
如何用labelimg标注yolo数据集,并利用工具自动划分数据集
视频演示
如何用labelimg标注yolo数据集,并利用工具自动划分数据集_哔哩哔哩_bilibili
1 labelimg标注数据集
1.1 labelimg工具介绍
LabelImg是一款开源的图像标注工具,专门用于为目标检测任务创建数据集。它支持矩形框标注,可导出PASCAL VOC、YOLO、CreateML等多种格式。
通过简单的点击和拖拽操作,用户即可快速为图像中的对象添加标注框和类别标签。
该工具界面简洁直观,支持快捷键操作,大幅提升标注效率,是计算机视觉领域数据准备的常用工具之一。

1.2 labelimg标注数据集
点击界面左侧的“Open Dir”按钮,选择数据集所存放的文件夹,选择后文件夹中存放的图片信息会展示到界面上
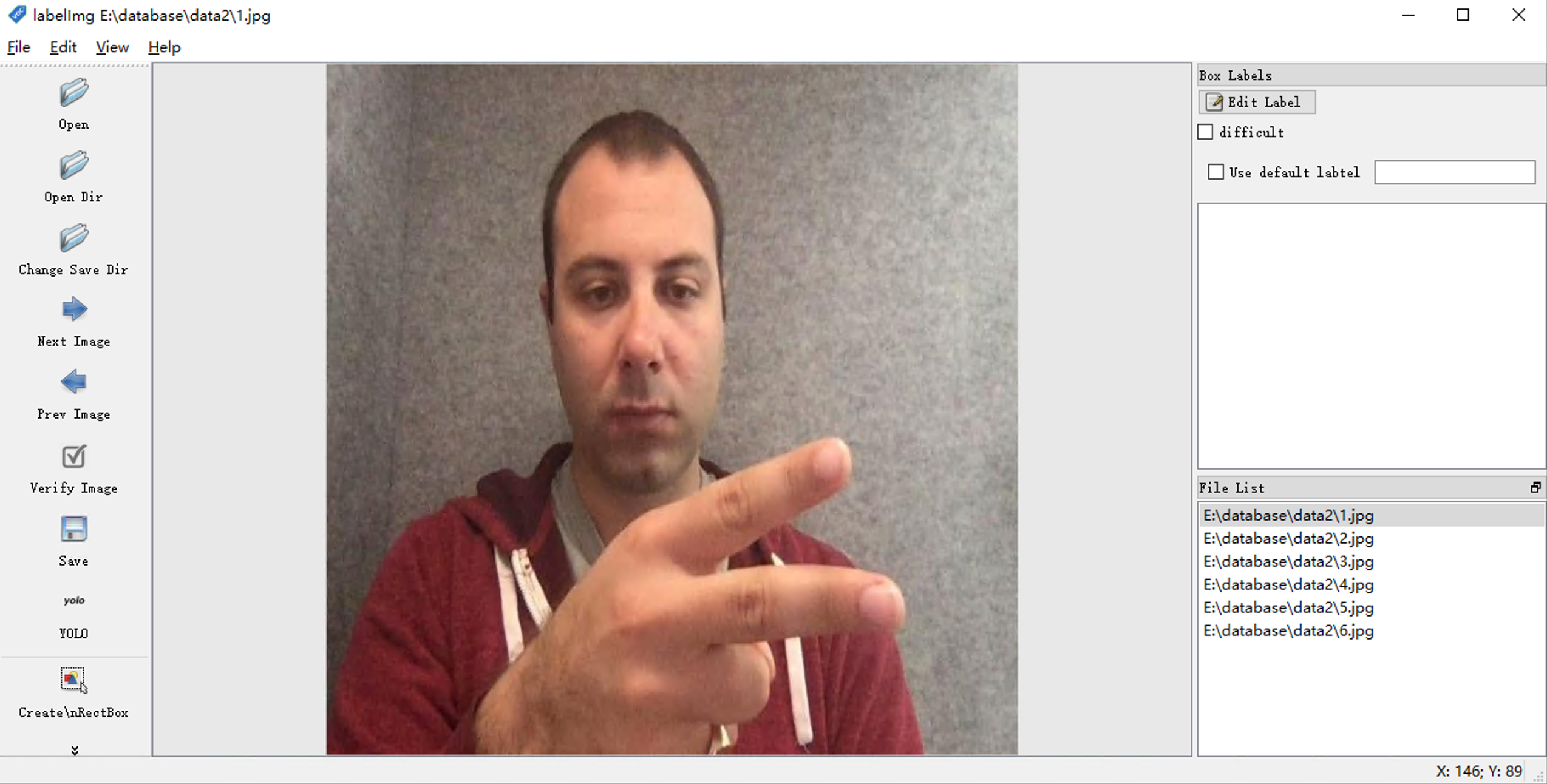
左下角的File List会显示读取进来的数据集列表
点击左侧的Create \nRectBox 按钮,长按鼠标左键可以对图像中的目标物体绘制矩形框
绘制完成之后,弹出来的命名对话框中,写上当前绘制的类别的名字,这里绘制的这个手势是剪刀,我们命名为“Scissors”
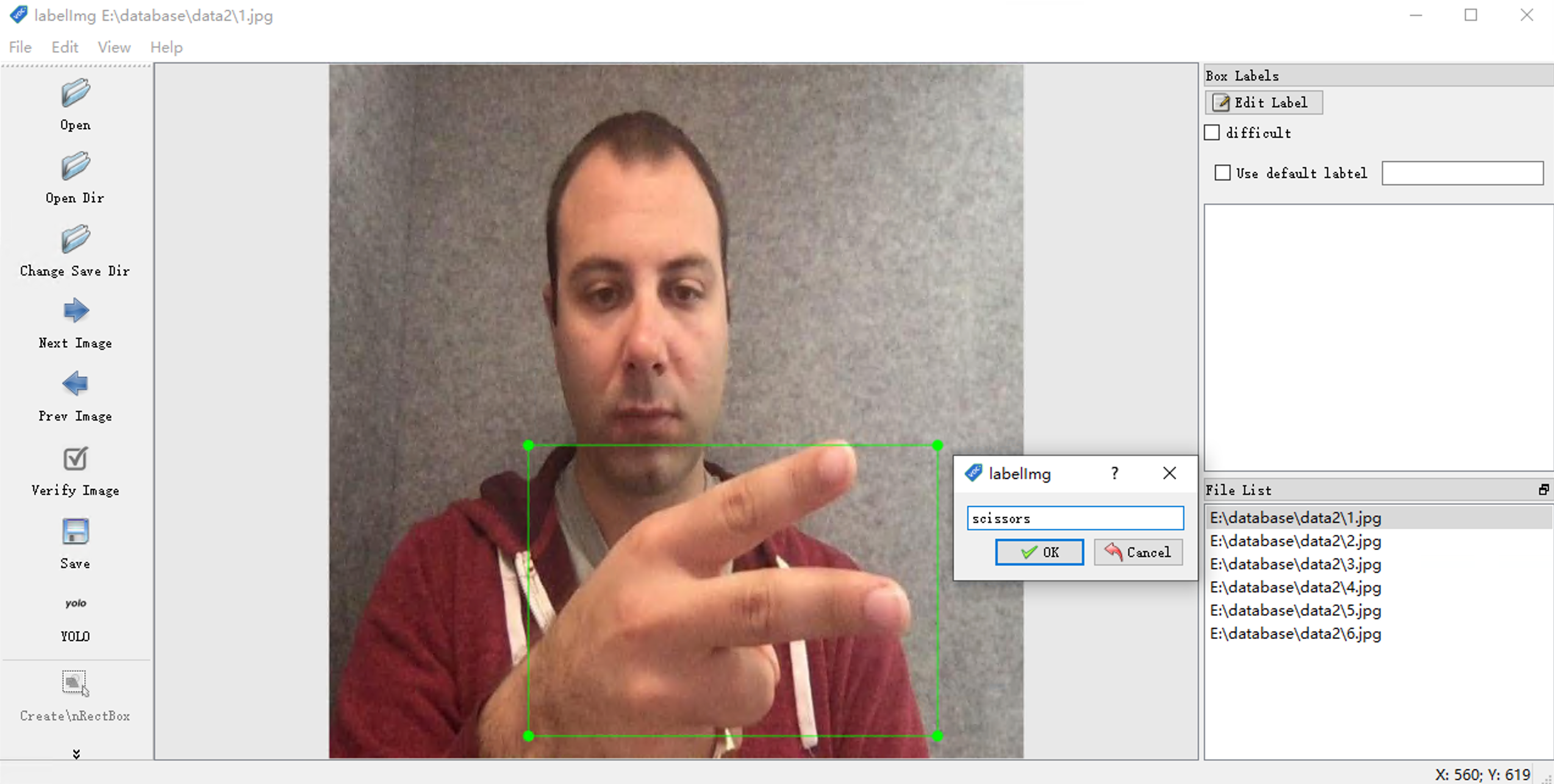
依次对剩下的图像数据集进行绘制标注。
查看存放图片的文件夹,会发现每一个图片的旁边,都生成了一个同名的txt文档,这个文档就是我们标注数据后产生的标注文件。
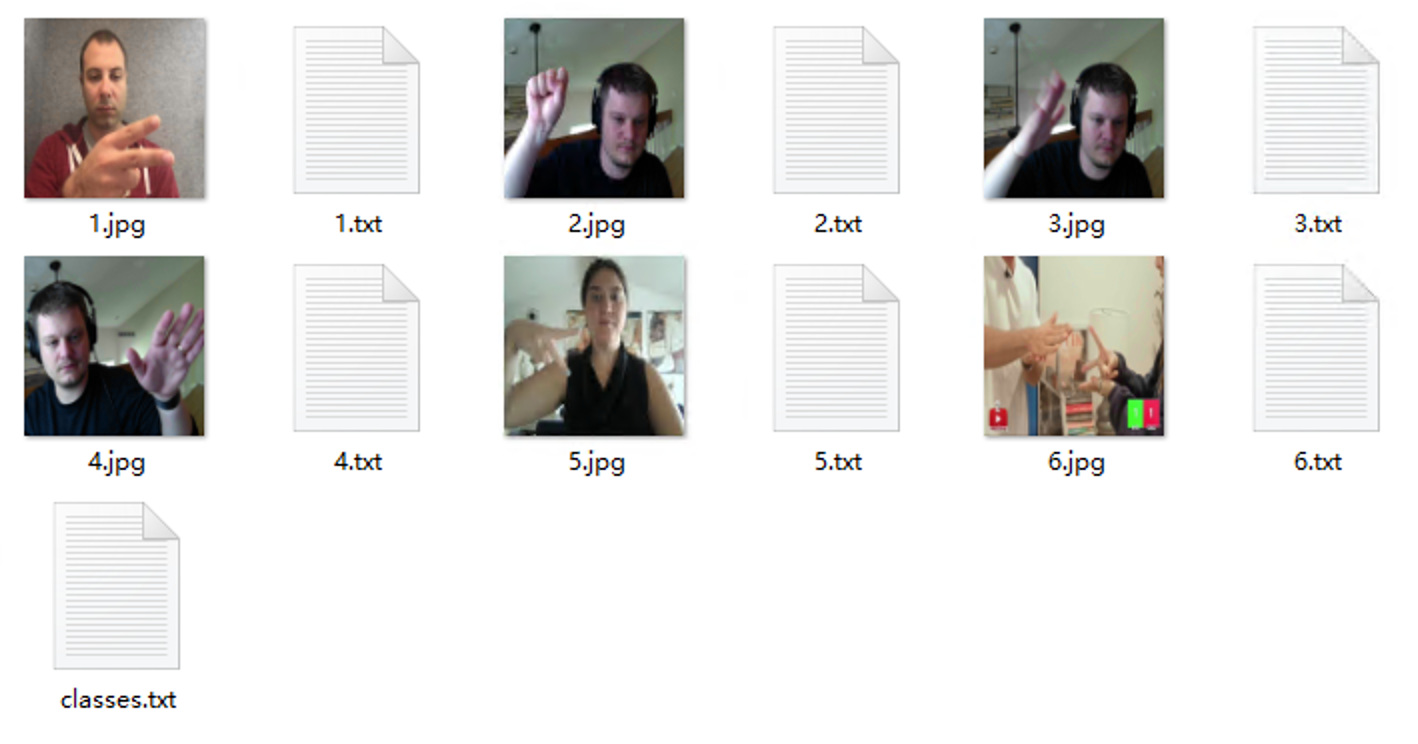
这里可以打开标注文件,查看下标注文件中的内容:
0 0.560937 0.768750 0.625000 0.425000
标注文件中的内容按照行排列,每一行有5个数字,第1个数字是一个整数,后面4个数字是0到1之间的小数,这里以上图举例,说明下数字的含义:
第1个数字“0”:表示当前目标物体的类别编号,0表示第0号目标物体,同理如果是2的话,表明第2号目标物体,具体的编号根据标注时编写目标物体的名称的先后顺序而来。
第2、3个数字“0.560937 0.768750”:表示的是标注物体的坐标信息,分别是x轴和y轴的坐标,坐标为目标检测物体的中心区域,坐标原点是图像的左上角,这里不一样的地方是,坐标轴长不是按照图像的实际尺寸来标注的,而是做了归一化处理,即左下角的y轴坐标是1,右上角的x轴坐标是1,所以x轴和y轴的坐标的阈值是0到1之间。
第4、5数字"0.625000 0.425000":表示的是标注物体的尺寸,分别表示宽度和高度,数值同样是归一化处理,例如0.625表示尺寸为宽度的62.5%
最后还有一个classes.txt文件,打开后是标注的名字信息
scissors rock paper
2 划分数据集
当标注完数据之后,yolo模型训练的时候,数据集需要区分训练集和验证集,最后为了检测模型的有效性,我们还需要测试集
所以这里又写了一个python脚本可以将我们标注好的数据集一次性随机性的按照设定的划分比例进行自动化数据集划分
# YOLO 数据集划分工具 # 功能:将包含图片和对应标注文件的数据集按比例随机划分为训练集、验证集和测试集 # 同时生成YOLO训练所需的dataset.yaml配置文件 import os import shutil import random import yaml # ============ 配置参数 ============ SOURCE_DIR = "data" # 源数据目录,图片及其标注 .txt 文件应在此目录 OUTPUT_DIR = "data_split_output2" # 输出根目录,将生成 train/val/test 及其 images/labels TRAIN_RATIO = 0.7 # 训练集比例 VAL_RATIO = 0.2 # 验证集比例 TEST_RATIO = 0.1 # 测试集比例 SEED = 42 # 随机种子,确保每次划分结果一致 REQUIRE_LABEL = True # 仅包含存在对应 .txt 标注的图片 IMG_EXTS = {'.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff'} # 支持的图片格式 # ========================================== def ensure_dir(path: str): """确保目录存在,不存在则创建""" os.makedirs(path, exist_ok=True) def main(): # 检查源目录是否存在 if not os.path.isdir(SOURCE_DIR): print(f"源目录不存在: {SOURCE_DIR}") return # 收集图片及对应标注信息 candidates = [] for fname in os.listdir(SOURCE_DIR): fpath = os.path.join(SOURCE_DIR, fname) # 跳过非文件项 if not os.path.isfile(fpath): continue # 检查文件是否为图片格式 ext = os.path.splitext(fname)[1].lower() if ext in IMG_EXTS: base = os.path.splitext(fname)[0] # 获取文件名(不含扩展名) label_name = base + ".txt" # 对应的标注文件名 label_path = os.path.join(SOURCE_DIR, label_name) # 如果需要标注文件且不存在,则跳过此图片 if REQUIRE_LABEL and not os.path.exists(label_path): continue # 记录图片文件名和对应的标注文件名(如果有) has_label = os.path.exists(label_path) candidates.append((fname, label_name if has_label else None)) n = len(candidates) if n == 0: print("未找到符合条件的图片及标注对。") return # 检查比例设置是否有效 ratio_sum = TRAIN_RATIO + VAL_RATIO + TEST_RATIO if ratio_sum <= 0: print("train/val/test 比例之和必须大于0") return # 设置随机种子并打乱数据顺序 random.seed(SEED) random.shuffle(candidates) # 计算各数据集的数量 n_train = int(n * (TRAIN_RATIO / ratio_sum)) n_val = int(n * (VAL_RATIO / ratio_sum)) n_test = n - n_train - n_val # 定义输出目录路径 train_img_out = os.path.join(OUTPUT_DIR, "train", "images") train_lab_out = os.path.join(OUTPUT_DIR, "train", "labels") val_img_out = os.path.join(OUTPUT_DIR, "val", "images") val_lab_out = os.path.join(OUTPUT_DIR, "val", "labels") test_img_out = os.path.join(OUTPUT_DIR, "test", "images") test_lab_out = os.path.join(OUTPUT_DIR, "test", "labels") # 创建所有输出目录 for d in [train_img_out, train_lab_out, val_img_out, val_lab_out, test_img_out, test_lab_out]: ensure_dir(d) def copy_pair(item, dst_img_dir, dst_lab_dir): """复制图片和对应的标注文件到目标目录""" img_name, label_name = item src_img = os.path.join(SOURCE_DIR, img_name) dst_img = os.path.join(dst_img_dir, img_name) shutil.copy2(src_img, dst_img) # 复制图片文件 # 如果存在标注文件,则一并复制 if label_name: src_lab = os.path.join(SOURCE_DIR, label_name) if os.path.exists(src_lab): dst_lab = os.path.join(dst_lab_dir, label_name) shutil.copy2(src_lab, dst_lab) # 复制标注文件 # 按划分结果复制文件到对应目录 idx = 0 for _ in range(n_train): copy_pair(candidates[idx], train_img_out, train_lab_out) idx += 1 for _ in range(n_val): copy_pair(candidates[idx], val_img_out, val_lab_out) idx += 1 for _ in range(n_test): copy_pair(candidates[idx], test_img_out, test_lab_out) idx += 1 # 读取类别信息 classes_file = os.path.join(SOURCE_DIR, 'classes.txt') class_names = [] if os.path.exists(classes_file): with open(classes_file, 'r', encoding='utf-8') as f: class_names = [line.strip() for line in f.readlines() if line.strip()] else: print(f"警告: 未找到 classes.txt 文件,使用默认类别") class_names = ['class0', 'class1', 'class2'] # 默认类别名 # 生成 YAML 配置文件 (手动控制顺序) yaml_path = os.path.join(OUTPUT_DIR, 'dataset.yaml') with open(yaml_path, 'w', encoding='utf-8') as f: # 写入数据集路径 f.write(f"train: ./train/images\n") f.write(f"val: ./val/images\n") f.write(f"test: ./test/images\n") f.write(f"\n") # 写入类别数量 f.write(f"nc: {len(class_names)}\n") # 写入类别名称列表 f.write(f"names:\n") for name in class_names: f.write(f"- {name}\n") # 输出划分结果摘要 print("划分完成:") print(f" 训练集: train/images={train_img_out}, train/labels={train_lab_out}, 张数={n_train}") print(f" 验证集: val/images={val_img_out}, val/labels={val_lab_out}, 张数={n_val}") print(f" 测试集: test/images={test_img_out}, test/labels={test_lab_out}, 张数={n_test}") print(f" 配置文件: {yaml_path}") if __name__ == "__main__": main() 代码中设置好对应的初始化参数: SOURCE_DIR = "data" # 源数据目录,图片及其标注 .txt 文件应在此目录 OUTPUT_DIR = "data_split_output2" # 输出根目录,将生成 train/val/test 及其 images/labels TRAIN_RATIO = 0.7 # 训练集比例 VAL_RATIO = 0.2 # 验证集比例 TEST_RATIO = 0.1 # 测试集比例 代码中都有相应的注释,这里不再赘述,主要是设置好数据集所在目录,输出的数据集的目录,各个数据集的比例
代码的核心思想就是读取文件夹下的所有图片,然后把图片存放到candidates的list中,然后使用random.shuffle方法打乱candidates中的数据。最后依次按照划分的比例读取数据集。
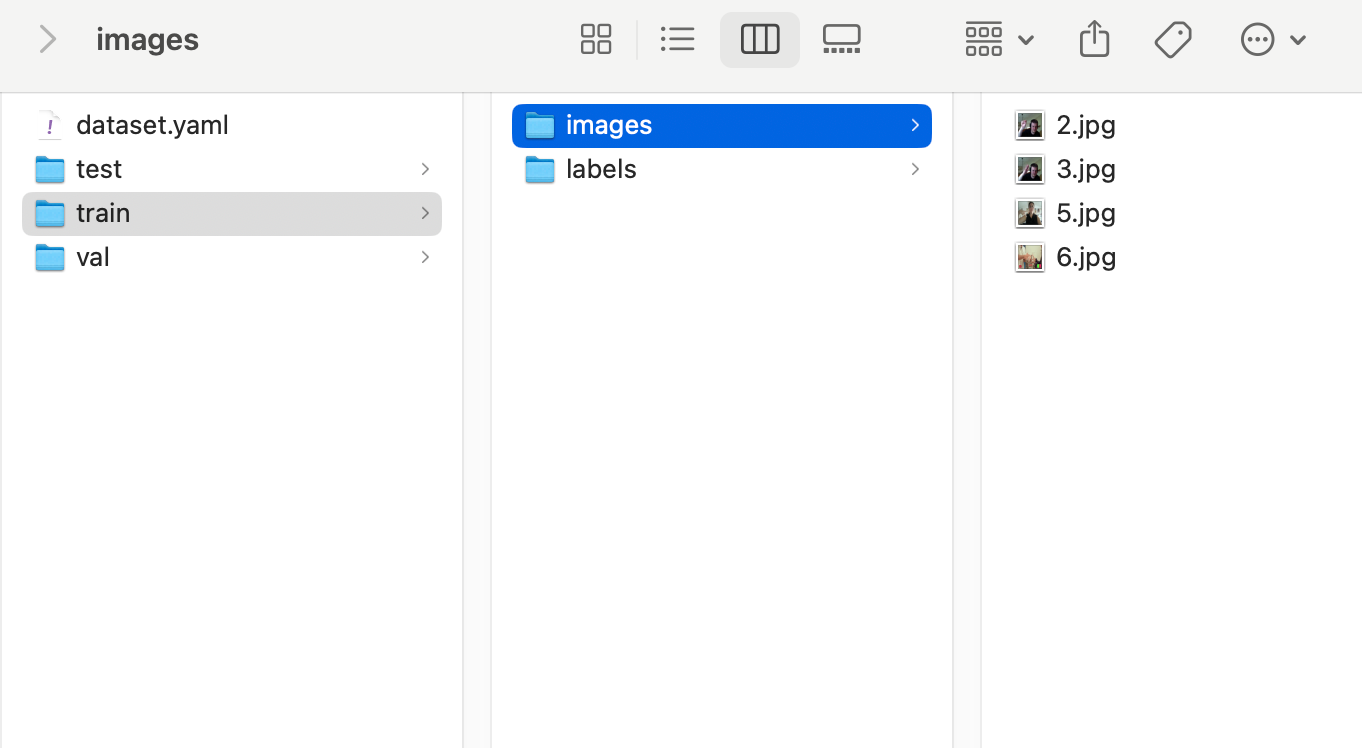
最终划分好的数据集如下(为了结构展现清楚,这里用macos下的目录展现形式)
同时还生成了yolo框架训练时需要用到的yaml数据集说明文件,这里名字命名为dataset.yaml,打开后内容如下
train: ./train/images val: ./val/images test: ./test/images nc: 3 names: - scissors - rock - paper
上面有数据集所在的目录,nc数,还有对应类别的名字
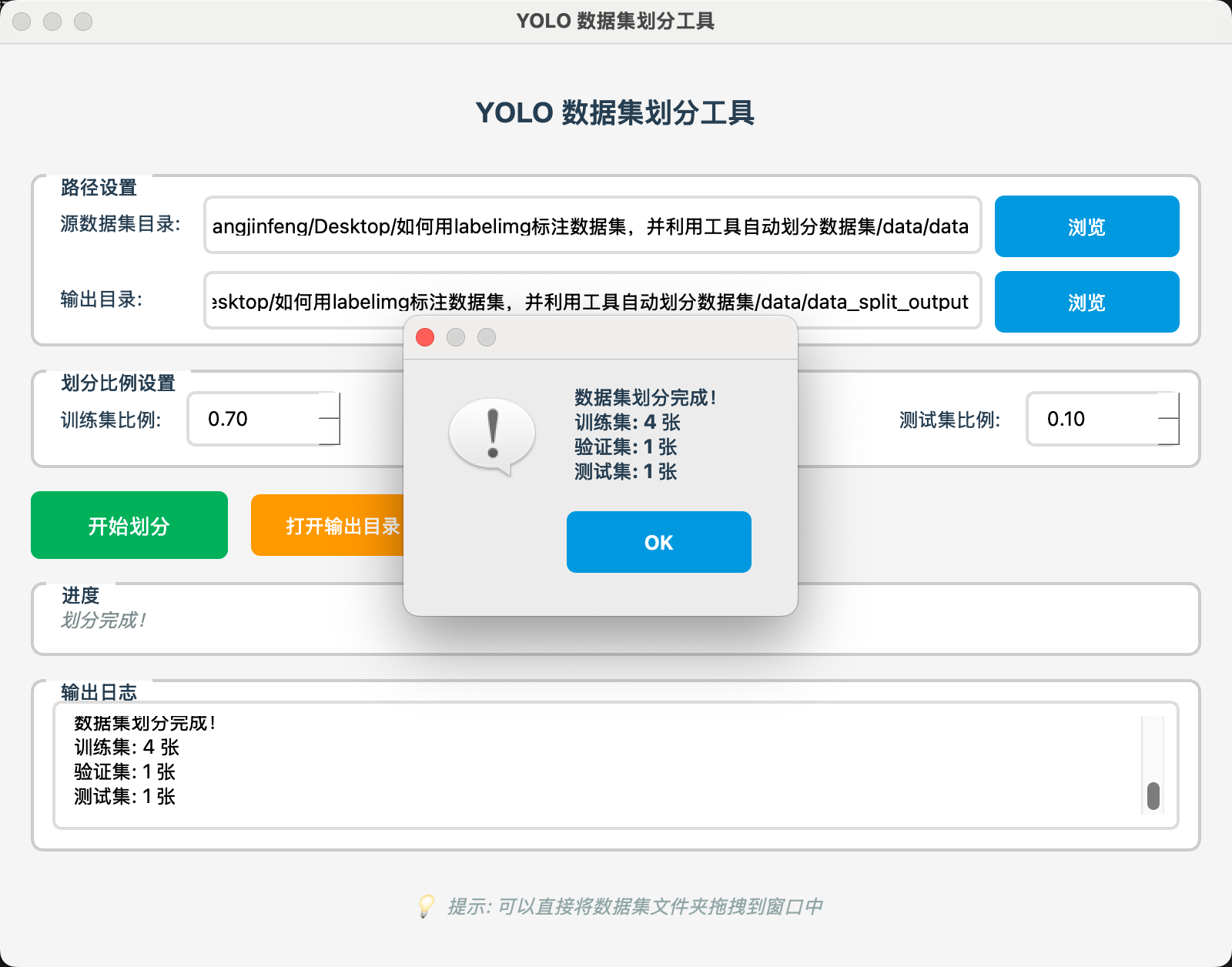
3 封装好GUI的划分数据集工具
利用pyqt5制作了一个界面,将python脚本集成进去,并打包成exe,方便标注数据集的小伙伴不用特意从python环境中去处理

有了界面之后,各个参数的设置就比较清楚了
可以设置源数据集所在的目录,也可以直接把数据集的文件夹拖动到界面上,自动把目录填入
设置输出目录,最终划分数据集后所保存的位置
设置不同数据集的划分比例,这里需要注意划分的比例之和不能超过1
点击开始划分按钮后,会有数据集划分的进度和日志信息,方便用户随时了解划分进度情况。
以上就是如何使用labelimg来标注数据集,然后如果通过脚本自动划分数据集,最终通过封装好gui来实现更进一步的数据集划分,中间细节难免有些疏漏,如有问题,可以评论区进行讨论。





评论