功能。为了方便后续的测试,我们这里定义一个ThreadLocal的Api,便于验证不同ThreadLocal实现的差异。
public interface ThreadLocalApi<T> { void set(T value); T get(); void remove(); } 掌握ThreadLocal使用,但对ThreadLocal底层不了解的读者可能会简单的认为ThreadLocal底层是一个ConcurrentHashMap,key是当前线程,value是对应存储的ThreadLocal变量。类似下面这样的实现。
public class MySimpleThreadLocal<T> implements ThreadLocalApi<T> { private final Map<Thread,T> threadLocalMap = new ConcurrentHashMap<>(); public void set(T value){ threadLocalMap.put(Thread.currentThread(),value); } public T get(){ return threadLocalMap.get(Thread.currentThread()); } public void remove(){ threadLocalMap.remove(Thread.currentThread()); } } 基于并发安全的Map实现的方式,虽然在功能上能简单又正确的实现set、get和remove方法,但性能并不高。
因为其底层的ConcurrentHashMap本质上还是一个在多个线程中共享的数据结构,在并发更新时依然需要在一些临界点加锁来防止并发,同时某个线程写入触发扩容时,也会影响到其整体的吞吐量。
下面我们来简单分析一下,java中的ThreadLocal是如何实现的。
- ThreadLocal为了避免线程间并发的读写争抢,其本质上是线程级别隔离的。每一个Thread都维护了一个ThreadLocalMap结构,里面存放着当前线程所持有的所有ThreadLocal变量。
每个线程在访问ThreadLocal时,只会读写独属于本线程的ThreadLocalMap,不存在竞争关系。因此比起上述demo中使用共享ConcurrentMap实现的思路性能要好不少。 - ThreadLocalMap本质上是一个哈希表,但其解决hash冲突的方式是开放地址法,而不是jdk中HashMap一样的拉链法。与拉链法不同,开放地址法在当前key的hashCode与其它key产生冲突时,会尝试在哈希表中的其它空slot中找到合适的位置存放Entry(选址是开放的)。
因此,要想保证hash冲突总是能够得到解决,开放地址法的哈希表底层的数组大小一定要大于所存储的元素个数。在ThreadLocalMap的实现中,负载因子的阈值是2/3,即所存储的元素个数达到数组大小的2/3时,便会进行底层数组的扩容。
为了方便与后续Netty的FastThreadLocal实现做对比,MyNetty参考java的ThreadLocal实现了一套MyJdkThreadLocal。
MyJdkThreadLocal实现源码
public class MyJdkThread extends Thread { private MyJdkThreadLocalMap myJdkThreadLocalMap; public MyJdkThread(Runnable target) { super(target); } public MyJdkThreadLocalMap getMyJdkThreadLocalMap() { return myJdkThreadLocalMap; } public void setMyJdkThreadLocalMap(MyJdkThreadLocalMap myJdkThreadLocalMap) { this.myJdkThreadLocalMap = myJdkThreadLocalMap; } } /** * 基本参考自jdk中的ThreadLocal类 * */ public class MyJdkThreadLocal<T> implements ThreadLocalApi<T> { private final int threadLocalHashCode = generateNextHashCode(); private static final AtomicInteger nextHashCode = new AtomicInteger(); /** * 对于二次幂扩容的map,冲突率最低的魔数 * */ private static final int HASH_INCREMENT = 0x61c88647; /** * 初始化时的值,默认是null * * 可以通过子类重写方法的方式自定义initialValue的返回值 * */ protected T initialValue() { return null; } public static <S> MyJdkThreadLocal<S> withInitial(Supplier<? extends S> supplier) { return new MyJdkThreadLocal<S>(){ @Override protected S initialValue() { return supplier.get(); } }; } public int getThreadLocalHashCode() { return threadLocalHashCode; } @Override public T get() { Thread t = Thread.currentThread(); if(!(t instanceof MyJdkThread)){ // 简单起见,只支持MyJdkThread,不对其它类型的thread做兼容 throw new IllegalStateException("Not a MyJdkThread"); } MyJdkThread myJdkThread = (MyJdkThread) t; MyJdkThreadLocalMap myJdkThreadLocalMap = myJdkThread.getMyJdkThreadLocalMap(); if (myJdkThreadLocalMap != null) { // 如果ThreadLocalMap存在,直接尝试获取当前的threadLocal对应的entry MyJdkThreadLocalMap.Entry e = myJdkThreadLocalMap.getEntry(this); if (e != null) { // 当前threadLocal在对应的thread的threadLocalMap中存在,则直接返回value值 @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } // 走到这里有两种情况 // 1. myJdkThreadLocalMap == null, 当前thread没有初始化ThreadLocalMap // 2. myJdkThreadLocalMap != null && threadLocalMap.getEntry == null // 当前thread存在threadLocalMap,但是里面不存在当前threadLocal对应的entry return setInitialValue(myJdkThread); } @Override public void set(T value) { Thread t = Thread.currentThread(); if(!(t instanceof MyJdkThread)){ // 简单起见,只支持MyJdkThread,不对其它类型的thread做兼容 throw new IllegalStateException("Not a MyJdkThread"); } MyJdkThread myJdkThread = (MyJdkThread) t; MyJdkThreadLocalMap myJdkThreadLocalMap = myJdkThread.getMyJdkThreadLocalMap(); if (myJdkThreadLocalMap == null) { // set时当前thread还没有threadLocalMao,创建一个新的 myJdkThread.setMyJdkThreadLocalMap(new MyJdkThreadLocalMap()); } // 将value值set进当前线程的threadLocalMap中 myJdkThread.getMyJdkThreadLocalMap().set(this,value); } @Override public void remove() { Thread t = Thread.currentThread(); if(!(t instanceof MyJdkThread)){ // 简单起见,只支持MyJdkThread,不对其它类型的thread做兼容 throw new IllegalStateException("Not a MyJdkThread"); } MyJdkThread myJdkThread = (MyJdkThread) t; MyJdkThreadLocalMap myJdkThreadLocalMap = myJdkThread.getMyJdkThreadLocalMap(); if (myJdkThreadLocalMap != null) { myJdkThreadLocalMap.remove(this); } } private T setInitialValue(MyJdkThread myJdkThread) { T value = initialValue(); if (myJdkThread.getMyJdkThreadLocalMap() == null) { // threadLocalMap是惰性加载的,按需创建(因为不是所有的thread都需要用到threadLocal,这样可以节约内存) MyJdkThreadLocalMap myJdkThreadLocalMap = new MyJdkThreadLocalMap(); myJdkThread.setMyJdkThreadLocalMap(myJdkThreadLocalMap); } // 将将当前的threadLocal变量的初始化的值设置进去 myJdkThread.getMyJdkThreadLocalMap().set(this,value); return value; } private static int generateNextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); } } /** * 基本参考自jdk中的ThreadLocal类中的ThreadLocalMap内部类 * */ public class MyJdkThreadLocalMap { public static class Entry extends WeakReference<MyJdkThreadLocal<?>> { Object value; Entry(MyJdkThreadLocal<?> k, Object v) { super(k); value = v; } } private static final int INITIAL_CAPACITY = 16; private Entry[] table; private int size = 0; private int threshold; // Default to 0 public MyJdkThreadLocalMap() { table = new Entry[INITIAL_CAPACITY]; setThresholdByLength(INITIAL_CAPACITY); } public void set(MyJdkThreadLocal<?> key, Object value) { Entry[] tab = table; int len = tab.length; int i = key.getThreadLocalHashCode() & (len-1); // 先找到目标ThreadLocal的hashCode对应的slot插槽 // 1 如果对应插槽为null,直接不执行for循环逻辑 for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { // 2 如果对应插槽不为null MyJdkThreadLocal<?> k = e.get(); if (k == key) { // 如果对应slot上就是目标threadLocal,直接将value进行覆盖后直接返回 e.value = value; return; } if (k == null) { // Entry不为null,但是key弱引用已经因为gc而为null了,将这个Entry给当前的key/value用 replaceStaleEntry(key, value, i); return; } } // 找到了一个为空的slot,构建一个新的Entry放入该slot tab[i] = new Entry(key, value); // map的size自增1 int sz = ++size; // 尝试清理一些slot if (!cleanSomeSlots(i, sz) && sz >= threshold) { // cleanSomeSlots返回false,说明没有找到可以清除的插槽。同时size已经达到了规定的阈值,map需要进行rehash扩容 rehash(); } } public Entry getEntry(MyJdkThreadLocal<?> key) { // 基于threadLocal的hashCode值,获得其slot下标 int i = key.getThreadLocalHashCode() & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) { // 对应slot正好就是key对应的entry,直接返回 return e; } else { // entry为空,或者对应的entry的key不匹配 // 使用基于线性探测的开放寻址法,解决hashKey的冲突,尝试在当前slot后面的slot中去寻找key对应的entry return getEntryAfterMiss(key, i, e); } } public void remove(MyJdkThreadLocal<?> key){ Entry[] tab = table; int len = tab.length; int i = key.getThreadLocalHashCode() & (len-1); // 遍历table,直到找到为null的插槽才退出 for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { if (e.get() == key) { // 找到了key对应的entry,将key清理掉,然后再通过expungeStaleEntry将value和entry一并清除 e.clear(); expungeStaleEntry(i); return; } } // 从hashCode对应的slot开始遍历,并没有找到key对应的entry,说明对应的key不存在 } private Entry getEntryAfterMiss(MyJdkThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length; while (e != null) { MyJdkThreadLocal<?> k = e.get(); if (k == key) { return e; } if (k == null) { // 弱引用会导致一些entry对应的key过期,在发现entry不为null,但对应的key为null时,启发性的将过期的entry从当前map中清除出去 expungeStaleEntry(i); } else { // Entry中的key不为null,继续向后遍历 i = nextIndex(i, len); } e = tab[i]; } // 从i开始,直到一个为null的slot,都没有找到匹配的key,返回null return null; } /** * 从头开始遍历整个table,将key为null的Entry清理掉 * */ private void expungeStaleEntries() { Entry[] tab = table; int len = tab.length; for (int j = 0; j < len; j++) { Entry e = tab[j]; if (e != null && e.get() == null) { expungeStaleEntry(j); } } } private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; // expunge entry at staleSlot // 只有当发现当前slot为null时,才会调用该方法。 // 首先将对应entry和entry对应的value都设置为null,便于gc tab[staleSlot].value = null; tab[staleSlot] = null; // map的size自减1 size--; // Rehash until we encounter null Entry e; int i; // 从当前插槽staleSlot开始向后遍历,直到发现一个为null的插槽才停止 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { MyJdkThreadLocal<?> k = e.get(); if (k == null) { // 如果发现对应entry的key为null了,说明对应的threadLocal被回收了。和上面一样,把value和entry一并清空;同时size自减1 e.value = null; tab[i] = null; size--; } else { // 获得当前key的hashCode对数组长度求余后的slot值 int h = k.getThreadLocalHashCode() & (len - 1); if (h != i) { // 如果不是最佳匹配,说明之前set时是顺延过了的,需要将该entry移动到距离最佳匹配slot(h)最近的位置中 // 首先将slot i清除掉 tab[i] = null; // Unlike Knuth 6.4 Algorithm R, we must scan until // null because multiple entries could have been stale. // 然后从slot h开始向后遍历,直到找到一个null的slot,将当前entry放进去(最佳匹配slot(h)最近的位置) while (tab[h] != null) { h = nextIndex(h, len); } tab[h] = e; } } } // 返回为遍历到最后,为null的插槽的标识 return i; } /** * 在set时,发现一个slot为null时被调用 * 1 虽然staleSlot为null,但是有可能key对应的entry在后面的slot中,所以不能直接放在staleSlot上 * 所以要从staleSlot开始向后遍历,最晚直到一个为null的slot才停止 * 2 如果在遍历的过程中找到了key对应的slot,那么就替换掉value,提前退出扫描 * 如果在遍历的过程中没有找到key对应的slot,那么就把新的key放到一开始staleSlot对应的slot上 * 3 会尝试着在staleSlot的前面和后面查找key为null的slot时,进行一波清理 * */ private void replaceStaleEntry(MyJdkThreadLocal<?> key, Object value, final int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e; // Back up to check for prior stale entry in current run. // We clean out whole runs at a time to avoid continual // incremental rehashing due to garbage collector freeing // up refs in bunches (i.e., whenever the collector runs). // 从当前slot向前遍历,将entry不为null,但key为null的entry都回收掉 // 使用另一种回收的策略(因为大多数策略是从前往后遍历的,这里是从后往前),来减少key被批量gc时造成持续不断地rehash int slotToExpunge = staleSlot; for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) { if (e.get() == null) { slotToExpunge = i; } } // Find either the key or trailing null slot of run, whichever occurs first // 从staleSlot开始遍历,直到找到一个空的slot退出循环 for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { MyJdkThreadLocal<?> k = e.get(); // If we find key, then we need to swap it // with the stale entry to maintain hash table order. // The newly stale slot, or any other stale slot // encountered above it, can then be sent to expungeStaleEntry // to remove or rehash all of the other entries in run. // 注意,此方法只在set时被调用 if (k == key) { // 当找到了与set指定的key匹配的,先把value替换下 e.value = value; // staleSlot对应的slot中key是为null的, // 交换下,把这个staleSlot下标对应的slot让给当前的key用 tab[i] = tab[staleSlot]; tab[staleSlot] = e; // Start expunge at preceding stale entry if it exists if (slotToExpunge == staleSlot) { // staleSlot之前的entry不为null,从i开始尝试清理一遍过期的entry(前面向前遍历时slotToExpunge没有变化) slotToExpunge = i; }else{ // 否则,cleanSomeSlots时将staleSlot前面那部分key为null的过期Entry清理掉 } // 进行一波清理 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // If we didn't find stale entry on backward scan, the // first stale entry seen while scanning for key is the // first still present in the run. // 如果在向后扫描时没有找到过期的entry // 那么在扫描时遇到的第一个过期entry就是在该运行中仍然存在的第一个过期entry if (k == null && slotToExpunge == staleSlot) { slotToExpunge = i; } } // If key not found, put new entry in stale slot // 扫描的过程中没有找到key对应的Entry,就将原来的那个key为null的Entry的value置为null // 同时将空的这个slot放上新的Entry(set方法时调用) tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value); // If there are any other stale entries in run, expunge them // 走到这里说明在遍历的过程中没有找到key匹配的entry,没有提前返回 // slotToExpunge不等于staleSlot // 第1种可能:在一开始向前查找的过程中,发现了key为null的slot,从对应前置位点开始清理一波过期的slot // 第2种可能:在向后遍历的过程中,找到了为null的slot,退出了循环,那么就从这里开始检查,尝试清理一波过期slot if (slotToExpunge != staleSlot) { cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); } } /** * 以i开始遍历之后的插槽,以至少log2(n)的次数进行检查,线性扫描并删除过期的Entry * * @return 是否删除了至少一个过期的Entry * */ private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { // 找到i的下一个entry i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { // 发现了一个过期的Entry,令n=len,相当于重置了需要扫描的次数 // 因为过期的entry,说明内存泄露的情况可能比较严重,加大扫描的次数,增加清理的力度 n = len; removed = true; // 清理一波过期的entry i = expungeStaleEntry(i); } // 通过左移1位的方式,控制尝试清理的次数至少为log2(n), // 如果清理过程中发现了过期的entry,会执行更多次 } while ( (n >>>= 1) != 0); return removed; } /** * 准备以2次幂对hash表进行扩容 * */ private void rehash() { // 准备扩容前先把所有的过期entry清理掉 expungeStaleEntries(); // Use lower threshold for doubling to avoid hysteresis // 如果清理掉了过期entry后,元素个数还是高于阈值 if (size >= threshold - threshold / 4) { // 2次幂对hash表进行扩容 resize(); } } /** * 以2次幂对hash表进行扩容 */ private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; // 新的entry数组为之前的两倍大 Entry[] newTab = new Entry[newLen]; int count = 0; for (Entry e : oldTab) { if (e != null) { MyJdkThreadLocal<?> k = e.get(); if (k == null) { // 最后再确认一遍key是否为null(因为在这个过程中可能gc过) // 为null的就不再放入新的table中了 e.value = null; // Help the GC } else { int h = k.getThreadLocalHashCode() & (newLen - 1); while (newTab[h] != null) { // 开放定址法放入entry h = nextIndex(h, newLen); } newTab[h] = e; count++; } } } // 扩容完毕,设置阈值和size setThresholdByLength(newLen); size = count; table = newTab; } private static int prevIndex(int i, int len) { // 做下回环,避免下标越界 return ((i - 1 >= 0) ? i - 1 : len - 1); } private static int nextIndex(int i, int len) { // 做下回环,避免下标越界 return ((i + 1 < len) ? i + 1 : 0); } private void setThresholdByLength(int len) { // Set the resize threshold to maintain at worst a 2/3 load factor. // 元素数量超过了map数组长度的2/3时触发map的扩容(resize) // 注意:threshold和len的比例一定要小于1,因为是开放定位法,否则会导致数组装满而放不下新元素 threshold = len * 2 / 3; } } threadLocal示意图
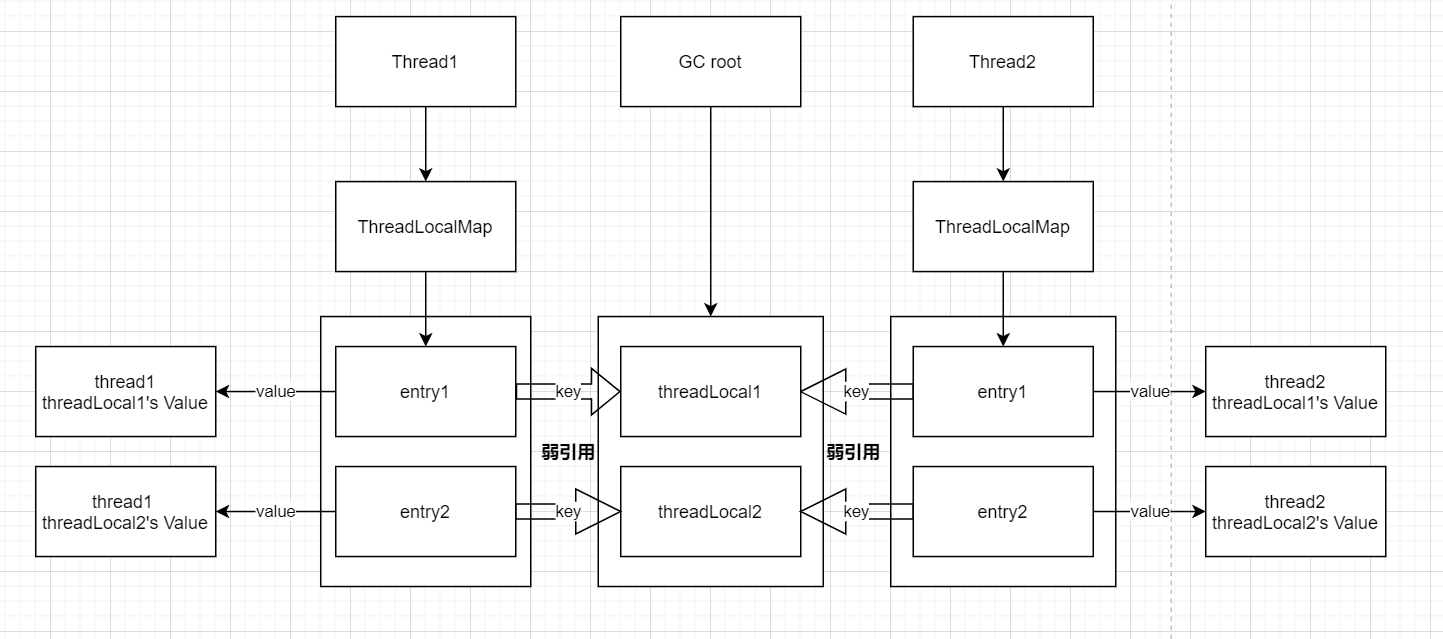
结合MyJdkThreadLocal的源码和threadLocal示意图,有几个关键点需要注意。
- 对于相同的ThreadLocal对象,其作为key在不同的Thread专属的ThreadLocalMap中指向的并不是同一个value。通过这个设计ThreadLocal做到了线程本地变量的线程间隔离。
- ThreadLocal可以通过withInitial方法或自定义子类对象的方式设置默认值,在未提前set时,get操作会返回默认值,并将ThreadLocal设置为默认值。
- ThreadLocalMap中底层数组中存储的Entry节点对象有两个关键的成员变量,一个是作为key的ThreadLocal类型的对象,在构造方法中被设置为弱引用(WeakReference);另一个则是作为value的ThreadLocal实际维护的变量值,是普通的强引用。
- 在set、get发现为null的slot时或者remove成功清理掉对应Entry时,ThreadLocalMap会启发式的对周围的slot进行检查,将Entry中key为null的Entry对象从底层数组table中移除。(这么做的具体原因在下文分析)
为什么Entry中要将对ThreadLocal变量的引用设置为弱引用(weakReference)?
假设一个场景,用户在方法中定义并使用了一个ThreadLocal的临时变量,方法中set了一个值后没有remove就返回了。方法返回后,ThreadLocal对象的直接引用无法再被访问,此时该ThreadLocal设置的value值便会留在当前线程的ThreadLocalMap中无法被主动删除。
当然,jdk的作者可以要求用户在完成对ThreadLocal的使用后必须正确的通过remove方法将其释放,否则用户自行承担内存泄露的风险(特别是在线程池等线程长期存活的场景下)。
但正如java作为一个拥有自动垃圾回收特性的语言一样,jdk的作者希望ThreadLocal变量能够和普通的临时变量一样,在函数返回时,临时变量引用的对象能够自动的被系统回收掉,而无需用户必须紧绷着神经小心翼翼的进行手动释放。
弱引用简单介绍
java中共设计了四种引用类型,按照引用强度的从高到低分别为强引用、软引用、弱引用和虚引用。
| 引用类型 | 详情 |
|---|---|
| 强引用 StrongReference | 任一强引用存在时,对象不会被gc回收。正常编码时的对象引用都是强引用 |
| 软引用 SoftReference | 仅存在软引用以及强度更弱的引用时,当内存不足时便会对象便会被gc回收 |
| 弱引用 WeakReference | 仅存在弱引用以及强度更多的应用时,当gc时对象便会被回收掉 |
| 虚引用 PhantomReference | 仅存在虚引用时,等价于没有引用 |
弱引用使用demo
public class User { /** * 为了与WeakReference对称,本质上就是 private UserPackage h3Ref; * */ private StrongReference<UserPackage> h3Ref; private WeakReference<UserPackage> weakRef; public StrongReference<UserPackage> getStrongRef() { return h3Ref; } public void setStrongRef(StrongReference<UserPackage> h3Ref) { this.h3Ref = h3Ref; } public WeakReference<UserPackage> getWeakRef() { return weakRef; } public void setWeakRef(WeakReference<UserPackage> weakRef) { this.weakRef = weakRef; } } public class UserPackage { private String packageName; public String getPackageName() { return packageName; } public void setPackageName(String packageName) { this.packageName = packageName; } } public class StrongReference<T> { private final T referent; public StrongReference(T referent) { this.referent = referent; } public T get() { return referent; } } public class WeakReferenceDemo { public static void main(String[] args) throws InterruptedException { UserPackage userPackage = new UserPackage("user-package"); User user = new User(); user.setStrongRef(new StrongReference<>(userPackage)); user.setWeakRef(new WeakReference<>(userPackage)); // 斩断root与userPackage的关联 userPackage = null; System.gc(); System.out.println("h3Ref=" + user.getStrongRef().get()); // 存在 System.out.println("weakRef=" + user.getWeakRef().get()); // 存在 System.gc(); System.out.println("h3Ref=" + user.getStrongRef().get()); // 存在 System.out.println("weakRef=" + user.getWeakRef().get()); // 存在 // 斩断h3Ref与userPackage的关联 user.setStrongRef(null); System.out.println("h3Ref=" + user.getStrongRef()); // null System.out.println("weakRef=" + user.getWeakRef().get()); // 存在 System.gc(); // gc后,因为userPackage对象的强引用全都不存在了,所以userPackage被回收掉(即使weakRef还存在) System.out.println("h3Ref=" + user.getStrongRef()); // null System.out.println("weakRef=" + user.getWeakRef().get()); // null } } - 从上面的弱引用介绍中可以看出,当对象只存在弱引用时,gc时便会将其自动的回收掉。基于弱引用,ThreadLocal便能实现启发式的自动删除未被正确remove掉的ThreadLocal变量。
- 结合上面的ThreadLocal示意图可以看到,正常情况下,一个ThreadLocal变量存在直接的强引用和来自ThreadLocalMap中Entry节点的弱引用。当用户不再使用对应的ThreadLocal对象,并且没有正确的remove时,threadLocal变量便只剩下一个弱引用了。
当gc后,Entry所指向的ThreadLocal变量便会被成功的回收掉,对应Entry的get方法会返回null值。基于此,便能感知到该ThreadLocal虽然没有被用户remove掉,但实际上不会再被使用,可以将其value移除或者将该slot给其它ThreadLocal变量使用。 通过Entry中对ThreadLocal的弱引用设计和启发式的检查机制,ThreadLocal比较巧妙的解决(大幅缓解)了用户在没有正确remove回收ThreadLocal变量时的内存泄露问题。
有了启发式的清除机制能完全避免内存泄露吗?
再深入的思考下,弱引用加启发式的清理机制能完全的避免内存泄露吗?答案是否定的。
从ThreadLocalMap的源码中可以看出,出于执行效率的考虑(保证get、set和remove方法O(1)的时间复杂度),启发式的检查仅仅会确认相邻的少部分slot,并不能保证能完全的清理掉全部的key为null的Entry。
在绝大多数场景中,ThreadLocal即使没有全部正确的remove掉,也不会有特别严重的问题。但在极端场景下,线程长时间存活且线程数较多,而ThreadLocal所维护对象又较大时,未被完全清理的ThreadLocal变量依然会由于未被及时回收而浪费大量内存。
因此,作为使用者,还是推荐在使用ThreadLocal时尽可能的编写完备的逻辑,在确定不再使用时将ThreadLocal对象尽早remove释放掉,而不要过分依赖jdk提供的自动回收功能。
为什么ThreadLocalMap采用开发地址法而不是拉链法解决哈希冲突?
个人认为,主要原因有二:
- 开发地址法相比拉链法因为不需要维护链表节点,因此更加节约空间。但在哈希表很大时,hash冲突时寻找可用slot的cpu开销较大。
但相比普通HashMap的使用场景,ThreadLocalMap中会维护的Entry数量不会特别多,所以带来的额外的哈希冲突时的开销不是什么大问题。 - 比起依赖链表的拉链法,基于弱引用进行Entry自动回收的机制能更简单、高效的实现。
2. FastThreadLocal实现原理介绍
在第一节中,详细的分析了jdk的ThreadLocal的工作原理,似乎ThreadLocal已经足够高效和可靠了。那么netty为什么还要再造一个功能类似的FastThreadLocal呢?特别是还冠以了Fast的名字,FastThreadLocal究竟比ThreadLocal快在哪?
FastThreadLocal比ThreadLocal快在哪?
- ThreadLocal中key是基于ThreadLocal对象的hash码得出的,hash码本质上是随机的,因此不同ThreadLocal对象其对应的slot插槽必然有概率相同而可能产生hash冲突。
而Netty中的FastThreadLocal的key并不是基于hash码,而是一个并发安全且全局单调递增的整数。每一个ThreadLocal对象被创建时都会基于这个自增整数(nextIndex)获得一个全局唯一的整数值(index),并作为在FastThreadLocalMap中底层数组的下标索引值。
因此FastThreadLocal不会出现hash冲突的问题,比起jdk的ThreadLocal大幅减少了冲突时遍历寻找空闲插槽的额外开销。
- 上文提到,jdk的作者在设计ThreadLocal时,考虑到用户无法总是正确的remove回收掉ThreadLocal,因此实现了一套启发式的自动清理无效Entry的机制。
而Netty中,创造FastThreadLocal的核心目的是提升netty自身使用ThreadLocal的场景时的效率。netty的作者能保证FastThreadLocal一定能在不使用时被remove掉,不存在内存泄露的风险,不需要额外的自动清理机制来兜底。
相比ThreadLocal,减少了启发式检查自动回收机制的FastThreadLocal毫无疑问在get、set和remove时性能有较大提升。
MyFastThreadLocal实现源码(完全参考netty,但做了一定的简化)
public class MyFastThreadLocal<V> implements ThreadLocalApi<V> { private static final int variablesToRemoveIndex = 0; /** * threadLocal对象在线程对应的ThreadLocalMap的下标(构造函数中,对象初始化的时候就确定了) * */ private final int index; public MyFastThreadLocal() { // 原子性自增,确保每一个FastThreadLocal对象都有独一无二的下标 index = MyFastThreadLocalMap.nextVariableIndex(); } /** * 删除与当前线程绑定的所有ThreadLocal对象 * */ @SuppressWarnings("unchecked") public static void removeAll() { // 获得与当前Thread绑定的ThreadLocalMap MyFastThreadLocalMap threadLocalMap = MyFastThreadLocalMap.getIfSet(); if (threadLocalMap == null) { // 没有初始化过,无事发生 return; } try { Object v = threadLocalMap.indexedVariable(variablesToRemoveIndex); if (v != null && v != MyFastThreadLocalMap.UNSET) { // ThreadLocalMap数组中下标为0的地方,固定放线程所属的全体FastThreadLocal集合 Set<MyFastThreadLocal<?>> variablesToRemove = (Set<MyFastThreadLocal<?>>) v; MyFastThreadLocal<?>[] variablesToRemoveArray = variablesToRemove.toArray(new MyFastThreadLocal[0]); for (MyFastThreadLocal<?> tlv: variablesToRemoveArray) { tlv.remove(threadLocalMap); } } } finally { MyFastThreadLocalMap.remove(); } } @Override public void remove() { MyFastThreadLocalMap myFastThreadLocalMap = MyFastThreadLocalMap.getIfSet(); remove(myFastThreadLocalMap); } @SuppressWarnings("unchecked") private void remove(MyFastThreadLocalMap threadLocalMap) { if (threadLocalMap == null) { return; } // 从ThreadLocalMap中删除 Object v = threadLocalMap.removeIndexedVariable(index); removeFromVariablesToRemove(threadLocalMap, this); if (v != MyFastThreadLocalMap.UNSET) { try { // threadLocal被删除时,供业务在子类中自定义的回调函数 onRemoval((V) v); } catch (Exception e) { throw new RuntimeException(e); } } } @SuppressWarnings("unchecked") @Override public final V get() { // 获得当前线程所对应的threadLocalMap MyFastThreadLocalMap threadLocalMap = MyFastThreadLocalMap.get(); // 基于index,以O(1)的效率精确的获得对应的threadLocalMap中的元素 Object v = threadLocalMap.indexedVariable(index); if (v != MyFastThreadLocalMap.UNSET) { // 不为null,返回 return (V) v; } // 为null,返回初始化的值 return initialize(threadLocalMap); } @Override public final void set(V value) { if (value != MyFastThreadLocalMap.UNSET) { // 正常set值 MyFastThreadLocalMap threadLocalMap = MyFastThreadLocalMap.get(); if (threadLocalMap.setIndexedVariable(index, value)) { // 如果之前的值是UNSET,把这个新的threadLocal加入到总的待删除集合中去 addToVariablesToRemove(threadLocalMap, this); } } else { // 传的是UNSET逻辑上等于remove remove(MyFastThreadLocalMap.getIfSet()); } } private V initialize(MyFastThreadLocalMap threadLocalMap) { // 获得默认初始化的值(与jdk的ThreadLocal一样,可以通过子类来重写initialValue) V v = initialValue(); threadLocalMap.setIndexedVariable(index, v); addToVariablesToRemove(threadLocalMap, this); return v; } protected V initialValue(){ return null; } @SuppressWarnings("unchecked") private static void removeFromVariablesToRemove(MyFastThreadLocalMap threadLocalMap, MyFastThreadLocal<?> variable) { Object v = threadLocalMap.indexedVariable(variablesToRemoveIndex); if (v == MyFastThreadLocalMap.UNSET || v == null) { return; } // 从FastThreadLocalMap数组起始处的Set中也移除掉FastThreadLocal变量 Set<MyFastThreadLocal<?>> variablesToRemove = (Set<MyFastThreadLocal<?>>) v; variablesToRemove.remove(variable); } @SuppressWarnings("unchecked") private static void addToVariablesToRemove(MyFastThreadLocalMap threadLocalMap, MyFastThreadLocal<?> variable) { // 获得threadLocal对象集合 Object v = threadLocalMap.indexedVariable(variablesToRemoveIndex); Set<MyFastThreadLocal<?>> variablesToRemove; if (v == MyFastThreadLocalMap.UNSET || v == null) { // 为null还未初始化,创建一个集合然后放到variablesToRemoveIndex位置上 variablesToRemove = Collections.newSetFromMap(new IdentityHashMap<>()); threadLocalMap.setIndexedVariable(variablesToRemoveIndex, variablesToRemove); } else { variablesToRemove = (Set<MyFastThreadLocal<?>>) v; } // 将threadLocal变量加入到集合汇总 variablesToRemove.add(variable); } /** * threadLocal被删除时,供业务自定义的回调函数 * */ protected void onRemoval(@SuppressWarnings("UnusedParameters") V value) throws Exception { } } /** * 类似netty的InternalThreadLocalMap * */ public class MyFastThreadLocalMap { /** * 从1开始,0是特殊的位置 * */ private static final AtomicInteger nextIndex = new AtomicInteger(1); private static final int INDEXED_VARIABLE_TABLE_INITIAL_SIZE = 32; private Object[] indexedVariables; private static final ThreadLocal<MyFastThreadLocalMap> slowThreadLocalMap = new ThreadLocal<>(); private static final int ARRAY_LIST_CAPACITY_EXPAND_THRESHOLD = 1 << 30; /** * 等价于null的一个全局对象 * */ public static final Object UNSET = new Object(); // Reference: https://hg.openjdk.java.net/jdk8/jdk8/jdk/file/tip/src/share/classes/java/util/ArrayList.java#l229 private static final int ARRAY_LIST_CAPACITY_MAX_SIZE = Integer.MAX_VALUE - 8; public MyFastThreadLocalMap() { // 初始化内部数组 this.indexedVariables = newIndexedVariableTable(); } private static Object[] newIndexedVariableTable() { Object[] array = new Object[INDEXED_VARIABLE_TABLE_INITIAL_SIZE]; Arrays.fill(array, UNSET); return array; } public static int nextVariableIndex() { int index = nextIndex.getAndIncrement(); if (index >= ARRAY_LIST_CAPACITY_MAX_SIZE || index < 0) { nextIndex.set(ARRAY_LIST_CAPACITY_MAX_SIZE); throw new IllegalStateException("too many thread-local indexed variables"); } return index; } public static MyFastThreadLocalMap getIfSet() { Thread thread = Thread.currentThread(); if (thread instanceof MyFastThreadLocalThread) { return ((MyFastThreadLocalThread) thread).getMyFastThreadLocalMap(); }else{ return slowThreadLocalMap.get(); } } public static void remove() { Thread thread = Thread.currentThread(); if (thread instanceof MyFastThreadLocalThread) { // 清理掉thread的这个map设置为null ((MyFastThreadLocalThread) thread).setMyFastThreadLocalMap(null); } else { slowThreadLocalMap.remove(); } } public static MyFastThreadLocalMap get() { Thread thread = Thread.currentThread(); if (thread instanceof MyFastThreadLocalThread) { // 如果当前线程是FastThreadLocalThread,直接获取对应的MyFastThreadLocalMap MyFastThreadLocalThread myFastThreadLocalThread = (MyFastThreadLocalThread) thread; MyFastThreadLocalMap threadLocalMap = myFastThreadLocalThread.getMyFastThreadLocalMap(); if (threadLocalMap == null) { // 没有就初始化一个空的,然后与当前线程绑定一下 myFastThreadLocalThread.setMyFastThreadLocalMap(threadLocalMap = new MyFastThreadLocalMap()); } return threadLocalMap; } else { // 如果当前线程不是FastThreadLocalThread,降级从slowThreadLocalMap中获取 MyFastThreadLocalMap ret = slowThreadLocalMap.get(); if (ret == null) { // 没有就初始化一个空的,然后与当前线程绑定一下 ret = new MyFastThreadLocalMap(); slowThreadLocalMap.set(ret); } return ret; } } public Object indexedVariable(int index) { Object[] lookup = indexedVariables; // 判断有没有越界,越界了返回UNSET return index < lookup.length? lookup[index] : UNSET; } /** * 将value放到index对应的位置上去 * */ public boolean setIndexedVariable(int index, Object value) { Object[] lookup = indexedVariables; if (index < lookup.length) { // 简单的将value放入index处 Object oldValue = lookup[index]; lookup[index] = value; return oldValue == UNSET; } else { // 发现index超过了当前数组的大小,进行扩容。然后将value放入index处 expandIndexedVariableTableAndSet(index, value); return true; } } /** * 数组扩容,并且将value放入index下标处 * */ private void expandIndexedVariableTableAndSet(int index, Object value) { Object[] oldArray = indexedVariables; final int oldCapacity = oldArray.length; int newCapacity; if (index < ARRAY_LIST_CAPACITY_EXPAND_THRESHOLD) { // 类似jdk HashMap的扩容方法(tableSizeFor) // 以index为基础进行扩容,将newCapacity设置为比恰好index大的,为2次幂的数(如果index已经是2次幂的数,则newCapacity会扩容两倍) newCapacity = index; newCapacity |= newCapacity >>> 1; newCapacity |= newCapacity >>> 2; newCapacity |= newCapacity >>> 4; newCapacity |= newCapacity >>> 8; newCapacity |= newCapacity >>> 16; newCapacity ++; } else { newCapacity = ARRAY_LIST_CAPACITY_MAX_SIZE; } // 类似jdk的ArrayList,将内部数组扩容(老数组的数据copy到新数组里) Object[] newArray = Arrays.copyOf(oldArray, newCapacity); Arrays.fill(newArray, oldCapacity, newArray.length, UNSET); newArray[index] = value; // 内部数组指向扩容后的新数组 indexedVariables = newArray; } public Object removeIndexedVariable(int index) { Object[] lookup = indexedVariables; if (index < lookup.length) { // 将对应下标标识为UNSET就算删除了 Object v = lookup[index]; lookup[index] = UNSET; return v; } else { return UNSET; } } } public class MyFastThreadLocalRunnable implements Runnable { private final Runnable runnable; private MyFastThreadLocalRunnable(Runnable runnable) { this.runnable = runnable; } public void run() { try { this.runnable.run(); } finally { MyFastThreadLocal.removeAll(); } } static Runnable wrap(Runnable runnable) { if(runnable instanceof MyFastThreadLocalRunnable) { // 如果已经是MyFastThreadLocalRunnable包装类,直接返回原始对象 return runnable; }else{ // 否则返回包装后的MyFastThreadLocalRunnable return new MyFastThreadLocalRunnable(runnable); } } } public class MyFastThreadLocalThread extends Thread{ /** * 和jdk一样,thread对应的ThreadLocalMap也是惰性初始化的,目的是节约内存 * */ private MyFastThreadLocalMap myFastThreadLocalMap; public MyFastThreadLocalThread(Runnable target) { super(MyFastThreadLocalRunnable.wrap(target)); } public MyFastThreadLocalMap getMyFastThreadLocalMap() { return myFastThreadLocalMap; } public void setMyFastThreadLocalMap(MyFastThreadLocalMap myFastThreadLocalMap) { this.myFastThreadLocalMap = myFastThreadLocalMap; } } public class MyDefaultThreadFactory implements ThreadFactory { @Override public Thread newThread(Runnable r) { return new MyFastThreadLocalThread(r); } } - 前面我们提到,netty也是通过Thread中包含的ThreadLocalMap来维护FastThreadLocal变量集合的。Netty做为一个三方的库,不可能去直接修改拓展jdk中Thread的实现,只能通过子类Thread的方式,在子类Thread(FastThreadLocalThread)维护FastThreadLocal自己的ThreadLocalMap。这就导致了一个问题,如果非自定义的FastThreadLocalThread线程也使用FastThreadLocal的话,将会无法访问到对应的ThreadLocalMap。在第一节的MyJdkThreadLocal中,我们简单起见直接不允许非自定义的MyJdkThread的线程使用,否则直接抛异常。
Netty作为一个使用广泛的框架,不可能如此粗暴,而是通过为每一个FastThreadLocal变量都内置了一个jdk的ThreadLocal(slowThreadLocalMap)的方式做了降级兼容处理。Netty也通过提供自定义的ThreadFactory(DefaultThreadFactory)和MyFastThreadLocalRunnable来进行包装,方便想要使用FastThreadLocal的用户不用降级兼容,享受到FastThreadLocal的高性能。 - 每个FastThreadLocalThread都对应一个FastThreadLocalMap(InternalThreadLocalMap),每个FastThreadLocal变量在初始化时都拥有一个独一无二index下标号,访问时通过该独特的下标号获得保存在FastThreadLocalMap中对应的变量值(indexedVariable)。
扩容时,与jdk的ThreadLocal不同,FastThreadLocal在空间不足时不是直接以2次幂扩容,而是基于index做渐进的保守扩容来节约空间(expandIndexedVariableTableAndSet方法)。 - FastThreadLocalMap的第0个位置,是一个特殊的位置,里面存放的Set集合维护了当前线程所有使用到的ThreadLocal变量。这个Set集合在当前线程退出时,能够帮助Netty快速的将当前线程所有未被remove掉的ThreadLocal变量以及其value清除掉(O(1)复杂度)。
有心的读者这里肯定会有疑问,为什么要单独维护一个Set集合,线程退出RemoveAll时直接遍历整个底层数组,将不为Null(不为UNSET)的处理一遍不就行了吗,一个线程持有的FastThreadLocal数量应该不多,处理起来很快才对吧?这个问题,我们留到下文解答。
FastThreadLocal这么强大,那有没有缺点呢?
通过前面的介绍以及源码讲解,部分读者似乎会认为Netty中FastThreadLocal基于自增唯一整数做索引的机制比起会导致hash冲突的jdk ThreadLocal更加高级,甚至会质疑为什么jdk不参考netty修改它的ThreadLocal实现机制。
- 从FastThreadLocal的设计中可以发现有两个似乎较为费解的机制,一是单独在第0个位置维护了一个本线程正在使用的所有ThreadLocal集合用于线程退出时快速定位,二是扩容时底层数组的容量被设置的较为保守(不是像普通的哈希表一样直接2次幂扩容)。
而这一切其实指向了一个根本的原因,即FastThreadLocal的作者能够预判到FastThreadLocal的底层数组可能会非常大。
非常大的底层数组场景下,通过预先维护的Set集合可以在O(1)而不是O(n)的时间复杂度下回收ThreadLocal,同时保守的扩容方式能很好的节约空间。 - 举个较为极端的例子,假设线程a在自己的业务逻辑中创建了10w个FastThreadLocal对象,此时FastThreadLocal中全局唯一的整数索引值变成了10W。
此时,另一个线程b也创建了一个FastThreadLocal对象,那么线程b其独有的FastThreadLocalMap的容量是多少呢?答案是有点反直觉的10w+,而不是默认的初始化值32。
可以看到,当FastThreadLocal在不同线程中没有很好的被共享使用,而是每个线程自己用自己的ThreadLocal对象,那么FastThreadLocalMap的底层数组可能会变得非常大,非常的浪费空间,在线程数较多时这一问题尤为严重。因为其它的线程虽然没有用到别的线程其独自使用的FastThreadLocal,但还必须在底层数组中为其维护对应索引下标的slot。而jdk的ThreadLocal就不会有这个问题,因为每个ThreadLocalMap的容量只取决于当前线程实际维护的ThreadLocal变量数。 所以从本质上来说,FastThreadLocal的设计是一种空间换时间的策略,当FastThreadLocal在不同线程间共享率较低时,空间效率会非常低。
在Netty自身的使用中,FastThreadLocal数量很少,线程间的FastThreadLocal共享率非常高,所以空间浪费率极低,但由于没有hash冲突所以性能却好很多。而Netty自身之外使用FastThreadLocal的用户,Netty作者也乐观的假设其对底层有一定的理解,不会滥用FastThreadLocal而浪费大量空间。
而jdk的ThreadLocal使用上则可能鱼龙混杂,不同业务方使用的ThreadLocal各不相同,不同业务方的线程都维护自己独有的ThreadLocal。如果使用Netty的这种实现方案,由于线程间ThreadLocal共享率很低,其带来的性能提升完全不足以弥补空间上的浪费。这也是jdk不采用唯一索引下标解决hash冲突的根本原因。
总结
- 在本篇博客中,我们介绍了jdk的ThreadLocal工作原理,并以此为对照分析了Netty中FastThreadLocal的工作原理。两者在设计上有很多相似之处,但在很多核心机制中又有很大不同而带来了各自的优缺点。
我们会发现,两者采用的不同机制并不绝对的高下之分,jdk和Netty在实现线程本地变量的功能上,都采取了更适合自身所要面对业务场景的方案。
博客中展示的完整代码在我的github上:https://github.com/1399852153/MyNetty (release/lab5_fast_thread_local 分支),内容如有错误,还请多多指教。








评论