



一、前言
在大模型和RAG(检索增强生成)技术飞速发展的今天,
企业AI知识库
建设已成为AI落地的核心战场。而文件解析是所有参与做企业AI知识库开发者所避免不了的难题。本文将结合我在开发TorchV AIS
企业级AI知识库
产品中碰到的解析Word的问题,将Word文档(.doc及.docx)高效、准确地转换为Web友好格式(Markdown/HTML)优化目标的方案进行分享。结合目前的实际解决方案(依靠Apache Tika/POI),详细阐述一种创新的、具备行业领先水平的解决方案。通过实现一套完全基于表格结构、无需硬编码的通用算法
,完美解决了.doc和.docx格式中的复杂表格解析问题,确保转换后的HTML与源文件在视觉和结构上高度一致。 二、Word文档解析:企业AI知识库的隐形瓶颈?
据我们的调研和实践经验:
1、两种文件格式,两种世界
-
:基于Office Open XML (OOXML) 标准,本质是一个ZIP压缩包,内部包含描述文档结构的XML文件。表格的合并信息(如.docx格式gridSpan、vMerge)在XML中有明确定义,解析相对规范
。 -
:是微软私有的二进制格式,内部结构复杂、缺乏公开的完整文档。通过POI的.doc格式HWPFDocument模块进行解析时,获取到的表格信息非常原始,几乎不直接提供合并单元格的完整信息
。
2、传统工具的局限
- 大多数转换工具在处理
.doc格式时,无法准确还原rowspan和colspan - 它们通常会把合并单元格下的空单元格渲染成独立的
<td>,导致表格"散架" - 为了绕过难题,一些方案采取"扁平化"策略,即复制合并单元格的内容来填充所有被合并的单元格,但这破坏了表格的原始结构
3、企业现状
- 90%的企业仍然有大量的Word格式需要导入企业AI知识库,特别是金融、政府领域的客户对于doc老文件格式的诉求。
传统解析方案的表格准确率
普遍较低,特别是在处理合并单元格时表格信息的丢失或错误
直接导致企业AI知识库系统对业务关键信息的理解偏差,导致大模型回答准确度大大降低现有开源工具
要么功能简陋,要么商业化程度高,开发者缺乏可控的解决方案
三、企业AI知识库的诉求
对于做企业AI知识库的服务商而言,Word的解析是一个全面综合去考虑分析的一个问题。对于我们而言,我们考虑的主要方向包括:
1、解析格式需要支持doc\docx两种格式
我知道现有的很多开源工具、商业产品在处理Word格式上,对于解析doc格式都倍感恼火。感觉这么一个上世纪微软留下的产物,让开发者恨的牙痒痒,不亚于10年前开发者去解决IE6的各种兼容性问题。然而在我们的客户里面,特别是金融、政府领域的客户,依然存在着大量的老的doc的格式文件,这些文件依然是企业的数字资产,在AI时代,都需要坐上这趟高速列车,把数据装载进入企业AI知识库里面,发挥知识的价值。
2、Word文档能够解析提取成Markdown格式,提取的元素包括:(文档Header、表格、图片)
企业AI知识库最关心的是“知识的结构化”。解析文档的目标不只是转换文本,更是为了“识别并提取有价值的知识结构”。因此:
- 文档头信息(如标题、章节、层级结构)需准确提取并转化为 Markdown 标题(
#、##等); - 段落、列表、加粗/斜体等格式也应保留,确保语义清晰、上下文连贯;
- 引用和脚注等内容建议标准化处理,支持企业在QA和文档搜索场景中进行深度挖掘。
3、表格的内容需要用Html呈现,解决合并(rowspan/colspan)单元格的问题
Markdown 表格天生不支持合并单元格(rowspan/colspan),而这正是企业文档中极为常见的复杂表格结构(如绩效考核表、组织结构、流程图表等):
- 采用 HTML 格式解析表格内容,能完整保留表格的合并信息;
- 这样在知识回显、检索结果展示以及大模型上下文学习时,能确保原貌还原;
- 可为后续编辑器的“所见即所得”功能打下良好基础。
TorchV AIS企业AI知识库,提供了强大的富文本编辑器,对于Word的格式内容,对于表格内容就需要解析成标准的Html格式进行展现,丰富企业的知识二次加工创作。
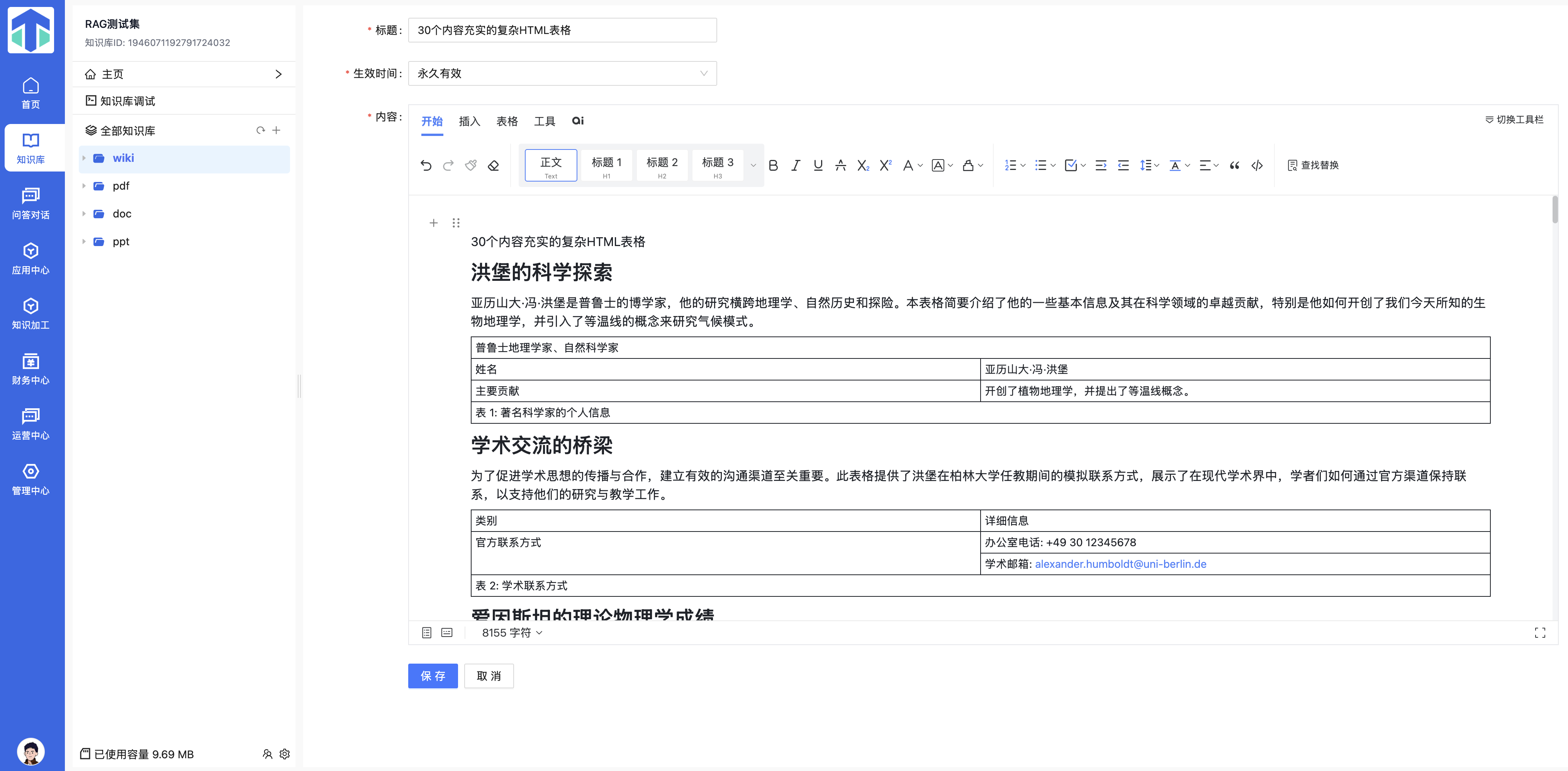
4、图片正确提取,并且图片的和文档内容上下位置正确。
Word 中的图文混排结构(例如图解流程、插图说明等)是许多专业知识文档的重要组成:
- 图片应
以URL链接
保留,确保知识库中可以复现图文内容; - 同时还要
保持图片在文档中的原始顺序和上下文位置
,不能打乱段落与图片的对应关系; - 若有 Alt 文本或说明文字,也需提取出来作为附加语义数据。
- 必要情况下可以灵活利用外部工具(OCR/多模态等)对图片进行深度理解,能够扩展当前的图片语义,提升问答精准度
5、性能以及成本考虑
不同企业对解析能力的投入存在差异,因此服务端需提供灵活选择:
- GPU/CPU的双重选择,有钱的可以无脑上GPU模型版本,驱动解析Word文档。
- 解析的性能效率,高效转换以及向量嵌入的转化。在不同的成本下的考虑以及解析的效果综合评估
四、TorchV技术实现路径:"预处理+注入"策略
TorchV目前采用
Java
语言开发,在底层技术栈上,对于Word的解析,目前恰好有2个非常好的开源软件可以利用:- Apache Tika:提供了多种文档解析的统一封装,开发者无需关心底层的细节,只需要统一调用就可以。
- Apache POI:能够处理Office套件的文件解析,包括doc、docx格式的解析。
虽然在底层技术支持上,这2个组件已经可以做的非常好了,但是对于上面我们第二点(企业AI知识库)的诉求,我们还是需要手工干预一下,才能解析得到我们想要的结果。
1、这2个工具在表格的处理、图片的处理提取上面,
默认的策略
都不太能满足我们的诉求,因此需要做更深层次的定制改动。2、我们依赖上面这两个组件做优化,这2个组件在CPU环境下能够快速的解析处理,所依赖的服务资源非常少的
1. FileMagic:差异化处理策略
对于doc/docx,我们需要从底层做差异处理,两种格式是完全不一样的解析策略,
针对不同格式采用不同的解析方案
:// 检测文件格式 FileMagic fileMagic = FileMagicUtils.checkMagic(wordFile); if (fileMagic == FileMagic.UNKNOWN) { String suffix = FileUtil.getSuffix(wordFile.getName()); if (StrUtil.equalsIgnoreCase(suffix, "docx")) { fileMagic = FileMagic.OOXML; } else if (StrUtil.equalsIgnoreCase(suffix, "doc")) { fileMagic = FileMagic.OLE2; } } log.info("检测到文件格式: {}, 文件: {}", fileMagic, wordFile.getAbsolutePath()); // 根据文件格式选择不同的处理方式 switch (fileMagic) { case OOXML -> { // DOCX 格式 - 使用自定义表格解析器 log.info("DOCX格式使用自定义表格解析器"); transfer = processDocxWithHtmlTable(wordFile, target); } case OLE2 -> { // DOC 格式 - 使用新的HTML表格支持 transfer = processDocWithHtmlTable(wordFile, target); } default -> { log.warn("不支持的文件格式: {}, 使用默认处理方式", fileMagic); // 回退到原始转换 target = toMarkdown(wordFile, pictures); transfer = true; } } 2. DOCX格式处理策略
核心思路
:利用DOCX格式的标准化特性,采用"预处理+替换"模式利用WordTableParser类,单独精准解析docx格式中的所有表格。然后在Tika处理完的Content内容上,做replace替换。
private static boolean processDocxWithHtmlTable(File docxFile, File target) { // 1. 预处理阶段:使用WordTableParser精准解析表格 XWPFDocument document = new XWPFDocument(inputStream); WordTableParser wordTableParser = new WordTableParser(); List<String> customTablesHtmlList = wordTableParser.parseToHtmlList(document); // 2. 常规解析:使用Tika进行流式解析 AutoDetectParser parser = new AutoDetectParser(); parser.parse(parseStream, textHandler, metadata, parseContext); // 3. 智能替换:用精准的表格HTML替换Tika的粗糙输出 String finalContent = replaceTablesWithCustomHtmlList(tikaContent, customTablesHtmlList); } 因为docx格式是相对标准的格式,POI在底层上给我们封装了非常强大的上层API供开发者调用,能够拿到docx中的所有table元素对象,这样让我们在处理表格合并时更方便。
public class WordTableParser { private final CellMergeAnalyzer cellMergeAnalyzer; private final HtmlTableBuilder htmlTableBuilder; public WordTableParser() { this.cellMergeAnalyzer = new CellMergeAnalyzer(); this.htmlTableBuilder = new HtmlTableBuilder(); } public WordTableParser(CellMergeAnalyzer cellMergeAnalyzer, HtmlTableBuilder htmlTableBuilder) { this.cellMergeAnalyzer = cellMergeAnalyzer; this.htmlTableBuilder = htmlTableBuilder; } /** * 解析 Word 文档中的所有表格为 HTML */ public String parseToHtml(XWPFDocument document) { // 拿到所有table List<XWPFTable> tables = document.getTables(); log.info("开始解析Word表格,共 {} 个表格", tables.size()); StringBuilder html = new StringBuilder(); for (int i = 0; i < tables.size(); i++) { XWPFTable table = tables.get(i); log.info("解析第 {} 个表格,包含 {} 行", i + 1, table.getRows().size()); html.append(parseTableToHtml(table)); if (i < tables.size() - 1) { html.append("<br/><br/>\n"); } } return html.toString(); } // more.... } 我们在处理docx格式时,抽象一个CellMergeAnalyzer的来处理表格合并的情况。
3. DOC格式处理策略
核心思路
:直接在解析过程中注入我们的表格处理逻辑扩写Tika下的Handler模块,单独处理doc格式的文件。
private static boolean processDocWithHtmlTable(File docFile, File target) { // 使用专门的DOC内容处理器 DocMarkdownWithHtmlTableContentHandler handler = new DocMarkdownWithHtmlTableContentHandler(); handler.setCurrentDocument(document); // 在解析过程中实时应用我们的表格算法 DocXMarkdownWithHtmlTableContentHandler textHandler = new DocXMarkdownWithHtmlTableContentHandler(handler, metadata); } doc格式和docx天然差异,可以算是一个新文件类型也不为过,对于表格的解析合并内容,会有明显的不同。
主要体现在提取的Table元素,并不能很好的获取单元格合并信息,需要有一套
通用的合并单元格识别算法
我们的在DocumentTableParser实现了
完全基于表格结构特征的通用算法
,不依赖任何具体内容:1. 数据结构构建
// 构建表格数据矩阵 String[][] cellContents = new String[numRows][]; int[] rowCellCounts = new int[numRows]; 2. 列合并检测算法
private static int detectColspanByStructure(int rowIndex, int cellIndex, String[][] cellContents, int[] rowCellCounts, int maxCols) { int currentRowCells = rowCellCounts[rowIndex]; // 如果当前行只有1个单元格,占满整行 if (currentRowCells == 1) { return maxCols; } // 智能分配列数 int averageColspan = maxCols / currentRowCells; int remainingCols = maxCols % currentRowCells; // 最后一个单元格处理剩余空间 if (cellIndex == currentRowCells - 1 && remainingCols > 0) { return averageColspan + remainingCols; } return averageColspan > 0 ? averageColspan : 1; } 3. 行合并检测算法
private static int detectRowspanByStructure(int rowIndex, int cellIndex, String cellText, String[][] cellContents, int[] rowCellCounts) { // 检查向下相邻行的对应位置 int rowspan = 1; for (int nextRow = rowIndex + 1; nextRow < cellContents.length; nextRow++) { String nextCellText = cellContents[nextRow][cellIndex]; if (nextCellText.trim().isEmpty()) { // 进一步验证:检查该行是否有其他内容 boolean hasContentInRow = false; for (int i = 0; i < rowCellCounts[nextRow]; i++) { if (!cellContents[nextRow][i].trim().isEmpty()) { hasContentInRow = true; break; } } if (hasContentInRow) { rowspan++; } else { break; // 整行为空,不是rowspan } } else { break; // 遇到非空单元格,rowspan结束 } } return rowspan; } 4. 智能跳过算法
private static boolean shouldSkipCellByStructure(int rowIndex, int cellIndex, String cellText, String[][] cellContents, int[] rowCellCounts) { // 向上查找可能的rowspan源 for (int prevRow = rowIndex - 1; prevRow >= 0; prevRow--) { if (cellIndex < rowCellCounts[prevRow]) { String prevCellText = cellContents[prevRow][cellIndex]; if (!prevCellText.trim().isEmpty()) { // 重新计算该单元格的rowspan int calculatedRowspan = calculateRowspanFromPosition( prevRow, cellIndex, cellContents, rowCellCounts); // 判断是否覆盖到当前行 if (prevRow + calculatedRowspan > rowIndex) { return true; // 跳过被占用的单元格 } } } } return false; } 五、解析效果验证
我让大语言模型帮我创建了30种不同格式的复杂表格类型,包括上下单元格合并、跨页表格、左右单元格合并等多种复杂的情况,验证了doc/docx两种格式。主要表现如下:
- ✅ 完美识别
rowspan和colspan合并单元格 - ✅ 准确保留所有表格内容,无丢失现象
- ✅ 正确处理跨页表格和复杂嵌套结构
- ✅ 支持任意语言和字符集的表格内容
- ✅ 在.doc和.docx格式上表现一致(目前doc格式无法提取markdown的header标题)
- ✅ 正确提取图片以及图片位置正确
在31个复杂表格情况下,对于表格的合并情况:
-
✅ 数据无错误,表格内容没错误的情况比例:30/31=96.8%
包含数据完全正确,目前出现6个表格会出现数据没异常的情况,但是表格在纵向合并的情况并没有表现一致的情况
-
✅ 数据解析异常,错误比率:1/31=3.23%
在31个复杂表格数据的情况下,出现了解析还原错误的情况,表格数据错位了的情况,这种情况在做知识库场景下送给大模型时,会导致数据异常、回答幻觉的情况发生
-
✅ 表格完全正确,colspan/rowspan完全无错误的情况:25/31=80.6%
数据完全一致、表格完全一致,100%还原出来的比例。
1、简单的上下合并情况
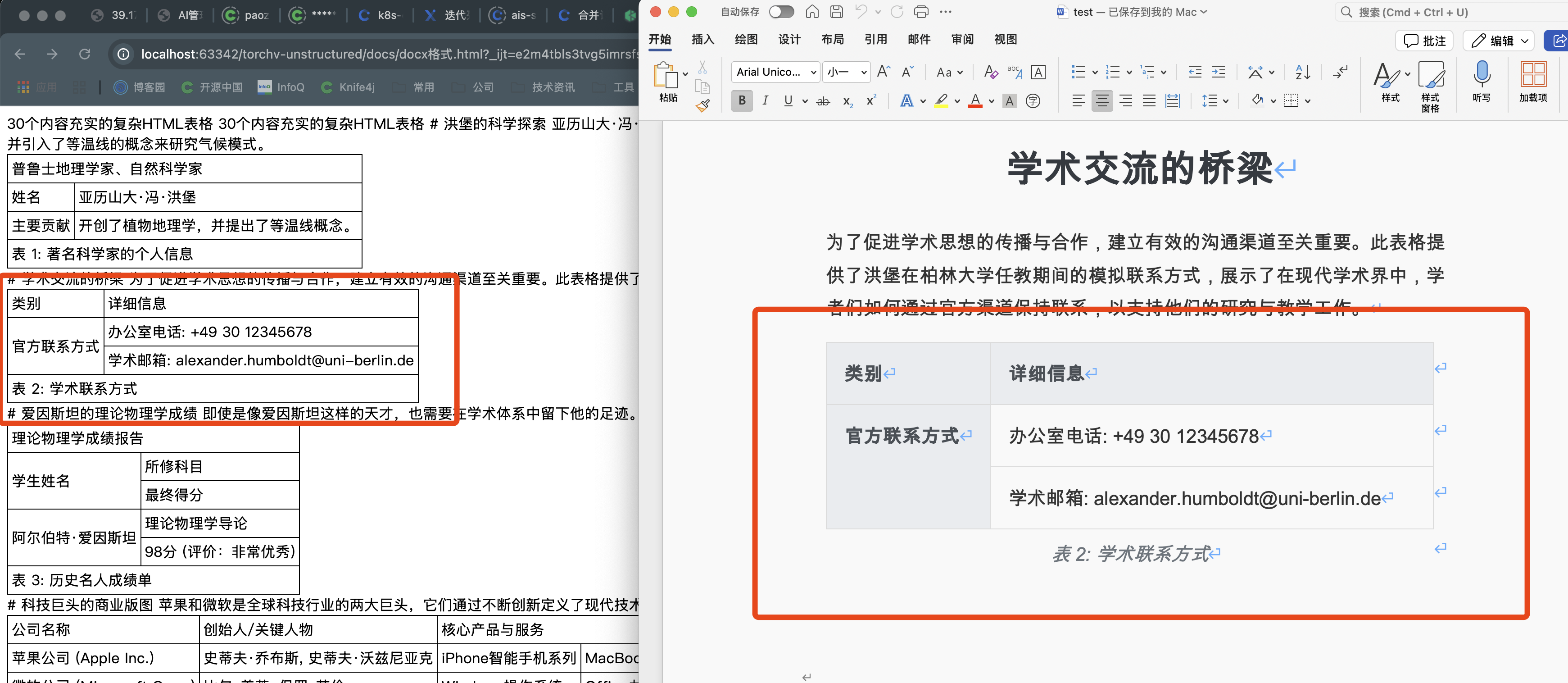
2、跨页上下单元格合并单元格的情况
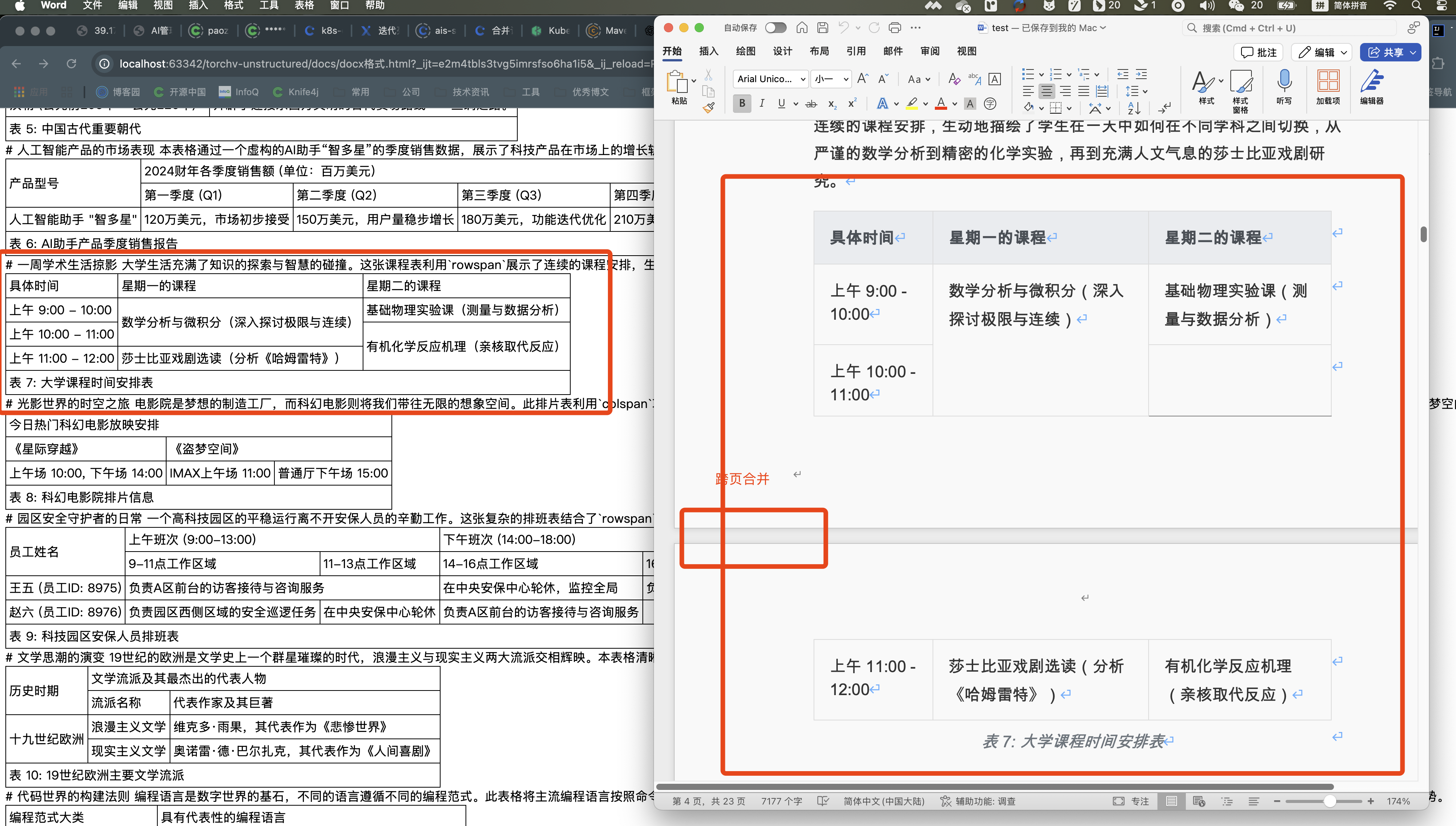
3、上下左右单元格合并的情况

4、翻页单元格上下左右合并的情况

5、更复杂的纵向横向表格合并情况

六、100%开源
TorchV 的企业级 AI 知识库系统,是在开源生态的基础上构建而成的。从创业初期开始,我们便充分受益于业界开源的各种大语言模型、Embedding 模型、Reranker 模型、开源组件/中间件等,这些技术的开放极大地推动了行业的发展。我们深知开源的价值,也始终秉持开放、共享、共建的理念。
在构建开发产品的过程中,特别是在 Word 文档解析这一关键环节,我们团队进行了深入的研究和持续的优化,并在实践中取得了一些突破。尽管当前的解析组件仍存在一些待完善之处,或在测试覆盖面上尚有不足,通过开源的形式开放出来,希望借此与更多开发者携手,共同完善这一能力模块,推动行业工具链的进步。
我们诚挚欢迎社区开发者参与共建,一起打磨这项通用而关键的能力。
GitHub:https://github.com/torchv/torchv-unstructured
Gitee: https://gitee.com/torchv/torchv-unstructured
该仓库是一个Java项目,1.0.0版本已经推送Maven中央仓库,坐标地址:
<dependency> <groupId>com.torchv.infra</groupId> <artifactId>torchv-unstructured</artifactId> <version>1.0.0</version> </dependency> 













这一切,似未曾拥有