Stable diffusion环境部署搭建
1、安装Nvidia驱动、cuda版本等
略
2、安装anaconda环境
略
3、安装git
#git工具的安装参考下面命令 apt-get update -y a pt-get upgrade -y apt install git4、下载源码和模型参数文件
#1、下载源码 git clone https://github.com/CompVis/stable-diffusion.git #2、下载模型参数文件,以下示例为v1.4版本,大约7GB wget https://xujianhua-bj.tos-cn-beijing.volces.com/sd-v1-4-full-ema.ckpt #3、设置模型参数存放位置 #git下来的stable-diffusion文件夹路径中创建stable-diffusion-v1目录 mkdir -p /root/stable-diffusion/models/ldm/stable-diffusion-v1/ #将下载的模型参数文件改名为 model.ckpt 并放在 stable-diffusion-v1 目录下 ln -s /root/sd-v1-4-full-ema.ckpt /root/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt 5、Anaconda创建 ldm 虚拟环境
#切换清华源,便于后续生成环境,下载python包 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple//注意:火山引擎FT的只开github的加速,不开http/https代理。因为设置http/https代理, 执行conda env create -f environment.yaml会报错。
#进入之前的源码解压目录 cd stable-diffusion conda env create -f environment.yaml conda activate ldm#environment.yaml的内容 name: ldm channels: - pytorch - defaults dependencies: - python=3.8.5 - pip=20.3 - cudatoolkit=11.3 - pytorch=1.11.0 - torchvision=0.12.0 - numpy=1.19.2 - pip: - albumentations==0.4.3 - diffusers - opencv-python==4.1.2.30 - pudb==2019.2 - invisible-watermark - imageio==2.9.0 - imageio-ffmpeg==0.4.2 - pytorch-lightning==1.4.2 - omegaconf==2.1.1 - test-tube>=0.7.5 - streamlit>=0.73.1 - einops==0.3.0 - torch-fidelity==0.3.0 - transformers==4.19.2 - torchmetrics==0.6.0 - kornia==0.6 - -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers - -e git+https://github.com/openai/CLIP.git@main#egg=clip - -e . #pip install -e git+https://github.com/openai/CLIP.git@main#egg=clip #pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers #pip install -e. #因为环境无法稳定访问github,导致相关包安装失败 #建议执行虚拟环境创建前,开启FT的github加速。6、文生图
python scripts/txt2img.py --prompt "egg in the pocket" --plms --n_samples 2 #因为环境无法稳定访问github,导致相关包安装失败, #执行scripts/txt2img.py过程会报无数次 ModuleNotFoundError: No module named XX的错误 #解决办法:pip install 对应的模块名称,解决不了google #1、最后pip install方式因为版本不对,跑.py还是会失败,所以建议开通FT,能够访问境外网站和github,避免因为版本不对,因为造成无法使用问题 #2、即便开了github的网际快车,还是会遇到报错的问题,需要再开始FT的Http/https的代理。 #都设置后,还会出现包未安装的现象,执行如下命令进行安装。 #apt-get install libsm6 #apt-get install -y libxrender-dev #生成的文件在:/root/stable-diffusion/outputs/txt2img-samples/samples/
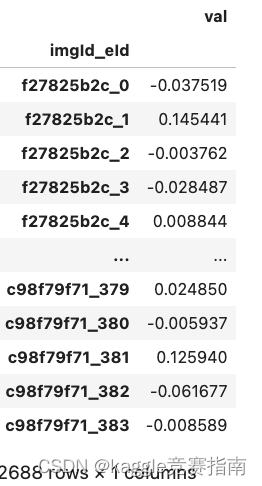 # Baseline Stable Diffusion ViT Baseline Train ### Library ```python import os import random import numpy as np import pandas as pd from PIL import Image from tqdm.notebook import tqdm from scipy import spatial from sklearn.model_selection import train_test_split import torch from torch import nn from torch.utils.data import Dataset, DataLoader from torch.optim.lr_scheduler import CosineAnnealingLR from torchvision import transforms import timm from timm.utils import AverageMeter import sys sys.path.append('../input/sentence-transformers-222/sentence-transformers') from sentence_transformers import SentenceTransformer import warnings warnings.filterwarnings('ignore') </code></pre> <h3> Config</h3> <pre><code >class CFG: model_name = 'vit_base_patch16_224' input_size = 224 batch_size = 64 num_epochs = 3 lr = 1e-4 seed = 42 </code></pre> <h3> seed</h3> <pre><code >def seed_everything(seed): os.environ['PYTHONHASHSEED'] = str(seed) random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True seed_everything(CFG.seed) </code></pre> <h3> Dataset</h3> <pre><code >class DiffusionDataset(Dataset): def __init__(self, df, transform): self.df = df #图像增强 self.transform = transform def __len__(self): return len(self.df) def __getitem__(self, idx): row = self.df.iloc[idx] #打开图片 image = Image.open(row['filepath']) #图像增强 image = self.transform(image) #标签 prompt = row['prompt'] return image, prompt class DiffusionCollator: def __init__(self): self.st_model = SentenceTransformer( '/kaggle/input/sentence-transformers-222/all-MiniLM-L6-v2', device='cpu' ) def __call__(self, batch): images, prompts = zip(*batch) images = torch.stack(images) prompt_embeddings = self.st_model.encode( prompts, show_progress_bar=False, convert_to_tensor=True ) return images, prompt_embeddings def get_dataloaders(trn_df,val_df,input_size,batch_size): #图像增强设置 transform = transforms.Compose([ transforms.Resize(input_size), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ]) #dataset trn_dataset = DiffusionDataset(trn_df, transform) val_dataset = DiffusionDataset(val_df, transform) collator = DiffusionCollator() #dataloader dataloaders = {} dataloaders['train'] = DataLoader( dataset=trn_dataset, shuffle=True, batch_size=batch_size, pin_memory=True, num_workers=2, drop_last=True, collate_fn=collator ) dataloaders['val'] = DataLoader( dataset=val_dataset, shuffle=False, batch_size=batch_size, pin_memory=True, num_workers=2, drop_last=False, collate_fn=collator ) return dataloaders </code></pre> <h3> Train</h3> <pre><code >#评价指标 def cosine_similarity(y_trues, y_preds): return np.mean([ 1 - spatial.distance.cosine(y_true, y_pred) for y_true, y_pred in zip(y_trues, y_preds) ]) </code></pre> <h2> Train</h2> <pre><code >def train(trn_df,val_df,model_name,input_size,batch_size,num_epochs,lr ): #设置运行环境 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #dataloader dataloaders = get_dataloaders(trn_df,val_df,input_size,batch_size) #创建模型 model = timm.create_model( model_name, pretrained=True, num_classes=384#给定的词表长度为384 ) #梯度检查点,可以降低显存使用 model.set_grad_checkpointing() #模型迁移到GPU上 model.to(device) #优化器 optimizer = torch.optim.AdamW(model.parameters(), lr=lr) #周期计算,用于CosineAnnealingLR ttl_iters = num_epochs * len(dataloaders['train']) #学习率调整策略 scheduler = CosineAnnealingLR(optimizer, T_max=ttl_iters, eta_min=1e-6)#eta_min.为最小的学习率 #评价指标 criterion = nn.CosineEmbeddingLoss() best_score = -1.0 for epoch in range(num_epochs): train_meters = { 'loss': AverageMeter(), 'cos': AverageMeter(), } #模型设置为训练模式 model.train() for X, y in tqdm(dataloaders['train'], leave=False): X, y = X.to(device), y.to(device) #梯度清零 optimizer.zero_grad() X_out = model(X) target = torch.ones(X.size(0)).to(device) #计算损失 loss = criterion(X_out, y, target) #反向传播 loss.backward() #更新 optimizer.step() scheduler.step() trn_loss = loss.item() trn_cos = cosine_similarity( X_out.detach().cpu().numpy(), y.detach().cpu().numpy() ) train_meters['loss'].update(trn_loss, n=X.size(0)) train_meters['cos'].update(trn_cos, n=X.size(0)) print('Epoch {:d} / trn/loss={:.4f}, trn/cos={:.4f}'.format( epoch + 1, train_meters['loss'].avg, train_meters['cos'].avg)) val_meters = { 'loss': AverageMeter(), 'cos': AverageMeter(), } model.eval() for X, y in tqdm(dataloaders['val'], leave=False): X, y = X.to(device), y.to(device) with torch.no_grad(): X_out = model(X) target = torch.ones(X.size(0)).to(device) loss = criterion(X_out, y, target) val_loss = loss.item() val_cos = cosine_similarity( X_out.detach().cpu().numpy(), y.detach().cpu().numpy() ) val_meters['loss'].update(val_loss, n=X.size(0)) val_meters['cos'].update(val_cos, n=X.size(0)) print('Epoch {:d} / val/loss={:.4f}, val/cos={:.4f}'.format( epoch + 1, val_meters['loss'].avg, val_meters['cos'].avg)) if val_meters['cos'].avg > best_score: best_score = val_meters['cos'].avg torch.save(model.state_dict(), f'{model_name}.pth') </code></pre> <h2> 准备训练数据</h2> <pre><code >df = pd.read_csv('/kaggle/input/diffusiondb-data-cleansing/diffusiondb.csv') trn_df, val_df = train_test_split(df, test_size=0.1, random_state=CFG.seed) </code></pre> <h2> 训练</h2> <pre><code >train(trn_df, val_df, CFG.model_name, CFG.input_size, CFG.batch_size, CFG.num_epochs, CFG.lr) </code></pre> <h2> 模型推理</h2> <pre><code >import numpy as np import pandas as pd from pathlib import Path from PIL import Image from tqdm.notebook import tqdm import torch from torch.utils.data import Dataset, DataLoader from torchvision import transforms import timm </code></pre> <pre><code >class CFG: model_path = '/kaggle/input/stable-diffusion-vit-baseline-train/vit_base_patch16_224.pth' model_name = 'vit_base_patch16_224' input_size = 224 batch_size = 64 </code></pre> <h2> dataset</h2> <pre><code >class DiffusionTestDataset(Dataset): def __init__(self, images, transform): self.images = images self.transform = transform def __len__(self): return len(self.images) def __getitem__(self, idx): image = Image.open(self.images[idx]) image = self.transform(image) return image </code></pre> <h2> inference</h2> <pre><code >def predict( images, model_path, model_name, input_size, batch_size ): device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') transform = transforms.Compose([ transforms.Resize(input_size), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ]) dataset = DiffusionTestDataset(images, transform) dataloader = DataLoader( dataset=dataset, shuffle=False, batch_size=batch_size, pin_memory=True, num_workers=2, drop_last=False ) model = timm.create_model( model_name, pretrained=False, num_classes=384 ) state_dict = torch.load(model_path) model.load_state_dict(state_dict) model.to(device) model.eval() preds = [] for X in tqdm(dataloader, leave=False): X = X.to(device) with torch.no_grad(): X_out = model(X) preds.append(X_out.cpu().numpy()) return np.vstack(preds).flatten() </code></pre> <pre><code >images = list(Path('/kaggle/input/stable-diffusion-image-to-prompts/images').glob('*.png')) imgIds = [i.stem for i in images] EMBEDDING_LENGTH = 384 imgId_eId = [ '_'.join(map(str, i)) for i in zip( np.repeat(imgIds, EMBEDDING_LENGTH), np.tile(range(EMBEDDING_LENGTH), len(imgIds)))] prompt_embeddings = predict(images, CFG.model_path, CFG.model_name, CFG.input_size, CFG.batch_size) submission = pd.DataFrame( index=imgId_eId, data=prompt_embeddings, columns=['val'] ).rename_axis('imgId_eId') submission.to_csv('submission.csv')